The HPLMIXED Procedure

REPEATED Statement
-
REPEATED repeated-effect </ options>;
The REPEATED statement specifies the 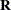 matrix in the mixed model. If no REPEATED statement is specified, is assumed to be equal to
matrix in the mixed model. If no REPEATED statement is specified, is assumed to be equal to  . For this release, you can use the REPEATED statement only with the BLUP
option. The statement is ignored when no BLUP option is specified.
. For this release, you can use the REPEATED statement only with the BLUP
option. The statement is ignored when no BLUP option is specified.
The repeated-effect is required, because the order of the input data is not necessarily reproducible in a distributed environment. The repeated-effect must contain only classification variables. Make sure that the levels of the repeated-effect are different for each observation within a subject; otherwise, PROC HPLMIXED constructs identical rows in that correspond to the observations with the same level. This results in a singular matrix and an infinite likelihood.
Table 53.8 summarizes important options in the REPEATED statement. All options are subsequently discussed in alphabetical order.
Table 53.8: Summary of Important REPEATED Statement Options
You can specify the following options in the REPEATED statement after a slash (/).
-
SUBJECT=effect
SUB=effect -
identifies the subjects in your mixed model. Complete independence is assumed across subjects; therefore, the SUBJECT= option produces a block-diagonal structure in
with identical blocks. When the SUBJECT= effect consists entirely of classification variables, the blocks of correspond to observations that share the same level of that effect. These blocks are sorted according to this effect as
well.
If you want to model nonzero covariance among all of the observations in your SAS data set, specify SUBJECT=Dummy_Intercept to treat the data as if they are all from one subject. You need to create this Dummy_Intercept variable in the data set. However, be aware that in this case PROC HPLMIXED manipulates an
matrix with dimensions equal to the number of observations.
- TYPE=covariance-structure
-
specifies the covariance structure of the
matrix. The SUBJECT=
option defines the blocks of , and the TYPE= option specifies the structure of these blocks. The default structure is VC. You can specify any of the covariance
structures that are described in the TYPE=
option in the RANDOM statement.