The SURVEYPHREG Procedure
- Overview
- Getting Started
-
Syntax
 PROC SURVEYPHREG Statement BY Statement CLASS Statement CLUSTER Statement DOMAIN Statement ESTIMATE Statement FREQ Statement LSMEANS Statement LSMESTIMATE Statement MODEL Statement NLOPTIONS Statement OUTPUT Statement Programming Statements REPWEIGHTS Statement SLICE Statement STORE Statement STRATA Statement TEST Statement WEIGHT Statement
PROC SURVEYPHREG Statement BY Statement CLASS Statement CLUSTER Statement DOMAIN Statement ESTIMATE Statement FREQ Statement LSMEANS Statement LSMESTIMATE Statement MODEL Statement NLOPTIONS Statement OUTPUT Statement Programming Statements REPWEIGHTS Statement SLICE Statement STORE Statement STRATA Statement TEST Statement WEIGHT Statement -
Details
Notation and Estimation Failure Time Distribution Time and CLASS Variables Usage Partial Likelihood Function for the Cox Model Specifying the Sample Design Missing Values Variance Estimation Domain Analysis Hypothesis Tests, Confidence Intervals, and Residuals Output Data Sets Displayed Output ODS Table Names ODS Graphics
-
Examples
- References
Example 89.2 Stratification, Clustering, and Unequal Weights
This example uses a data set from the National Health and Nutrition Examination Survey I (NHANES I) Epidemiologic Followup Study (NHEFS). The NHEFS is a national longitudinal survey that is conducted by the National Center for Health Statistics, the National Institute on Aging, and some other agencies of the Public Health Service in the United States. Some important objectives of this survey are to determine the relationships between clinical, nutritional, and behavioral factors; to determine mortality and hospital utilizations; and to monitor changes in risk factors for the initial cohort that represents the NHANES I population. A cohort of size 14,407, which includes all persons 25 to 74 years old who completed a medical examination at NHANES I in 1971–1975, was selected for the NHEFS. Personal interviews were conducted for every selected unit during the first wave of data collection from the year 1982 to 1984. Follow-up studies were conducted in 1986, 1987, and 1992. In the year 1986, only nondeceased persons 55 to 74 years old (as reported in the base year survey) were interviewed. The 1987 and 1992 NHEFS contain the entire nondeceased NHEFS cohort. Vital and tracing status data, interview data, health care facility stay data, and mortality data for all four waves are available for public use. See http://www.cdc.gov/nchs/nhanes/nhefs/nhefs.htm for more information about the survey and the data sets.
For illustration purposes, 1,018 observations from the 1987 NHEFS public use interview data are used to create the data set cancer. The observations are obtained from 10 strata that contain 596 PSUs. The sum of observation weights for these selected units is over 19 million. Observation weights range from 359 to 129,359 with a mean of 18,747.69 and a median of 11,414. Several observation weights have large values; therefore it is reasonable to rescale the observation weights to facilitate the optimization routine. Different scaling techniques are proposed in the literature. For example, Binder (1992) uses scaled weights such that the sum of weights over the sampled units is one. Without loss of generality, the analysis weights in this example are obtained by dividing each observation weight by a large number (130,000). Because of this rescaling, you must be careful interpreting some results from PROC SURVEYPHREG.
The following variables are used in this example:
ObsNo, unit identification
Strata, stratum identification
PSU, identification for primary sampling units
ObservationWt, sampling weight associated with each unit
AnalysisWt, obtained from the sampling weights by dividing each ObservationWt by 130,000
Smoke, smoking status (–1 = not applicable, 1 = never smoked, 2 = current or former smoker in 1982–1984 follow-up, and 3 = current or former smoker in 1987 follow-up)
-
Age, the event-time variable, defined as follows:
age of the subject when the first cancer was reported for subjects with reported cancer
age of the subject at death for deceased subjects without reported cancer
age of the subject as reported in 1987 follow-up (this value is used for nondeceased subjects who never reported cancer)
age of the subject for the entry year 1971–1975 survey if the subject has cancer (or is deceased) but the date of incident is not reported
Cancer, cancer indicator (1 = cancer reported, 0 = cancer not reported)
BodyWeight, body weight of the subject as reported in the 1987 follow-up, or an imputed body weight based on the subject’s age in the entry year 1971–1975 survey
The following SAS statements create the data set cancer. Note that BodyWeight for a few observations (8%) is imputed based on Age by using a deterministic regression imputation model (Särndal and Lundström (2005, chapter 12)). The imputed values are treated as observed values in this example. In other words, this example treats the data set Cancer as the observed data set.
data cancer;
input ObsNo Strata PSU AnalysisWt ObservationWt Smoke
Age Cancer BodyWeight;
datalines;
1 3 002 0.02927 3805 2 53 1 175
2 3 002 0.04698 6107 2 77 0 175
3 3 039 0.02283 2968 2 50 0 160
4 3 084 0.23414 30438 2 52 0 145
5 3 007 0.03908 5081 1 80 0 127
6 3 009 0.02993 3891 1 62 0 180
7 3 009 0.02754 3580 2 50 0 157
8 3 022 0.02283 2968 2 56 0 142
... more lines ...
1016 4 002 0.02068 2689 2 40 0 120
1017 4 092 0.35298 45888 2 52 0 166
1018 4 035 0.03344 4347 -1 58 0 156
;
Suppose you want to study the occurrence of cancer for the base year survey population and its relation to smoking status and body weight. The following statements request a proportional hazards regression of Age on BodyWeight and Smoke with Cancer as the censor indicator. The STRATA, CLUSTER, and WEIGHT statements identify the variance strata, PSUs, and analysis weights respectively. The CLASS statement specifies that Smoke is a categorical variable, and the MODEL statement provides information about the analysis model. The TIES= option in the MODEL statement requests the Efron likelihood to handle tied events. If you do not specify the TIES= option in the MODEL statement, then the procedure uses the Breslow likelihood. The PHISTORY option in the NLOPTIONS statement is used to display the iteration history table. The ESTIMATE statement computes a contrast between subjects who are reported as current (or former) smokers and the others. The EXP option in the ESTIMATE statement requests that the linear contrast be estimated in the exponential scale, which is the hazard ratio.
proc surveyphreg data = cancer; strata strata; cluster psu; weight analysiswt; class smoke; model age*cancer(0) = bodyweight smoke / ties = efron; nloptions phistory; estimate smoke 0.5 0.5 -0.5 -0.5 / exp; run;
Some summary statistics are shown in Output 89.2.1. The "Model Information" table contains information about the model such as the names for the dependent and censoring variables, and the likelihood. The "Number of Observations" table displays the number of observations and the sum of weights. A total of 1,018 observations are read from the Cancer data set, but one observation is not used in the analysis because it has a zero sampling weight. The sum of weights is 146.81, which gives an estimated population size of 19,085,105 (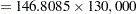 ). Note that the estimated population size would be 19,085,151 if you use the sampling weights (ObservationWt) instead of the analysis weights (AnalysisWt). The difference is due to the rounding errors in AnalysisWt. For simplicity, analysis weights are rounded at the fifth decimal place. The "Design Summary" table shows that there are 596 PSUs and 10 strata. From the censored summary tables, 11.7% subjects in the sample have reported cancer and an estimated 11.6% subjects in the study population have cancer. The "Variance Estimation" table shows that the Taylor series linearization variance estimation method is used and the observation units with missing values are excluded from the analysis. Note that the only missing unit in this data set has a zero sampling weight and hence it is not included in the analysis.
). Note that the estimated population size would be 19,085,151 if you use the sampling weights (ObservationWt) instead of the analysis weights (AnalysisWt). The difference is due to the rounding errors in AnalysisWt. For simplicity, analysis weights are rounded at the fifth decimal place. The "Design Summary" table shows that there are 596 PSUs and 10 strata. From the censored summary tables, 11.7% subjects in the sample have reported cancer and an estimated 11.6% subjects in the study population have cancer. The "Variance Estimation" table shows that the Taylor series linearization variance estimation method is used and the observation units with missing values are excluded from the analysis. Note that the only missing unit in this data set has a zero sampling weight and hence it is not included in the analysis.
| Model Information | |
|---|---|
| Data Set | WORK.CANCER |
| Dependent Variable | Age |
| Censoring Variable | Cancer |
| Censoring Value(s) | 0 |
| Weight Variable | AnalysisWt |
| Stratum Variable | Strata |
| Cluster Variable | PSU |
| Ties Handling | EFRON |
| Number of Observations Read | 1018 |
|---|---|
| Number of Observations Used | 1017 |
| Sum of Weights Read | 146.8085 |
| Sum of Weights Used | 146.8085 |
| Design Summary | |
|---|---|
| Number of Strata | 10 |
| Number of Clusters | 596 |
| Summary of the Number of Event and Censored Values |
|||
|---|---|---|---|
| Total | Event | Censored | Percent Censored |
| 1017 | 119 | 898 | 88.30 |
| Summary of the Weighted Number of Event and Censored Values |
|||
|---|---|---|---|
| Total | Event | Censored | Percent Censored |
| 146.8085 | 17.01185 | 129.7966 | 88.41 |
| Variance Estimation | |
|---|---|
| Method | Taylor Series |
| Missing Values | Excluded |
The "Iteration History" table in Output 89.2.2 shows that the procedure converged after four iterations. The "Objective Function" column contains the value of the likelihood after every iteration. The "Objective Function Change" column measures the change in the objective function between iterations; however, this is not the monitored convergence criterion. The SURVEYPHREG procedure monitors several features simultaneously to determine whether to stop an optimization.
| Maximum Likelihood Iteration History | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Iteration | Restarts | Function Calls |
Active Constraints |
Objective Function |
Objective Function Change |
Max Abs Gradient Element |
Ridge | Ratio Between Actual and Predicted Change |
||
| 1 | 0 | 4 | 0 | -63.34004 | 1.6501 | 21.9620 | 0 | 0.916 | ||
| 2 | 0 | 6 | 0 | -63.29819 | 0.0418 | 0.2005 | 0 | 1.052 | ||
| 3 | 0 | 8 | 0 | -63.29776 | 0.000430 | 0.00293 | 0 | 1.012 | ||
| 4 | 0 | 10 | 0 | -63.29776 | 1.528E-7 | 1.102E-6 | 0 | 1.000 | ||
Estimates for proportional hazards regression coefficients and their standard errors are shown in Output 89.2.3. The categorical variable Smoke has four levels, and GLM parameterization is used by PROC SURVEYPHREG. You can use the PARAM= option in the CLASS statement to specify other types of parameterizations. The estimated regression coefficient for BodyWeight is 0.012 with a standard error of 0.003. The degrees of freedom for the  test are equal to the number of PSUs (596) minus the number of strata (10). The "Estimates" table displays the estimated contrast and the corresponding hypothesis test. The estimated value for the contrast is –0.75. The estimated hazard for the nonsmokers is 0.47 times the estimated hazard for the current or former smokers. In this example data set, the contrast of interest is not significant at 0.05 levels.
test are equal to the number of PSUs (596) minus the number of strata (10). The "Estimates" table displays the estimated contrast and the corresponding hypothesis test. The estimated value for the contrast is –0.75. The estimated hazard for the nonsmokers is 0.47 times the estimated hazard for the current or former smokers. In this example data set, the contrast of interest is not significant at 0.05 levels.
| Analysis of Maximum Likelihood Estimates | ||||||
|---|---|---|---|---|---|---|
| Parameter | DF | Estimate | Standard Error | t Value | Pr > |t| | Hazard Ratio |
| BodyWeight | 586 | 0.011920 | 0.003155 | 3.78 | 0.0002 | 1.012 |
| Smoke -1 | 586 | -1.174048 | 0.739450 | -1.59 | 0.1129 | 0.309 |
| Smoke 1 | 586 | -1.006515 | 0.578810 | -1.74 | 0.0826 | 0.365 |
| Smoke 2 | 586 | -0.674183 | 0.558412 | -1.21 | 0.2278 | 0.510 |
| Smoke 3 | 586 | 0 | . | . | . | 1.000 |
| Estimate | ||||||
|---|---|---|---|---|---|---|
| Label | Estimate | Standard Error | DF | t Value | Pr > |t| | Exponentiated |
| Row 1 | -0.7532 | 0.3870 | 586 | -1.95 | 0.0521 | 0.4709 |