The MCMC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsHow PROC MCMC WorksBlocking of ParametersSampling MethodsTuning the Proposal DistributionDirect SamplingConjugate SamplingInitial Values of the Markov ChainsAssignments of ParametersStandard DistributionsUsage of Multivariate DistributionsSpecifying a New DistributionUsing Density Functions in the Programming StatementsTruncation and CensoringSome Useful SAS FunctionsMatrix Functions in PROC MCMCCreate Design MatrixModeling Joint LikelihoodRegenerating Diagnostics PlotsCaterpillar PlotAutocall Macros for PostprocessingGamma and Inverse-Gamma DistributionsPosterior Predictive DistributionHandling of Missing DataFunctions of Random-Effects ParametersFloating Point Errors and OverflowsHandling Error MessagesComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesSimulating Samples From a Known DensityBox-Cox TransformationLogistic Regression Model with a Diffuse PriorLogistic Regression Model with Jeffreys’ PriorPoisson RegressionNonlinear Poisson Regression ModelsLogistic Regression Random-Effects ModelNonlinear Poisson Regression Multilevel Random-Effects ModelMultivariate Normal Random-Effects ModelMissing at Random AnalysisNonignorably Missing Data (MNAR) AnalysisChange Point ModelsExponential and Weibull Survival AnalysisTime Independent Cox ModelTime Dependent Cox ModelPiecewise Exponential Frailty ModelNormal Regression with Interval CensoringConstrained AnalysisImplement a New Sampling AlgorithmUsing a Transformation to Improve MixingGelman-Rubin Diagnostics
- References
The gamma and inverse gamma distributions are widely used in Bayesian analysis. With their respective scale and inverse scale parameterizations, they are a frequent source of confusion in the field. This section aims to clarify their parameterizations and common usages.
The gamma distribution is often used as the conjugate prior for the precision parameter (![]() ) in a normal distribution. See Table 55.19 in the section Standard Distributions for the density definitions. You can specify the distribution in two ways:
) in a normal distribution. See Table 55.19 in the section Standard Distributions for the density definitions. You can specify the distribution in two ways:
-
gamma(shape=, scale=)which has meanshape
scaleand variance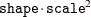
-
gamma(shape=, iscale=)which has mean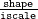 and variance
and variance 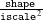
The parameterization of the gamma distribution that is preferred by most Bayesian analysts is to have the same number in
both hyperparameter positions, which results in a prior distribution that has mean 1. To do this, you should use the iscale= parameterization. In addition, if you choose a small value (for example, 0.01), the prior distribution takes on a large variance
(100 in this example). To specify this prior in PROC MCMC, use gamma(shape=0.01, iscale=0.01)[17], not gamma(shape=0.01, scale=0.01).
If you specify the scale= parameterization, as in gamma(shape=0.01, scale=0.01), you would get a prior distribution that has mean 0.0001 and variance 0.000001. This would lead to a completely different
posterior inference: the prior would push the precision parameter estimate close to 0, or the variance estimate to a large
value.
The inverse-gamma distribution is often used as the conjugate prior of the variance parameter (![]() ) in a normal distribution. See Table 55.22 in the section Standard Distributions for the density definitions. Similar to the gamma distribution, you can specify the inverse-gamma distribution in two ways:
) in a normal distribution. See Table 55.22 in the section Standard Distributions for the density definitions. Similar to the gamma distribution, you can specify the inverse-gamma distribution in two ways:
-
igamma(shape=, scale=) -
igamma(shape=, iscale=)
The inverse gamma distribution does not have a mean when the shape parameter is less than or equal to 1 and does not have a variance when the shape parameter is less than or equal to 2.
A gamma prior distribution on the precision is the equivalent to an inverse gamma prior distribution on the variance. The equivalency is the following:
Note: This mnemonic might help you remember the parameterization scheme of the distributions. If you prefer to have identical
hyperparameter values in the distribution, you should specify one and only one “i.”. When the “i” appears in the igamma distribution name for the variance parameter, choose the scale= parameterization; when the “i” appears in the iscale= parameterization, choose the gamma distribution for the precision parameter.
If you are not sure about the choices of other hyperparameter values and what type of prior distributions they induce, you can write a simple PROC MCMC program and see the distributions as in the following example:
data a; run; ods graphics on; ods select DensityPanel; proc mcmc data=a stats=none diag=none nmc=10000 outpost=gout plots=density seed=1; parms gamma_3_is2 gamma_001_sc4 igamma_12_sc001 igamma_2_is01; prior gamma_3_is2 ~ gamma(shape=3, iscale=2); prior gamma_001_sc4 ~ gamma(shape=0.01, scale=4); prior igamma_12_sc001 ~ igamma(shape=12, scale=0.01); prior igamma_2_is01 ~ igamma(shape=2, iscale=0.1); model general(0); run; ods graphics off;
The preceding statements specify four different gamma and inverse gamma distributions with various scale and inverse scale parameter values. The output of kernel density plots of these four prior distributions is shown in Figure 55.19. Note how the X axis scales vary across different distributions.
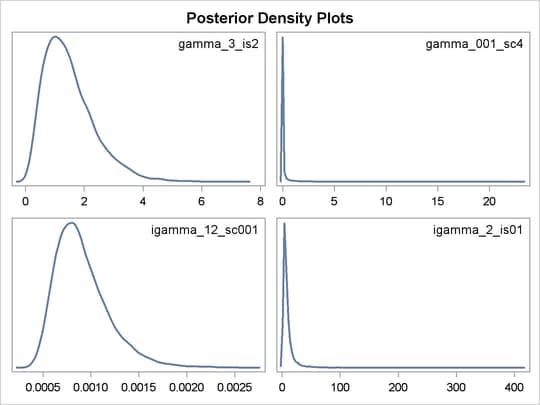
[17] Specifying the same number at both positions and choosing a small value has been popularized by the WinBUGS software program.
The WinBUGS’s distribution specification of dgamma(0.01, 0.01) is equivalent to specifying gamma(shape=0.01, iscale=0.01) in PROC MCMC.