The SURVEYLOGISTIC Procedure
- Overview
- Getting Started
-
Syntax
 PROC SURVEYLOGISTIC StatementBY StatementCLASS StatementCLUSTER StatementCONTRAST StatementDOMAIN StatementEFFECT StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement
PROC SURVEYLOGISTIC StatementBY StatementCLASS StatementCLUSTER StatementCONTRAST StatementDOMAIN StatementEFFECT StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement -
DetailsMissing ValuesModel SpecificationModel FittingSurvey Design InformationLogistic Regression Models and ParametersVariance EstimationDomain AnalysisHypothesis Testing and EstimationLinear Predictor, Predicted Probability, and Confidence LimitsOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
- Degrees of Freedom
- Score Statistics and Tests
- Testing Global Null Hypothesis: BETA=0
- Testing the Parallel Lines Assumption
- Wald Confidence Intervals for Parameters
- Testing Linear Hypotheses about the Regression Coefficients
- Odds Ratio Estimation
- Rank Correlation of Observed Responses and Predicted Probabilities
In this section, the degrees of freedom (df) refers to the denominator degrees of freedom for F statistics in hypothesis testing, and the degrees of freedom in t tests in parameter estimates, odds ratio estimates, and their t percentiles for confidence limits.
By default, or if you specify DF=DESIGN in the MODEL statement, the degrees of freedom (also called the design degrees of freedom), is determined by the survey design and the variance estimation method as follows:
For Taylor series variance estimation, the df can depend on the number of clusters, the number of strata, and the number of observations. These numbers are based on the observations that are included in the analysis; they do not count observations that are excluded from the analysis because of missing values. If all values in a stratum are excluded from the analysis as missing values, then that stratum is called an empty stratum. Empty strata are not counted in the total number of strata for the analysis. Similarly, empty clusters and missing observations are not included in the totals counts of clusters and observations that are used to compute the df for the analysis.
If you specify the MISSING option in the CLASS statement, missing values are treated as valid nonmissing levels and are included in determining the df. If you specify the NOMCAR option for Taylor series variance estimation, observations that have missing values for variables in the regression model are included. For more information about missing values, see the section Missing Values.
By using the notation that is defined in the section Notation, let ![]() be the total number of clusters if the design has a CLUSTER
statement, let n be the total sample size, and let H be the number of strata if there is a STRATA
statement or H=1 otherwise. Define
be the total number of clusters if the design has a CLUSTER
statement, let n be the total sample size, and let H be the number of strata if there is a STRATA
statement or H=1 otherwise. Define
Then for Taylor series variance estimation, the design ![]() .
.
For replication variance estimation method, the design df depends on the replication method you use or whether you use replication weights.
-
If you provide replicate weights but you do not specify DF=value in the REPWEIGHTS statement, df is the number of replicates.
-
If you specify the DF=value option in a REPWEIGHTS statement, then df=value.
-
If you do not provide replicate weights and use BRR (including Fay’s method ) method, then df=H, which is the number of strata.
-
If you do not provide replicate weights and use the jackknife method, then
 , where R is the number of replicates and H is the number of strata if you specify a STRATA
statement or H = 1 otherwise.
, where R is the number of replicates and H is the number of strata if you specify a STRATA
statement or H = 1 otherwise.
If you do not want to use the default design degrees of freedom, then you can specify the DF=value option in the MODEL statement, where value is a positive number. Then, df=value.
However, if you specify the DF=value option in the MODEL statement together with the DF= option in a REPWEIGHTS statement, then the df is set to the value in the MODEL statement, and the DF= option in a REPWEIGHTS statement is ignored.
If you specify DF=INFINITY in the MODEL statement, then the df is set to be infinite.
When the denominator degrees of freedom for an F test is infinite, the F tests is equivalent to a chi-square test. When the degrees of freedom for a t percentile is infinite, the t percentile is equivalent to a normal percentile. Therefore, when you specify DF=INFINITY , PROC SURVEYLOGISTIC uses chi-square tests (instead of F tests) and normal percentiles (instead of t percentiles).
When you use Taylor series variance estimation (by default or when you specify VARMETHOD=TAYLOR
in the MODEL
statement), and you are fitting a model that has many parameters relative to the design degrees of freedom, it is appropriate
to modify the design degrees of freedom by using the number of nonsingular parameters p in the model (Korn and Graubard (1999, section 5.2), Rao, Scott, and Skinner (1998)). You can specify DF=PARMADJ
in the MODEL
statement to request this modification only for Taylor series variance estimation method; and this option does not apply
to the replication variance estimation method. Let f be the design degrees of freedom that is described in the section Design df for Taylor Series Method. If you specify the DF=PARMADJ
option, the df is modified as ![]() .
.
To express the general form of the score statistic, let ![]() be the parameter vector you want to estimate and let
be the parameter vector you want to estimate and let ![]() be the vector of first partial derivatives (gradient vector) of the log likelihood with respect to the parameter vector
be the vector of first partial derivatives (gradient vector) of the log likelihood with respect to the parameter vector ![]() .
.
Consider a null hypothesis ![]() that has r restrictions imposed on
that has r restrictions imposed on ![]() . Let
. Let ![]() be the MLE of
be the MLE of ![]() under
under ![]() , let
, let ![]() be the gradient vector evaluated at
be the gradient vector evaluated at ![]() , and let
, and let ![]() be the estimated covariance matrix for
be the estimated covariance matrix for ![]() , which is described in the section Variance Estimation.
, which is described in the section Variance Estimation.
For the Taylor series variance estimation method, PROC SURVEYLOGISTIC computes the score test statistic for the null hypothesis
![]() as
as
where f is the design degrees of freedom that is described in the section Design df for Taylor Series Method.
For the replication variance estimation method, PROC SURVEYLOGISTIC computes the score test statistic for the null hypothesis
![]() as
as
Under ![]() ,
, ![]() has an F distribution with
has an F distribution with ![]() degrees of freedom, where the denominator degrees of freedom df is described in the section Degrees of Freedom.
degrees of freedom, where the denominator degrees of freedom df is described in the section Degrees of Freedom.
If you specify DF=INFINITY
in the MODEL
statement, the value of df is set to infinity. In this case the score test statistic for both Taylor series and replication methods for testing the
null hypothesis ![]() can be expressed as
can be expressed as
![]() has a chi-square distribution with r degrees of freedom under the null hypothesis
has a chi-square distribution with r degrees of freedom under the null hypothesis ![]() .
.
The global null hypothesis refers to the null hypothesis that all the explanatory effects can be eliminated and the model contains only intercepts. By using the notations in the section Logistic Regression Models, the global null hypothesis is defined as the following:
-
For a cumulative model whose model parameters are
 , where
, where  are the parameters for the intercepts and
are the parameters for the intercepts and 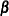 are the parameters for the explanatory effects,
are the parameters for the explanatory effects,  .
.
-
For a generalized logit model whose model parameters are
 and
and  , then
, then  .
.
PROC SURVEYLOGISTIC displays these tests in the "Testing Global Null Hypothesis: BETA=0" table.
For a model that has an ordinal response, the parallel lines assumption depends on the link function, which you can specify in the LINK= option in the MODEL statement. When the link function is probit or complementary log-log, the parallel lines assumption is the equal slopes assumption; PROC SURVEYLOGISTIC displays the corresponding test in the "Score Test for the Equal Slopes Assumption" table. When the link function is logit, the parallel lines assumption is the proportional odds assumption; PROC SURVEYLOGISTIC displays the corresponding test in the "Score Test for the Proportional Odds Assumption" table. This section describes the computation of the score tests of these assumptions.
For this test, the number of response levels, ![]() , is assumed to be strictly greater than 2. Let Y be the response variable taking values
, is assumed to be strictly greater than 2. Let Y be the response variable taking values ![]() . Suppose there are k explanatory variables. Consider the general cumulative model without making the parallel lines assumption:
. Suppose there are k explanatory variables. Consider the general cumulative model without making the parallel lines assumption:
where ![]() is the link function, and
is the link function, and ![]() is a vector of unknown parameters consisting of an intercept
is a vector of unknown parameters consisting of an intercept ![]() and k slope parameters
and k slope parameters ![]() . The parameter vector for this general cumulative model is
. The parameter vector for this general cumulative model is
Under the null hypothesis of parallelism ![]() , there is a single common slope parameter for each of the s explanatory variables. Let
, there is a single common slope parameter for each of the s explanatory variables. Let ![]() be the common slope parameters. Let
be the common slope parameters. Let ![]() and
and ![]() be the MLEs of the intercept parameters and the common slope parameters. Then, under
be the MLEs of the intercept parameters and the common slope parameters. Then, under ![]() , the MLE of
, the MLE of ![]() is
is
and the chi-square score statistic ![]() has an asymptotic chi-square distribution with
has an asymptotic chi-square distribution with ![]() degrees of freedom. This tests the parallel lines assumption by testing the equality of separate slope parameters simultaneously
for all explanatory variables.
degrees of freedom. This tests the parallel lines assumption by testing the equality of separate slope parameters simultaneously
for all explanatory variables.
Wald confidence intervals are sometimes called normal confidence intervals. They are based on the asymptotic normality of
the parameter estimators. The ![]() % Wald confidence interval for
% Wald confidence interval for ![]() is given by
is given by
where ![]() is the
is the ![]() percentile of the standard normal distribution,
percentile of the standard normal distribution, ![]() is the pseudo-estimate of
is the pseudo-estimate of ![]() , and
, and ![]() is the standard error estimate of
is the standard error estimate of ![]() in the section Variance Estimation.
in the section Variance Estimation.
Linear hypotheses for ![]() can be expressed in matrix form as
can be expressed in matrix form as
where ![]() is a matrix of coefficients for the linear hypotheses and
is a matrix of coefficients for the linear hypotheses and ![]() is a vector of constants whose rank is r. The vector of regression coefficients
is a vector of constants whose rank is r. The vector of regression coefficients ![]() includes both slope parameters and intercept parameters.
includes both slope parameters and intercept parameters.
Let ![]() be the MLE of
be the MLE of ![]() , and let
, and let ![]() be the estimated covariance matrix that is described in the section Variance Estimation.
be the estimated covariance matrix that is described in the section Variance Estimation.
For the Taylor series variance estimation method, PROC SURVEYLOGISTIC computes the test statistic for the null hypothesis
![]() as
as
where p is the number of nonsingular parameters in the model and f is the design degrees of freedom as described in the section Design df for Taylor Series Method.
For the replication variance estimation method, PROC SURVEYLOGISTIC computes the test statistic for the null hypothesis ![]() as
as
Under the ![]() ,
, ![]() has an F distribution with
has an F distribution with ![]() degrees of freedom, and the denominator degrees of freedom df is described in the section Degrees of Freedom.
degrees of freedom, and the denominator degrees of freedom df is described in the section Degrees of Freedom.
If you specify DF=INFINITY
in the MODEL
statement, then the df is set to infinite. PROC SURVEYLOGISTIC computes the test statistic for both Taylor series and replication methods for testing
the null hypothesis ![]() as
as
Under ![]() ,
, ![]() has an asymptotic chi-square distribution with r degrees of freedom.
has an asymptotic chi-square distribution with r degrees of freedom.
For models that use less-than-full-rank parameterization (as specified by the PARAM=GLM option in the CLASS statement), a Type 3 test of an effect of interest (main effect or interaction) is a test of the Type III estimable functions that are defined for that effect. When the model contains no missing cells, the Type 3 test of a main effect corresponds to testing the hypothesis of equal marginal means. For more information about Type III estimable functions, see Chapter 45: The GLM Procedure, and Chapter 15: The Four Types of Estimable Functions. Also see Littell, Freund, and Spector (1991).
For models that use full-rank parameterization, all parameters are estimable when there are no missing cells, so it is unnecessary to define estimable functions. The standard test of an effect of interest in this case is the joint test that the values of the parameters associated with that effect are zero. For a model that uses effects parameterization (as specified by the PARAM=EFFECT option in the CLASS statement), the joint test for a main effect is equivalent to testing the equality of marginal means. For a model that uses reference parameterization (as specified by the PARAM=REF option in the CLASS statement), the joint test is equivalent to testing the equality of cell means at the reference level of the other model effects. For more information about the coding scheme and the associated interpretation of results, see Muller and Fetterman (2002, Chapter 14).
If there is no interaction term, the Type 3 test of an effect for a model with GLM parameterization is the same as the joint test of the effect for the model with full-rank parameterization. In this situation, the joint test is also called the Type 3 test. For a model that contains an interaction term and no missing cells, the Type 3 test for a component main effect under GLM parameterization is the same as the joint test of the component main effect under effect parameterization. Both test the equality of cell means. But this Type 3 test differs from the joint test under reference parameterization, which tests the equality of cell means at the reference level of the other component main effect. If some cells are missing, you can obtain meaningful tests only by testing a Type III estimation function, so in this case you should use GLM parameterization.
The results of a Type 3 test or a joint test do not depend on the order in which the terms are specified in the MODEL statement.
Consider a dichotomous response variable with outcomes event and nonevent. Let a dichotomous risk factor variable X take the value 1 if the risk factor is present and 0 if the risk factor is absent.
According to the logistic model, the log odds function, ![]() , is given by
, is given by
The odds ratio ![]() is defined as the ratio of the odds for those with the risk factor (X = 1) to the odds for those without the risk factor (X = 0). The log of the odds ratio is given by
is defined as the ratio of the odds for those with the risk factor (X = 1) to the odds for those without the risk factor (X = 0). The log of the odds ratio is given by
The parameter, ![]() , associated with X represents the change in the log odds from X = 0 to X = 1. So the odds ratio is obtained by simply exponentiating the value of the parameter associated with the risk factor. The
odds ratio indicates how the odds of event change as you change X from 0 to 1. For instance,
, associated with X represents the change in the log odds from X = 0 to X = 1. So the odds ratio is obtained by simply exponentiating the value of the parameter associated with the risk factor. The
odds ratio indicates how the odds of event change as you change X from 0 to 1. For instance, ![]() means that the odds of an event when X = 1 are twice the odds of an event when X = 0.
means that the odds of an event when X = 1 are twice the odds of an event when X = 0.
Suppose the values of the dichotomous risk factor are coded as constants a and b instead of 0 and 1. The odds when ![]() become
become ![]() , and the odds when
, and the odds when ![]() become
become ![]() . The odds ratio corresponding to an increase in X from a to b is
. The odds ratio corresponding to an increase in X from a to b is
Note that for any a and b such that ![]() . So the odds ratio can be interpreted as the change in the odds for any increase of one unit in the corresponding risk factor.
However, the change in odds for some amount other than one unit is often of greater interest. For example, a change of one
pound in body weight might be too small to be considered important, while a change of 10 pounds might be more meaningful.
The odds ratio for a change in X from a to b is estimated by raising the odds ratio estimate for a unit change in X to the power of
. So the odds ratio can be interpreted as the change in the odds for any increase of one unit in the corresponding risk factor.
However, the change in odds for some amount other than one unit is often of greater interest. For example, a change of one
pound in body weight might be too small to be considered important, while a change of 10 pounds might be more meaningful.
The odds ratio for a change in X from a to b is estimated by raising the odds ratio estimate for a unit change in X to the power of ![]() , as shown previously.
, as shown previously.
For a polytomous risk factor, the computation of odds ratios depends on how the risk factor is parameterized. For illustration,
suppose that Race is a risk factor with four categories: White, Black, Hispanic, and Other.
For the effect parameterization scheme (PARAM=EFFECT) with White as the reference group, the design variables for Race are as follows.
|
Design Variables |
|||
|---|---|---|---|
|
Race |
|
|
|
|
Black |
1 |
0 |
0 |
|
Hispanic |
0 |
1 |
0 |
|
Other |
0 |
0 |
1 |
|
White |
–1 |
–1 |
–1 |
The log odds for Black is
The log odds for White is
Therefore, the log odds ratio of Black versus White becomes
For the reference cell parameterization scheme (PARAM=REF) with White as the reference cell, the design variables for race are as follows.
|
Design Variables |
|||
|---|---|---|---|
|
Race |
|
|
|
|
Black |
1 |
0 |
0 |
|
Hispanic |
0 |
1 |
0 |
|
Other |
0 |
0 |
1 |
|
White |
0 |
0 |
0 |
The log odds ratio of Black versus White is given by

For the GLM parameterization scheme (PARAM=GLM), the design variables are as follows.
|
Design Variables |
||||
|---|---|---|---|---|
|
Race |
|
|
|
|
|
Black |
1 |
0 |
0 |
0 |
|
Hispanic |
0 |
1 |
0 |
0 |
|
Other |
0 |
0 |
1 |
0 |
|
White |
0 |
0 |
0 |
1 |
The log odds ratio of Black versus White is

Consider the hypothetical example of heart disease among race in Hosmer and Lemeshow (2000, p. 51). The entries in the following contingency table represent counts.
|
Race |
||||
|---|---|---|---|---|
|
Disease Status |
White |
Black |
Hispanic |
Other |
|
Present |
5 |
20 |
15 |
10 |
|
Absent |
20 |
10 |
10 |
10 |
The computation of odds ratio of Black versus White for various parameterization schemes is shown in Table 98.9.
Table 98.9: Odds Ratio of Heart Disease Comparing Black to White
|
Parameter Estimates |
|||||
|---|---|---|---|---|---|
|
PARAM= |
|
|
|
|
Odds Ratio Estimates |
|
EFFECT |
0.7651 |
0.4774 |
0.0719 |
|
|
|
REF |
2.0794 |
1.7917 |
1.3863 |
|
|
|
GLM |
2.0794 |
1.7917 |
1.3863 |
0.0000 |
|
Since the log odds ratio (![]() ) is a linear function of the parameters, the Wald confidence interval for
) is a linear function of the parameters, the Wald confidence interval for ![]() can be derived from the parameter estimates and the estimated covariance matrix. Confidence intervals for the odds ratios
are obtained by exponentiating the corresponding confidence intervals for the log odd ratios. In the displayed output of PROC
SURVEYLOGISTIC, the "Odds Ratio Estimates" table contains the odds ratio estimates and the corresponding t or Wald confidence intervals computed by using the covariance matrix in the section Variance Estimation. For continuous explanatory variables, these odds ratios correspond to a unit increase in the risk factors.
can be derived from the parameter estimates and the estimated covariance matrix. Confidence intervals for the odds ratios
are obtained by exponentiating the corresponding confidence intervals for the log odd ratios. In the displayed output of PROC
SURVEYLOGISTIC, the "Odds Ratio Estimates" table contains the odds ratio estimates and the corresponding t or Wald confidence intervals computed by using the covariance matrix in the section Variance Estimation. For continuous explanatory variables, these odds ratios correspond to a unit increase in the risk factors.
To customize odds ratios for specific units of change for a continuous risk factor, you can use the UNITS
statement to specify a list of relevant units for each explanatory variable in the model. Estimates of these customized odds
ratios are given in a separate table. Let ![]() be a confidence interval for
be a confidence interval for ![]() . The corresponding lower and upper confidence limits for the customized odds ratio
. The corresponding lower and upper confidence limits for the customized odds ratio ![]() are
are ![]() and
and ![]() , respectively, (for
, respectively, (for ![]() ); or
); or ![]() and
and ![]() , respectively, (for c < 0). You use the CLODDS
option in the MODEL statement to request confidence intervals for the odds ratios.
, respectively, (for c < 0). You use the CLODDS
option in the MODEL statement to request confidence intervals for the odds ratios.
For a generalized logit model, odds ratios are computed similarly, except D odds ratios are computed for each effect, corresponding to the D logits in the model.
The predicted mean score of an observation is the sum of the Ordered Values (shown in the "Response Profile" table) minus
one, weighted by the corresponding predicted probabilities for that observation; that is, the predicted means score is ![]() , where D + 1 is the number of response levels and
, where D + 1 is the number of response levels and ![]() is the predicted probability of the dth (ordered) response.
is the predicted probability of the dth (ordered) response.
A pair of observations with different observed responses is said to be concordant if the observation with the lower ordered response value has a lower predicted mean score than the observation with the higher
ordered response value. If the observation with the lower ordered response value has a higher predicted mean score than the
observation with the higher ordered response value, then the pair is discordant. If the pair is neither concordant nor discordant, it is a tie. Enumeration of the total numbers of concordant and discordant pairs is carried out by categorizing the predicted mean score
into intervals of length ![]() and accumulating the corresponding frequencies of observations.
and accumulating the corresponding frequencies of observations.
Let N be the sum of observation frequencies in the data. Suppose there are a total of t pairs with different responses, ![]() of them are concordant,
of them are concordant, ![]() of them are discordant, and
of them are discordant, and ![]() of them are tied. PROC SURVEYLOGISTIC computes the following four indices of rank correlation for assessing the predictive
ability of a model:
of them are tied. PROC SURVEYLOGISTIC computes the following four indices of rank correlation for assessing the predictive
ability of a model:

Note that c also gives an estimate of the area under the receiver operating characteristic (ROC) curve when the response is binary (Hanley and McNeil, 1982).
For binary responses, the predicted mean score is equal to the predicted probability for Ordered Value 2. As such, the preceding definition of concordance is consistent with the definition used in previous releases for the binary response model.