The QUANTSELECT Procedure

Table 84.1 lists the options available in the PROC QUANTSELECT statement.
Table 84.1: PROC QUANTSELECT Statement Options
|
option |
Description |
|---|---|
|
Data Set Options |
|
|
Names a data set to use for the regression |
|
|
Sets the maximum number of macro variables to produce |
|
|
Names a data set that contains test data |
|
|
Names a data set that contains validation data |
|
|
ODS Graphics Options |
|
|
Produces ODS Graphics displays |
|
|
Other Options |
|
|
Specifies an algorithm for estimating the regression parameters |
|
|
Specifies the maximum length of effect names in tables and output data sets |
|
|
Suppresses displayed output (including plots) |
|
|
Names a data set that contains the design matrix |
|
|
Sets the style of parameter names and labels for nested and crossed effects |
|
|
Sets the seed used for pseudorandom number generation |
|
You can specify the following options (shown in alphabetical order) in the PROC QUANTSELECT statement.
- ALGORITHM=SIMPLEX | SMOOTH
-
specifies either the simplex algorithm (ALGORITHM=SIMPLEX) or the smoothing algorithm (ALGORITHM=SMOOTH) for estimating the regression parameters. The smoothing algorithm is computationally much more efficient than the simplex algorithm for fitting models on large data sets. You might consider specifying the ALGORITHM=SMOOTH if your DATA= data set contains more than 5,000 observations and more than 50 regressors. The smoothing algorithm does not support quantile process effect selection or the LASSO selection method. By default, ALGORITHM=SIMPLEX.
- DATA=SAS-data-set
-
names the SAS data set to be used by PROC QUANTSELECT. If the DATA= option is not specified, PROC QUANTSELECT uses the most recently created SAS data set. If the data set contains a variable named
_ROLE_, then this variable is used to assign observations for training, validation, and testing roles. See the section Using Validation and Test Data for more information about using the_ROLE_variable. - MAXMACRO=n
-
specifies the maximum number of macro variables with selected effects to create. By default, MAXMACRO=100.
PROC QUANTSELECT saves the list of selected effects in a macro variable,
&_QRSIND. For example, suppose your input effect list consists ofx1–x10. Then&_QRSINDwould be set tox1x3x4x10if the first, third, fourth, and tenth effects were selected for the model. This list can be used in the MODEL statement of a subsequent procedure.If you specify the OUTDESIGN= option in the PROC QUANTSELECT statement, then PROC QUANTSELECT saves the list of columns in the design matrix in a macro variable named
&_QRSMOD.With multiple quantile levels and BY processing, one macro variable is created for each combination of quantile level and BY group, and the macro variables are indexed by the BY-group number and the quantile level index. You can use the MAXMACRO= option to either limit or increase the number of these macro variables when you are processing data sets with many combinations of quantile level and BY group.
With a single quantile level and no BY-group processing, PROC QUANTSELECT creates the macro variables shown in Table 84.2.
Table 84.2: Macro Variables Created for a Single Quantile Level and No BY Processing
Macro Variable Name
Contains
_QRSINDSelected effects
_QRSIND1Selected effects
_QRSINDT1Selected effects
_QRSIND1T1Selected effects
_QRSMODSelected design matrix columns
_QRSMOD1Selected design matrix columns
_QRSMODT1Selected design matrix columns
_QRSMOD1T1Selected design matrix columns
With multiple quantile levels and BY-group processing, PROC QUANTSELECT creates the macro variables shown in Table 84.3.
Table 84.3: Macro Variables Created for a Multiple Quantile Levels and BY-Group Processing
Macro Variable Name
Contains
_QRSINDSelected effects for quantile 1 and BY group 1
_QRSINDT1Selected effects for quantile 1 and BY group 1
_QRSINDT2Selected effects for quantile 2 and BY group 1
.
.
.
_QRSIND1Selected effects for quantile 1 and BY group 1
_QRSIND1T1Selected effects for quantile 1 and BY group 1
_QRSIND1T2Selected effects for quantile 2 and BY group 1
.
.
.
_QRSIND2Selected effects for quantile 1 and BY group 2
_QRSIND2T1Selected effects for quantile 1 and BY group 2
_QRSIND2T2Selected effects for quantile 2 and BY group 2
.
.
.
_QRSINDmTnSelected effects for quantile n and BY group m
If you specify the OUTDESIGN= option, PROC QUANTSELECT also creates the macro variables shown in Table 84.4.
Table 84.4: Macro Variables Created When the OUTDESIGN= Option Is Specified
Macro Variable Name
Contains
_QRSMODSelected design matrix columns for BY group 1
_QRSMOD1Selected design matrix columns for BY group 1
_QRSMOD2Selected design matrix columns for BY group 2
.
.
.
_QRSMODmTnSelected design matrix columns for quantile n and BY group m
The macros variables in Table 84.5 show the number of quantiles and BY groups:
Table 84.5: Macro Variables Showing the Number of Quantiles and BY Groups
Macro Variable Name
Contains
_QRSNUMBYSThe number of BY groups
_QRSNUMTAUSThe number of quantiles
_QRSBY1NUMTAUSThe number of
_QRSIND1Tjmacro variables actually made_QRSBY2NUMTAUSThe number of
_QRSIND2Tjmacro variables actually made.
.
.
_QRSNUMBYTAUSThe number of
_QRSINDiTjmacro variables actually made. This value can be less than_QRSNUMBYS
_QRSNUMTAUS, and it is less than or equal to MAXMACRO=n.See the section Macro Variables That Contain Selected Models for more information.
- NAMELEN=number
-
specifies the maximum length of effect names. By default, NAMELEN=20. If you specify a value less than 20, the default is used.
- NOPRINT
- OUTDESIGN<(options)><=SAS-data-set>
-
creates a data set that contains the design matrix. By default, the QUANTSELECT procedure includes in the OUTDESIGN data set the
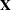 matrix that corresponds to all the effects in the selected models. Two schemes for naming the columns of the design matrix
are available:
matrix that corresponds to all the effects in the selected models. Two schemes for naming the columns of the design matrix
are available:
-
In the first scheme, names of the parameters are constructed from the parameter labels that appear in the parameter estimates table. This naming scheme is the default when you do not request BY processing, or when you specify the FULLMODEL option with BY processing.
-
In the second scheme, the design matrix column names consist of a prefix followed by an index. The default name prefix is
_X. This scheme is used when you specify the PREFIX= option, or when you specify a BY statement without using the FULLMODEL option; otherwise the first scheme is used.
You can specify the following options in parentheses to control the contents of the OUTDESIGN= data set:
-
- PARMLABELSTYLE=options
-
specifies how parameter names and labels are constructed for nested and crossed effects.
The following options are available:
-
PLOTS | PLOT <(global-plot-options)> <=plot-request <(options)>>
PLOTS | PLOT <(global-plot-options)> <=(plot-request <(options)> <... plot-request <(options)>>)> -
controls the plots that are produced through ODS Graphics. When you specify only one plot-request, you can omit the parentheses around it. Here are some examples:
plots=all plots=coefficients(unpack) plots(unpack)=(coef acl crit)
ODS Graphics must be enabled before plots can be requested. For example:
ods graphics on; proc quantselect plots=all; class temp sex / split; model depVar = sex sex*temp; run;
For more information about enabling and disabling ODS Graphics, see the section Enabling and Disabling ODS Graphics in Chapter 21: Statistical Graphics Using ODS.
You can specify the following global-plot-options, which apply to all plots generated by the QUANTSELECT procedure, unless they are altered by specific plot options.
The following list describes the specific plot-requests and their options.
- SEED=number
-
specifies an integer that is used to start the pseudorandom number generator for random partitioning of data for training, testing, and validation. If you do not specify a seed or if you specify a value less than or equal to 0, the seed is generated by reading the time of day from the computer’s clock.
- TESTDATA=SAS-data-set
-
names a SAS data set that contains test data. This data set must contain all the effects that are specified in the MODEL statement. Furthermore, when you also specify a BY statement and the TESTDATA= data set contains any of the BY variables, then the TESTDATA= data set must also contain all the BY variables sorted in the order of the BY variables. In this case, only the test data for a specific BY group are used with the corresponding BY group in the analysis data. If the TESTDATA= data set contains none of the BY variables, then the entire TESTDATA= data set is used with each BY group of the analysis data.
If you specify both a TESTDATA= data set and the PARTITION statement, then the testing observations from the DATA= data set are merged with the TESTDATA= data set for testing purposes.
- VALDATA=SAS-data-set
-
names a SAS data set that contains validation data. This data set must contain all the effects that are specified in the MODEL statement. Furthermore, when a BY statement is used and the VALDATA= data set contains any of the BY variables, then the VALDATA= data set must also contain all the BY variables sorted in the order of the BY variables. In this case, only the validation data for a specific BY group are used with the corresponding BY group in the analysis data. If the VALDATA= data set contains none of the BY variables, then the entire VALDATA= data set is used with each BY group of the analysis data.
If you specify both a VALDATA= data set and the PARTITION statement, then the validation observations from the DATA= data set are merged with the VALDATA= data set for validation purposes.