The SURVEYLOGISTIC Procedure
- Overview
- Getting Started
-
Syntax
 PROC SURVEYLOGISTIC StatementBY StatementCLASS StatementCLUSTER StatementCONTRAST StatementDOMAIN StatementEFFECT StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement
PROC SURVEYLOGISTIC StatementBY StatementCLASS StatementCLUSTER StatementCONTRAST StatementDOMAIN StatementEFFECT StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement -
DetailsMissing ValuesModel SpecificationModel FittingSurvey Design InformationLogistic Regression Models and ParametersVariance EstimationDomain AnalysisHypothesis Testing and EstimationLinear Predictor, Predicted Probability, and Confidence LimitsOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
The OUTPUT statement creates a new SAS data set that contains all the variables in the input data set and, optionally, the estimated linear predictors and their standard error estimates, the estimates of the cumulative or individual response probabilities, and the confidence limits for the cumulative probabilities. Formulas for the statistics are given in the section Linear Predictor, Predicted Probability, and Confidence Limits.
If you use the single-trial syntax, the data set also contains a variable named _LEVEL_, which indicates the level of the response that the given row of output is referring to. For example, the value of the cumulative
probability variable is the probability that the response variable is as large as the corresponding value of _LEVEL_. For details, see the section OUT= Data Set in the OUTPUT Statement.
The estimated linear predictor, its standard error estimate, all predicted probabilities, and the confidence limits for the cumulative probabilities are computed for all observations in which the explanatory variables have no missing values, even if the response is missing. By adding observations with missing response values to the input data set, you can compute these statistics for new observations, or for settings of the explanatory variables not present in the data, without affecting the model fit.
Table 98.8 summarizes the options available in the OUTPUT statement.
Table 98.8: OUTPUT Statement Options
|
Option |
Description |
|---|---|
|
Sets the level of significance |
|
|
Names the variable that contains the lower confidence limits |
|
|
Names the output data set |
|
|
Names the variable that contains the predicted probabilities |
|
|
Requests predicted probabilities |
|
|
Names the variable that contains the standard error estimates |
|
|
Names the variable that contains the upper confidence limits |
|
|
Names the variable that contains the estimates of the linear predictor |
You can specify the following options in the OUTPUT statement:
- LOWER | L=name
-
names the variable that contains the lower confidence limits for
 , where is the probability of the event response if events/trials syntax or the single-trial syntax with binary response is specified;
is cumulative probability (that is, the probability that the response is less than or equal to the value of
, where is the probability of the event response if events/trials syntax or the single-trial syntax with binary response is specified;
is cumulative probability (that is, the probability that the response is less than or equal to the value of _LEVEL_) for a cumulative model; and is the individual probability (that is, the probability that the response category is represented by the value of _LEVEL_)
for the generalized logit model. See the ALPHA=
option for information about setting the confidence level.
- OUT=SAS-data-set
-
names the output data set. If you omit the OUT= option, the output data set is created and given a default name by using the
DATAnconvention.The statistic options in the OUTPUT statement specify the statistics to be included in the output data set and name the new variables that contain the statistics.
- PREDICTED | P=name
-
names the variable that contains the predicted probabilities. For the events/trials syntax or the single-trial syntax with binary response, it is the predicted event probability. For a cumulative model, it is the predicted cumulative probability (that is, the probability that the response variable is less than or equal to the value of
_LEVEL_); and for the generalized logit model, it is the predicted individual probability (that is, the probability of the response category represented by the value of_LEVEL_). - PREDPROBS=(keywords)
-
requests individual, cumulative, or cross validated predicted probabilities. Descriptions of the keywords are as follows.
- INDIVIDUAL | I
-
requests the predicted probability of each response level. For a response variable
Ywith three levels, 1, 2, and 3, the individual probabilities are Pr(Y=1), Pr(Y=2), and Pr(Y=3). - CUMULATIVE | C
-
requests the cumulative predicted probability of each response level. For a response variable
Ywith three levels, 1, 2, and 3, the cumulative probabilities are Pr(Y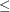 1), Pr(
1), Pr(Y2), and Pr(Y3). The cumulative probability for the last response level always has the constant value of 1. For generalized logit models,
the cumulative predicted probabilities are not computed and are set to missing.
- CROSSVALIDATE | XVALIDATE | X
-
requests the cross validated individual predicted probability of each response level. These probabilities are derived from the leave-one-out principle; that is, dropping the data of one subject and reestimating the parameter estimates. PROC SURVEYLOGISTIC uses a less expensive one-step approximation to compute the parameter estimates. This option is valid only for binary response models; for nominal and ordinal models, the cross validated probabilities are not computed and are set to missing.
See the section Details of the PREDPROBS= Option at the end of this section for further details.
- STDXBETA=name
-
names the variable that contains the standard error estimates of XBETA (the definition of which follows).
- UPPER | U=name
-
names the variable that contains the upper confidence limits for
, where is the probability of the event response if events/trials syntax or single-trial syntax with binary response is specified;
is cumulative probability (that is, the probability that the response is less than or equal to the value of _LEVEL_) for a cumulative model; and is the individual probability (that is, the probability that the response category is represented by the value of _LEVEL_)
for the generalized logit model. See the ALPHA=
option for information about setting the confidence level.
- XBETA=name
-
names the variable that contains the estimates of the linear predictor
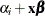 , where i is the corresponding ordered value of
, where i is the corresponding ordered value of _LEVEL_.
You can specify the following option in the OUTPUT statement after a slash (/):
- ALPHA=value
-
sets the level of significance
 for
for 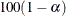 % confidence limits for the appropriate response probabilities. The value must be between 0 and 1. By default, is equal to the value of the ALPHA=
option in the PROC SURVEYLOGISTIC statement, or 0.05 if the ALPHA= option is not specified.
% confidence limits for the appropriate response probabilities. The value must be between 0 and 1. By default, is equal to the value of the ALPHA=
option in the PROC SURVEYLOGISTIC statement, or 0.05 if the ALPHA= option is not specified.
You can request any of the three given types of predicted probabilities. For example, you can request both the individual predicted probabilities and the cross validated probabilities by specifying PREDPROBS=(I X).
When you specify the PREDPROBS= option, two automatic variables _FROM_ and _INTO_ are included for the single-trial syntax and only one variable, _INTO_, is included for the events/trials syntax. The _FROM_ variable contains the formatted value of the observed response. The variable _INTO_ contains the formatted value of the response level with the largest individual predicted probability.
If you specify PREDPROBS=INDIVIDUAL, the OUTPUT data set contains k additional variables representing the individual probabilities, one for each response level, where k is the maximum number of response levels across all BY groups. The names of these variables have the form IP_xxx, where xxx represents the particular level. The representation depends on the following situations:
-
If you specify the events/trials syntax, xxx is either Event or Nonevent. Thus, the variable that contains the event probabilities is named
IP_Eventand the variable containing the nonevent probabilities is namedIP_Nonevent. -
If you specify the single-trial syntax with more than one BY group, xxx is 1 for the first ordered level of the response, 2 for the second ordered level of the response, and so forth, as given in the "Response Profile" table. The variable that contains the predicted probabilities Pr(
Y=1) is namedIP_1, whereYis the response variable. Similarly,IP_2is the name of the variable containing the predicted probabilities Pr(Y=2), and so on. -
If you specify the single-trial syntax with no BY-group processing, xxx is the left-justified formatted value of the response level (the value can be truncated so that
IP_xxx does not exceed 32 characters). For example, ifYis the response variable with response levels 'None,' 'Mild,' and 'Severe,' the variables representing individual probabilities Pr(Y='None'), Pr(Y='Mild'), and Pr(Y='Severe') are namedIP_None,IP_Mild, andIP_Severe, respectively.
If you specify PREDPROBS=CUMULATIVE, the OUTPUT data set contains k additional variables that represent the cumulative probabilities, one for each response level, where k is the maximum number of response levels across all BY groups. The names of these variables have the form CP_xxx, where xxx represents the particular response level. The naming convention is similar to that given by PREDPROBS=INDIVIDUAL. The PREDPROBS=CUMULATIVE
values are the same as those output by the PREDICT=keyword, but they are arranged in variables in each output observation
rather than in multiple output observations.
If you specify PREDPROBS=CROSSVALIDATE, the OUTPUT data set contains k additional variables representing the cross validated predicted probabilities of the k response levels, where k is the maximum number of response levels across all BY groups. The names of these variables have the form XP_xxx, where xxx represents the particular level. The representation is the same as that given by PREDPROBS=INDIVIDUAL, except that for the
events/trials syntax there are four variables for the cross validated predicted probabilities instead of two:
XP_EVENT_R1E-
is the cross validated predicted probability of an event when a current event trial is removed.
XP_NONEVENT_R1E-
is the cross validated predicted probability of a nonevent when a current event trial is removed.
XP_EVENT_R1N-
is the cross validated predicted probability of an event when a current nonevent trial is removed.
XP_NONEVENT_R1N-
is the cross validated predicted probability of a nonevent when a current nonevent trial is removed.