The CORRESP Procedure

This section is primarily based on the theory of correspondence analysis found in Greenacre (1984). If you are interested in other references, see the section Background.
Let ![]() be the contingency table formed from those observations and variables that are not supplementary and from those observations
that have no missing values and have a positive weight. This table is an
be the contingency table formed from those observations and variables that are not supplementary and from those observations
that have no missing values and have a positive weight. This table is an ![]() rank q matrix of nonnegative numbers with nonzero row and column sums. If
rank q matrix of nonnegative numbers with nonzero row and column sums. If ![]() is the binary coding for variable
is the binary coding for variable A, and ![]() is the binary coding for variable
is the binary coding for variable B, then ![]() is a contingency table. Similarly, if
is a contingency table. Similarly, if ![]() contains the binary coding for both variables
contains the binary coding for both variables B and C, then ![]() can also be input to a correspondence analysis. With the BINARY option,
can also be input to a correspondence analysis. With the BINARY option, ![]() , and the analysis is based on a binary table. In multiple correspondence analysis, the analysis is based on a Burt table,
, and the analysis is based on a binary table. In multiple correspondence analysis, the analysis is based on a Burt table,
![]() .
.
Let ![]() be a vector of 1s of the appropriate order, let
be a vector of 1s of the appropriate order, let ![]() be an identity matrix, and let diag
be an identity matrix, and let diag![]() be a matrix-valued function that creates a diagonal matrix from a vector. Let
be a matrix-valued function that creates a diagonal matrix from a vector. Let
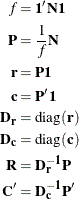
The scalar f is the sum of all elements in ![]() . The matrix
. The matrix ![]() is a matrix of relative frequencies. The vector
is a matrix of relative frequencies. The vector ![]() contains row marginal proportions or row "masses." The vector
contains row marginal proportions or row "masses." The vector ![]() contains column marginal proportions or column masses. The matrices
contains column marginal proportions or column masses. The matrices ![]() and
and ![]() are diagonal matrices of marginals.
are diagonal matrices of marginals.
The rows of ![]() contain the "row profiles." The elements of each row of
contain the "row profiles." The elements of each row of ![]() sum to one. Each
sum to one. Each ![]() element of
element of ![]() contains the observed probability of being in column j given membership in row i. Similarly, the columns of
contains the observed probability of being in column j given membership in row i. Similarly, the columns of ![]() contain the column profiles. The coordinates in correspondence analysis are based on the generalized singular value decomposition
of
contain the column profiles. The coordinates in correspondence analysis are based on the generalized singular value decomposition
of ![]() ,
,
where
In multiple correspondence analysis,
The matrix ![]() , which is the rectangular matrix of left generalized singular vectors, has
, which is the rectangular matrix of left generalized singular vectors, has ![]() rows and q columns; the matrix
rows and q columns; the matrix ![]() , which is a diagonal matrix of singular values, has q rows and columns; and the matrix
, which is a diagonal matrix of singular values, has q rows and columns; and the matrix ![]() , which is the rectangular matrix of right generalized singular vectors, has
, which is the rectangular matrix of right generalized singular vectors, has ![]() rows and q columns. The columns of
rows and q columns. The columns of ![]() and
and ![]() define the principal axes of the column and row point clouds, respectively.
define the principal axes of the column and row point clouds, respectively.
The generalized singular value decomposition of ![]() , discarding the last singular value (which is zero) and the last left and right singular vectors, is exactly the same as
a generalized singular value decomposition of
, discarding the last singular value (which is zero) and the last left and right singular vectors, is exactly the same as
a generalized singular value decomposition of ![]() , discarding the first singular value (which is one), the first left singular vector,
, discarding the first singular value (which is one), the first left singular vector, ![]() , and the first right singular vector,
, and the first right singular vector, ![]() . The first (trivial) column of
. The first (trivial) column of ![]() and
and ![]() and the first singular value in
and the first singular value in ![]() are discarded before any results are displayed. You can obtain the generalized singular value decomposition of
are discarded before any results are displayed. You can obtain the generalized singular value decomposition of ![]() from the ordinary singular value decomposition of
from the ordinary singular value decomposition of ![]() :
:
Hence, ![]() and
and ![]() .
.
The default row coordinates are ![]() , and the default column coordinates are
, and the default column coordinates are ![]() . Typically the first two columns of
. Typically the first two columns of ![]() and
and ![]() are plotted to display graphically associations between the row and column categories. The plot consists of two overlaid
plots, one for rows and one for columns. The row points are row profiles, and the column points are column profiles, both
rescaled so that distances between profiles can be displayed as ordinary Euclidean distances, then orthogonally rotated to
a principal axes orientation. Distances between row points and other row points have meaning, as do distances between column
points and other column points. However, distances between column points and row points are not interpretable.
are plotted to display graphically associations between the row and column categories. The plot consists of two overlaid
plots, one for rows and one for columns. The row points are row profiles, and the column points are column profiles, both
rescaled so that distances between profiles can be displayed as ordinary Euclidean distances, then orthogonally rotated to
a principal axes orientation. Distances between row points and other row points have meaning, as do distances between column
points and other column points. However, distances between column points and row points are not interpretable.
The PROFILE=, ROW=, and COLUMN= options standardize the coordinates before they are displayed and placed in the output data set. The options PROFILE=BOTH, PROFILE=ROW, and PROFILE=COLUMN provide the standardizations that are typically used in correspondence analysis. There are six choices each for row and column coordinates (see Table 34.3). However, most of the combinations of the ROW= and COLUMN= options are not useful. The ROW= and COLUMN= options are provided for completeness, but they are not intended for general use.
Table 34.3: Coordinates
|
ROW= |
Matrix Formula |
|
|---|---|---|
|
A |
|
|
|
AD |
|
|
|
DA |
|
|
|
DAD |
|
|
|
DAD1/2 |
|
|
|
DAID1/2 |
|
|
|
COLUMN= |
Matrix Formula |
|
|
B |
|
|
|
BD |
|
|
|
DB |
|
|
|
DBD |
|
|
|
DBD1/2 |
|
|
|
DBID1/2 |
|
When PROFILE=ROW (ROW=DAD and COLUMN=DB), the row coordinates ![]() and column coordinates
and column coordinates ![]() provide a correspondence analysis based on the row profile matrix. The row profile (conditional probability) matrix is defined
as
provide a correspondence analysis based on the row profile matrix. The row profile (conditional probability) matrix is defined
as ![]() . The elements of each row of
. The elements of each row of ![]() sum to one. Each
sum to one. Each ![]() element of
element of ![]() contains the observed probability of being in column j given membership in row i. The "principal" row coordinates
contains the observed probability of being in column j given membership in row i. The "principal" row coordinates ![]() and "standard" column coordinates
and "standard" column coordinates ![]() provide a decomposition of
provide a decomposition of ![]() . Because
. Because ![]() , the row coordinates are weighted centroids of the column coordinates. Each column point, with coordinates scaled to standard
coordinates, defines a vertex in
, the row coordinates are weighted centroids of the column coordinates. Each column point, with coordinates scaled to standard
coordinates, defines a vertex in ![]() -dimensional space. All of the principal row coordinates are located in the space defined by the standard column coordinates.
Distances among row points have meaning, but distances among column points and distances between row and column points are
not interpretable.
-dimensional space. All of the principal row coordinates are located in the space defined by the standard column coordinates.
Distances among row points have meaning, but distances among column points and distances between row and column points are
not interpretable.
The option PROFILE=COLUMN can be described as applying the PROFILE=ROW formulas to the transpose of the contingency table.
When PROFILE=COLUMN (ROW=DA and COLUMN=DBD), the principal column coordinates ![]() are weighted centroids of the standard row coordinates
are weighted centroids of the standard row coordinates ![]() . Each row point, with coordinates scaled to standard coordinates, defines a vertex in
. Each row point, with coordinates scaled to standard coordinates, defines a vertex in ![]() -dimensional space. All of the principal column coordinates are located in the space defined by the standard row coordinates.
Distances among column points have meaning, but distances among row points and distances between row and column points are
not interpretable.
-dimensional space. All of the principal column coordinates are located in the space defined by the standard row coordinates.
Distances among column points have meaning, but distances among row points and distances between row and column points are
not interpretable.
The usual sets of coordinates are given by the default PROFILE=BOTH (ROW=DAD and COLUMN=DBD). All of the summary statistics, such as the squared cosines and contributions to inertia, apply to these two sets of points.
One advantage to using these coordinates is that both sets ![]() and
and ![]() are postmultiplied by the diagonal matrix
are postmultiplied by the diagonal matrix ![]() , which has diagonal values that are all less than or equal to one. When
, which has diagonal values that are all less than or equal to one. When ![]() is a part of the definition of only one set of coordinates, that set forms a tight cluster near the centroid, whereas the
other set of points is more widely dispersed. Including
is a part of the definition of only one set of coordinates, that set forms a tight cluster near the centroid, whereas the
other set of points is more widely dispersed. Including ![]() in both sets makes a better graphical display. However, care must be taken in interpreting such a plot. No correct interpretation
of distances between row points and column points can be made.
in both sets makes a better graphical display. However, care must be taken in interpreting such a plot. No correct interpretation
of distances between row points and column points can be made.
Another property of this choice of coordinates concerns the geometry of distances between points within each set. The default row coordinates can be decomposed into ![]() . The row coordinates are row profiles
. The row coordinates are row profiles ![]() , rescaled by
, rescaled by ![]() (rescaled so that distances between profiles are transformed from a chi-square metric to a Euclidean metric), then orthogonally
rotated (with
(rescaled so that distances between profiles are transformed from a chi-square metric to a Euclidean metric), then orthogonally
rotated (with ![]() ) to a principal axes orientation. Similarly, the column coordinates are column profiles rescaled to a Euclidean metric and
orthogonally rotated to a principal axes orientation.
) to a principal axes orientation. Similarly, the column coordinates are column profiles rescaled to a Euclidean metric and
orthogonally rotated to a principal axes orientation.
The rationale for computing distances between row profiles by using the non-Euclidean chi-square metric is as follows. Each
row of the contingency table can be viewed as a realization of a multinomial distribution conditional on its row marginal
frequency. The null hypothesis of row and column independence is equivalent to the hypothesis of homogeneity of the row profiles.
A significant chi-square statistic is geometrically interpreted as a significant deviation of the row profiles from their
centroid, ![]() . The chi-square metric is the Mahalanobis metric between row profiles based on their estimated covariance matrix under the
homogeneity assumption (Greenacre and Hastie, 1987). A parallel argument can be made for the column profiles.
. The chi-square metric is the Mahalanobis metric between row profiles based on their estimated covariance matrix under the
homogeneity assumption (Greenacre and Hastie, 1987). A parallel argument can be made for the column profiles.
When ROW=DAD1/2 and COLUMN=DBD1/2 (Gifi, 1990; van der Heijden and de Leeuw, 1985), the row coordinates ![]() and column coordinates
and column coordinates ![]() are a decomposition of
are a decomposition of ![]() .
.
In all of the preceding pairs, distances between row and column points are not meaningful. This prompted Carroll, Green, and
Schaffer (1986) to propose that row coordinates ![]() and column coordinates
and column coordinates ![]() be used. These coordinates are (except for a constant scaling) the coordinates from a multiple correspondence analysis of
a Burt table created from two categorical variables. This standardization is available with ROW=DAID1/2 and COLUMN=DBID1/2.
However, this approach has been criticized on both theoretical and empirical grounds by Greenacre (1989). The Carroll, Green, and Schaffer standardization relies on the assumption that the chi-square metric is an appropriate metric for measuring the distance between
the columns of a bivariate indicator matrix. See the section Using the TABLES Statement for a description of indicator matrices. Greenacre (1989) showed that this assumption cannot be justified.
be used. These coordinates are (except for a constant scaling) the coordinates from a multiple correspondence analysis of
a Burt table created from two categorical variables. This standardization is available with ROW=DAID1/2 and COLUMN=DBID1/2.
However, this approach has been criticized on both theoretical and empirical grounds by Greenacre (1989). The Carroll, Green, and Schaffer standardization relies on the assumption that the chi-square metric is an appropriate metric for measuring the distance between
the columns of a bivariate indicator matrix. See the section Using the TABLES Statement for a description of indicator matrices. Greenacre (1989) showed that this assumption cannot be justified.
The MCA option performs a multiple correspondence analysis (MCA). This option requires a Burt table. You can specify the MCA option with a table created from a design matrix with fuzzy coding schemes as long as every row of every partition of the design matrix has the same marginal sum. For example, each row of each partition could contain the probabilities that the observation is a member of each level. Then the Burt table constructed from this matrix no longer contains all integers, and the diagonal partitions are no longer diagonal matrices, but MCA is still valid.
A TABLES statement with a single variable list creates a Burt table. Thus, you can always specify the MCA option with this type of input. If you use the MCA option when reading an existing table with a VAR statement, you must ensure that the table is a Burt table.
If you perform MCA on a table that is not a Burt table, the results of the analysis are invalid. If the table is not symmetric, or if the sums of all elements in each diagonal partition are not equal, PROC CORRESP displays an error message and quits.
A subset of the columns of a Burt table is not necessarily a Burt table, so in MCA it is not appropriate to designate arbitrary columns as supplementary. You can, however, designate all columns from one or more categorical variables as supplementary.
The results of a multiple correspondence analysis of a Burt table ![]() are the same as the column results from a simple correspondence analysis of the binary (or fuzzy) matrix
are the same as the column results from a simple correspondence analysis of the binary (or fuzzy) matrix ![]() . Multiple correspondence analysis is not a simple correspondence analysis of the Burt table. It is not appropriate to perform
a simple correspondence analysis of a Burt table. The MCA option is based on
. Multiple correspondence analysis is not a simple correspondence analysis of the Burt table. It is not appropriate to perform
a simple correspondence analysis of a Burt table. The MCA option is based on ![]() , whereas a simple correspondence analysis of the Burt table would be based on
, whereas a simple correspondence analysis of the Burt table would be based on ![]() .
.
Because the rows and columns of the Burt table are the same, no row information is displayed or written to the output data sets. The resulting inertias and the default (COLUMN=DBD) column coordinates are the appropriate inertias and coordinates for an MCA. The supplementary column coordinates, cosines, and quality of representation formulas for MCA differ from the simple correspondence analysis formulas because the design matrix column profiles and left singular vectors are not available.
The following statements create a Burt table and perform a multiple correspondence analysis:
proc corresp data=Neighbor observed short mca; tables Hair Height Sex Age; run;
Both the rows and the columns have the same nine categories (Blond, Brown, White, Short, Tall, Female, Male, Old, and Young).
The usual principal inertias of a Burt table constructed from m categorical variables in MCA are the eigenvalues ![]() from
from ![]() . The problem with these inertias is that they provide a pessimistic indication of fit. Benzécri (1979) proposed the following inertia adjustment, which is also described by Greenacre (1984, p. 145):
. The problem with these inertias is that they provide a pessimistic indication of fit. Benzécri (1979) proposed the following inertia adjustment, which is also described by Greenacre (1984, p. 145):
![]()
![]() for
for ![]()
This adjustment computes the percent of adjusted inertia relative to the sum of the adjusted inertias for all inertias greater
than ![]() . The Benzécri adjustment is available with the BENZECRI option.
. The Benzécri adjustment is available with the BENZECRI option.
Greenacre (1994, p. 156) argues that the Benzécri adjustment overestimates the quality of fit. Greenacre proposes instead to compute the percentage of adjusted inertia relative to
![]()
for all inertias greater than ![]() , where
, where ![]() is the sum of squared inertias. The Greenacre adjustment is available with the GREENACRE option.
is the sum of squared inertias. The Greenacre adjustment is available with the GREENACRE option.
Ordinary unadjusted inertias are printed by default with MCA when neither the BENZECRI nor the GREENACRE option is specified. However, the unadjusted inertias are not printed by default when either the BENZECRI or the GREENACRE option is specified. To display both adjusted and unadjusted inertias, specify the UNADJUSTED option in addition to the relevant adjusted inertia option (BENZECRI, GREENACRE, or both).
Supplementary rows and columns are represented as points in the joint row and column space, but they are not used in determining
the locations of the other active rows and columns of the table. The formulas that are used to compute coordinates for the
supplementary rows and columns depend on the PROFILE= option or the ROW= and COLUMN= options. Let ![]() be a matrix with rows that contain the supplementary observations, and let
be a matrix with rows that contain the supplementary observations, and let ![]() be a matrix with rows that contain the supplementary variables. Note that
be a matrix with rows that contain the supplementary variables. Note that ![]() is defined to be the transpose of the supplementary variable partition of the table. Let
is defined to be the transpose of the supplementary variable partition of the table. Let ![]() be the supplementary observation profile matrix, and let
be the supplementary observation profile matrix, and let ![]() be the supplementary variable profile matrix. Note that the notation diag
be the supplementary variable profile matrix. Note that the notation diag![]() means to convert the vector to a diagonal matrix, then invert the diagonal matrix. The coordinates for the supplementary
observations and variables are shown in Table 34.4.
means to convert the vector to a diagonal matrix, then invert the diagonal matrix. The coordinates for the supplementary
observations and variables are shown in Table 34.4.
Table 34.4: Coordinates for Supplementary Observations
|
ROW= |
Matrix Formula |
|---|---|
|
A |
|
|
AD |
|
|
DA |
|
|
DAD |
|
|
DAD1/2 |
|
|
DAID1/2 |
|
|
COLUMN= |
Matrix Formula |
|
B |
|
|
BD |
|
|
DB |
|
|
DBD |
|
|
DBD1/2 |
|
|
DBID1/2 |
|
|
MCA COLUMN= |
Matrix Formula |
|
B |
not allowed |
|
BD |
not allowed |
|
DB |
|
|
DBD |
|
|
DBD1/2 |
|
|
DBID1/2 |
|
The partial contributions to inertia, squared cosines, quality of representation, inertia, and mass provide additional information about the coordinates. These statistics are displayed by default. Include the SHORT or NOPRINT option in the PROC CORRESP statement to avoid having these statistics displayed.
These statistics pertain to the default PROFILE=BOTH coordinates, no matter what values you specify for the ROW=, COLUMN=,
or PROFILE= option. Let ![]() be a matrix-valued function denoting element-wise squaring of the argument matrix. Let t be the total inertia (the sum of the elements in
be a matrix-valued function denoting element-wise squaring of the argument matrix. Let t be the total inertia (the sum of the elements in ![]() ).
).
In MCA, let ![]() be the Burt table partition containing the intersection of the supplementary columns and the supplementary rows. The matrix
be the Burt table partition containing the intersection of the supplementary columns and the supplementary rows. The matrix
![]() is a diagonal matrix of marginal frequencies of the supplemental columns of the binary matrix
is a diagonal matrix of marginal frequencies of the supplemental columns of the binary matrix ![]() . Let p be the number of rows in this design matrix. The statistics are defined in Table 34.5.
. Let p be the number of rows in this design matrix. The statistics are defined in Table 34.5.
Table 34.5: Statistics That Aid Interpretation
|
Statistic |
Matrix Formula |
|
|---|---|---|
|
Row partial contributions |
|
|
|
to inertia |
||
|
Column partial contributions |
|
|
|
to inertia |
||
|
Row squared cosines |
|
|
|
Column squared cosines |
|
|
|
Row mass |
|
|
|
Column mass |
|
|
|
Row inertia |
|
|
|
Column inertia |
|
|
|
Supplementary row |
|
|
|
squared cosines |
||
|
Supplementary column |
|
|
|
squared cosines |
||
|
MCA supplementary column |
|
|
|
squared cosines |
The quality of representation in the DIMENS=n dimensional display of any point is the sum of its squared cosines over only the n dimensions. Inertia and mass are not defined for supplementary points.
A table that summarizes the partial contributions to inertia table is also computed. The points that best explain the inertia
of each dimension and the dimension to which each point contributes the most inertia are indicated. The output data set variable
names for this table are Best1–Bestn (where DIMENS=n) and Best. The Best column contains the dimension number of the largest partial contribution to inertia for each point (the index of the maximum
value in each row of ![]() or
or ![]() ).
).
For each row, the Best1–Bestn columns contain either the corresponding value of Best, if the point is one of the biggest contributors to the dimension’s inertia, or 0 if it is not. Specifically, Best1 contains the value of Best for the point with the largest contribution to dimension one’s inertia. A cumulative proportion sum is initialized to this
point’s partial contribution to the inertia of dimension one. If this sum is less than the value for the MININERTIA= option,
then Best1 contains the value of Best for the point with the second-largest contribution to dimension one’s inertia. Otherwise, this point’s Best1 is 0. This point’s partial contribution to inertia is added to the sum. This process continues for the point with the third-largest
partial contribution, and so on, until adding a point’s contribution to the sum increases the sum beyond the value of the
MININERTIA= option. This same algorithm is then used for Best2, and so on.
For example, the following table contains contributions to inertia and the corresponding Best variables. The contribution to inertia variables are proportions that sum to 1 within each column. The first point makes
its greatest contribution to the inertia of dimension two, so Best for point one is set to 2, and Best1–Best3 for point one must all be 0 or 2. The second point also makes its greatest contribution to the inertia of dimension two,
so Best for point two is set to 2, and Best1–Best3 for point two must all be 0 or 2, and so on.
Assume MININERTIA=0.8, the default. Table 34.6 shows some contributions to inertia. In dimension one, the largest contribution is 0.41302 for the fourth point, so Best1 is set to 1, the value of Best for the fourth point. Because this value is less than 0.8, the second-largest value (0.36456 for point five) is found and
its Best1 is set to its Best’s value of 1. Because ![]() is less than 0.8, the third point (0.0882 at point eight) is found and
is less than 0.8, the third point (0.0882 at point eight) is found and Best1 is set to 3, because the contribution to dimension three for that point is greater than the contribution to dimension one.
This increases the sum of the partial contributions to greater than 0.8, so the remaining Best1 values are all 0.
Table 34.6: Best Statistics
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
0.01593 |
0.32178 |
0.07565 |
0 |
2 |
2 |
2 |
|
0.03014 |
0.24826 |
0.07715 |
0 |
2 |
2 |
2 |
|
0.00592 |
0.02892 |
0.02698 |
0 |
0 |
0 |
2 |
|
0.41302 |
0.05191 |
0.05773 |
1 |
0 |
0 |
1 |
|
0.36456 |
0.00344 |
0.15565 |
1 |
0 |
1 |
1 |
|
0.03902 |
0.30966 |
0.11717 |
0 |
2 |
2 |
2 |
|
0.00019 |
0.01840 |
0.00734 |
0 |
0 |
0 |
2 |
|
0.08820 |
0.00527 |
0.16555 |
3 |
0 |
3 |
3 |
|
0.01447 |
0.00024 |
0.03851 |
0 |
0 |
0 |
3 |
|
0.02855 |
0.01213 |
0.27827 |
0 |
0 |
3 |
3 |