The GLMSELECT Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsModel-Selection MethodsModel Selection IssuesCriteria Used in Model Selection MethodsCLASS Variable Parameterization and the SPLIT OptionMacro Variables Containing Selected ModelsUsing the STORE StatementBuilding the SSCP MatrixModel AveragingUsing Validation and Test DataCross ValidationExternal Cross ValidationScreeningDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
PROC GLMSELECT Statement
-
PROC GLMSELECT <options>;
The PROC GLMSELECT statement invokes the GLMSELECT procedure. Table 49.1 summarizes the options available in the PROC GLMSELECT statement.
Table 49.1: PROC GLMSELECT Statement Options
|
Option |
Description |
|---|---|
|
Data Set Options |
|
|
Names a data set to use for the regression |
|
|
Sets the maximum number of macro variables produced |
|
|
Names a data set that contains test data |
|
|
Names a data set that contains validation data |
|
|
ODS Graphics Options |
|
|
Produces ODS graphical displays |
|
|
Other Options |
|
|
Requests a data set that contains the design matrix |
|
|
Sets the length of effect names in tables and output data sets |
|
|
Suppresses displayed output including plots |
|
|
Sets the seed used for pseudo-random number generation |
|
Following are explanations of the options that you can specify in the PROC GLMSELECT statement (in alphabetical order).
- DATA=SAS-data-set
-
names the SAS data set to be used by PROC GLMSELECT. If the DATA= option is not specified, PROC GLMSELECT uses the most recently created SAS data set. If the named data set contains a variable named
_ROLE_, then this variable is used to assign observations for training, validation, and testing roles. See the section Using Validation and Test Data for details on using the_ROLE_variable. - MAXMACRO=n
-
specifies the maximum number of macro variables with selected effects to create. By default, MAXMACRO=100. PROC GLMSELECT saves the list of selected effects in a macro variable,
&_GLSIND. Say your input effect list consists ofx1-x10. Then&_GLSINDwould be set tox1 x3 x4 x10if, for example, the first, third, fourth, and tenth effects were selected for the model. This list can be used, for example, in the model statement of a subsequent procedure. If you specify the OUTDESIGN= option in the PROC GLMSELECT statement, then PROC GLMSELECT saves the list of columns in the design matrix in a macro variable named&_GLSMOD.With BY processing, one macro variable is created for each BY group, and the macro variables are indexed by the BY group number. The MAXMACRO= option can be used to either limit or increase the number of these macro variables when you are processing data sets with many BY groups.
With no BY processing, PROC GLMSELECT creates the following:
_GLSINDselected effects
_GLSIND1selected effects
_GLSMODdesign matrix columns
_GLSMOD1design matrix columns
_GLSNUMBYSnumber of BY groups
_GLSNUMMACROBYSnumber of
_GLSINDimacro variables actually madeWith BY processing, PROC GLMSELECT creates the following:
_GLSINDselected effects for BY group 1
_GLSIND1selected effects for BY group 1
_GLSIND2selected effects for BY group 2
.
.
.
_GLSINDmselected effects for BY group m, where a number is substituted for m
_GLSMODdesign matrix columns for BY group 1
_GLSMOD1design matrix columns for BY group 1
_GLSMOD2design matrix columns for BY group 2
.
.
.
_GLSMODmdesign matrix columns for BY group m, where a number is substituted for m
_GLSNUMBYSn, the number of BY groups
_GLSNUMMACROBYSthe number m of
_GLSINDimacro variables actually made. This value can be less than_GLSNUMBYS= n, and it is less than or equal to the MAXMACRO= value.See the section Macro Variables Containing Selected Models for further details.
- NOPRINT
- NAMELEN=n
-
specifies the length of effect names in tables and output data sets to be n characters long, where n is a value between 20 and 200 characters. The default length is 20 characters.
- OUTDESIGN <(options)><=SAS-data-set>
-
creates a data set that contains the design matrix. By default, the GLMSELECT procedure includes in the OUTDESIGN data set the
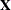 matrix corresponding to the parameters in the selected model. Two schemes for naming the columns of the design matrix are
available. In the first scheme, names of the parameters are constructed from the parameter labels that appear in the ParameterEstimates
table. This naming scheme is the default when you do not request BY processing and is not available when you do use BY processing.
In the second scheme, the design matrix column names consist of a prefix followed by an index. The default naming prefix is
matrix corresponding to the parameters in the selected model. Two schemes for naming the columns of the design matrix are
available. In the first scheme, names of the parameters are constructed from the parameter labels that appear in the ParameterEstimates
table. This naming scheme is the default when you do not request BY processing and is not available when you do use BY processing.
In the second scheme, the design matrix column names consist of a prefix followed by an index. The default naming prefix is
_X.You can specify the following options in parentheses to control the contents of the OUTDESIGN data set:
- PARMLABELSTYLE=options
-
specifies how parameter names and labels are constructed for nested and crossed effects.
The following options are available:
-
PLOTS <(global-plot-options)> <= plot-request <(options)>>
PLOTS <(global-plot-options)> <= (plot-request <(options)> <... plot-request <(options)>>)> -
controls the plots produced through ODS Graphics. When you specify only one plot request, you can omit the parentheses around the plot request. Here are some examples:
plots=all plots=coefficients(unpack) plots(unpack)=(criteria candidates)
ODS Graphics must be enabled before plots can be requested. For example:
ods graphics on; proc glmselect plots=all; model y = x1-x100; run; ods graphics off;
For more information about enabling and disabling ODS Graphics, see the section Enabling and Disabling ODS Graphics in Chapter 21: Statistical Graphics Using ODS.
Global Plot Options
The global-options apply to all plots generated by the GLMSELECT procedure, unless it is altered by a specific-plot-option.
Specific Plot Options
The following listing describes the specific plots and their options.
- SEED=number
-
specifies an integer used to start the pseudo-random number generator for resampling the data, random cross validation, and random partitioning of data for training, testing, and validation. If you do not specify a seed, or if you specify a value less than or equal to zero, the seed is generated from reading the time of day from the computer’s clock.
- TESTDATA=SAS-data-set
-
names a SAS data set containing test data. This data set must contain all the variables specified in the MODEL statement. Furthermore, when a BY statement is used and the TESTDATA=data set contains any of the BY variables, then the TESTDATA= data set must also contain all the BY variables sorted in the order of the BY variables. In this case, only the test data for a specific BY group is used with the corresponding BY group in the analysis data. If the TESTDATA= data set contains none of the BY variables, then the entire TESTDATA = data set is used with each BY group of the analysis data.
If you specify a TESTDATA=data set, then you cannot also reserve observations for testing by using a PARTITION statement.
- VALDATA=SAS-data-set
-
names a SAS data set containing validation data. This data set must contain all the variables specified in the MODEL statement. Furthermore, when a BY statement is used and the VALDATA=data set contains any of the BY variables, then the VALDATA= data set must also contain all the BY variables sorted in the order of the BY variables. In this case, only the validation data for a specific BY group are used with the corresponding BY group in the analysis data. If the VALDATA= data set contains none of the BY variables, then the entire VALDATA = data set is used with each BY group of the analysis data.
If you specify a VALDATA=data set, then you cannot also reserve observations for validation by using a PARTITION statement.