The MULTTEST Procedure

| Statistical Tests |
The following section discusses the statistical tests performed in the MULTTEST procedure. For continuous data, a t test for the mean (MEAN) is available. For discrete variables, available tests are the Cochran-Armitage linear trend test (CA), the Freeman-Tukey double arcsine test (FT), the Peto mortality-prevalence test (PETO), and the Fisher exact test (FISHER).
Throughout this section, the discrete and continuous variables are denoted by 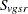 and
and 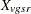 , respectively, where
, respectively, where  is the variable,
is the variable, 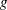 is the treatment group,
is the treatment group,  is the stratum, and
is the stratum, and  is the replication. Let
is the replication. Let 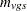 denote the sample size for a binary variable within group and stratum . A plus sign (
denote the sample size for a binary variable within group and stratum . A plus sign (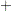 ) subscript denotes summation over an index. Note that the tests are invariant to the location and scale of the contrast coefficients
) subscript denotes summation over an index. Note that the tests are invariant to the location and scale of the contrast coefficients 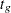 .
.
Cochran-Armitage Linear Trend Test
The Cochran-Armitage linear trend test (Cochran; 1954; Armitage; 1955; Agresti; 2002) is implemented by using a 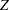 -score approximation, an exact permutation distribution, or a combination of both.
-score approximation, an exact permutation distribution, or a combination of both.
Z-Score Approximation
The pooled probability estimate for variable and stratum is
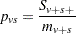 |
The expected value (under constant within-stratum treatment probabilities) for variable , group , and stratum is
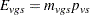 |
Letting denote the contrast trend coefficients specified by the CONTRAST statement, the test statistic for variable has numerator
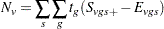 |
The binomial variance estimate for this statistic is
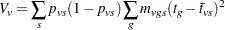 |
where
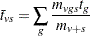 |
The hypergeometric variance estimate (the default) is
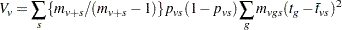 |
For any strata with 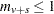 , the contribution to the variance is taken to be zero.
, the contribution to the variance is taken to be zero.
PROC MULTTEST computes the -score statistic
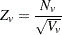 |
The p-value for this statistic comes from the standard normal distribution. Whenever a 0 is computed for the denominator, the p-value is set to 1. This p-value approximates the probability obtained from the exact permutation distribution, discussed in the following text.
The -score statistic can be continuity-corrected to better approximate the permutation distribution. With continuity correction  , the upper-tailed p-value is computed from
, the upper-tailed p-value is computed from
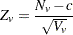 |
For two-tailed, noncontinuity-corrected tests, PROC MULTTEST reports the p-value as 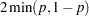 , where
, where 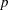 is the upper-tailed p-value. The same formula holds for the continuity-corrected test, with the exception that when the noncontinuity-corrected and the continuity-corrected have opposite signs, the two-tailed p-value is 1.
is the upper-tailed p-value. The same formula holds for the continuity-corrected test, with the exception that when the noncontinuity-corrected and the continuity-corrected have opposite signs, the two-tailed p-value is 1.
When the PERMUTATION= option is specified and no STRATA variable is specified, PROC MULTTEST uses a continuity correction selected to optimally approximate the upper-tail probability of permutation distributions with smaller marginal totals (Westfall and Lin; 1988). Otherwise, the continuity correction is specified by the CONTINUITY= option in the TEST statement.
The CA -score statistic is the Hoel-Walburg (Mantel-Haenszel) statistic reported by Dinse (1985).
Exact Permutation Test
When you use the PERMUTATION= option for CA in the TEST statement, PROC MULTTEST computes the exact permutation distribution of the trend score
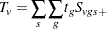 |
where the contrast trend coefficients must be integer valued. The observed value of this trend is compared to the permutation distribution to obtain the p-value
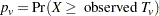 |
where 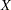 is a random variable from the permutation distribution and where upper-tailed tests are requested. This probability can be viewed as a binomial probability, where the within-stratum probabilities are constant and where the probability is conditional with respect to the marginal totals
is a random variable from the permutation distribution and where upper-tailed tests are requested. This probability can be viewed as a binomial probability, where the within-stratum probabilities are constant and where the probability is conditional with respect to the marginal totals 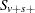 . It also can be considered a rerandomization probability.
. It also can be considered a rerandomization probability.
Because the computations can be quite time-consuming with large data sets, specifying the PERMUTATION=number option in the TEST statement limits the situations where PROC MULTTEST computes the exact permutation distribution. When marginal total success or total failure frequencies exceed number for a particular stratum, the permutation distribution is approximated by a continuity-corrected normal distribution. You should be cautious when using the PERMUTATION= option in conjunction with bootstrap resampling because the permutation distribution is recomputed for each bootstrap sample. This recomputation is not necessary with permutation resampling.
The permutation distribution is computed in two steps:
The permutation distributions of the trend scores are computed within each stratum.
The distributions are convolved to obtain the distribution of the total trend.
As long as the total success or failure frequency does not exceed number for any stratum, the computed distributions are exact. In other words, if 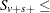 number or
number or 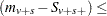 number for all , then the permutation trend distribution for variable is computed exactly.
number for all , then the permutation trend distribution for variable is computed exactly.
In step 1, the distribution of the within-stratum trend
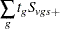 |
is computed by using the multivariate hypergeometric distribution of the 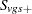 , provided number is not exceeded. This distribution can be written as
, provided number is not exceeded. This distribution can be written as
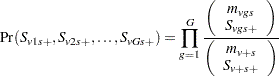 |
The distribution of the within-stratum trend is then computed by summing these probabilities over appropriate configurations. For further information about this technique, see Bickis and Krewski (1986) and Westfall and Lin (1988). In step 2, the exact convolution distribution is obtained for the trend statistic summed over all strata having totals that meet the threshold criterion. This distribution is obtained by applying the fast Fourier transform to the exact within-stratum distributions. A description of this general method can be found in Pagano and Tritchler (1983) and Good (1987).
The convolution distribution of the overall trend is then computed by convolving the exact distribution with the distribution of the continuity-corrected standard normal approximation. To be more specific, let 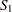 denote the subset of stratum indices that satisfy the threshold criterion, and let
denote the subset of stratum indices that satisfy the threshold criterion, and let 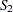 denote the subset of indices that do not satisfy the criterion. Let
denote the subset of indices that do not satisfy the criterion. Let 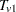 denote the combined trend statistic from the set , which has an exact distribution obtained from Fourier analysis as previously outlined, and let denote the combined trend statistic from the set . Then the distribution of the overall trend
denote the combined trend statistic from the set , which has an exact distribution obtained from Fourier analysis as previously outlined, and let denote the combined trend statistic from the set . Then the distribution of the overall trend 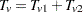 is obtained by convolving the analytic distribution of with the continuity-corrected normal approximation for
is obtained by convolving the analytic distribution of with the continuity-corrected normal approximation for 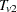 . Using the notation from the section Z-Score Approximation, this convolution can be written as
. Using the notation from the section Z-Score Approximation, this convolution can be written as
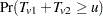 |
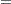 |
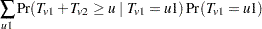 |
|||
 |
 |
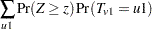 |
where is a standard normal random variable, and
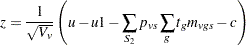 |
In this expression, the summation of in 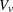 is over , and is the continuity correction discussed under the -score approximation.
is over , and is the continuity correction discussed under the -score approximation.
When a two-tailed test is requested, the expected trend is computed
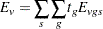 |
The two-tailed p-value is reported as the permutation tail probability for the observed trend 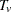 plus the permutation tail probability for
plus the permutation tail probability for 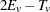 , the reflected trend.
, the reflected trend.
Freeman-Tukey Double Arcsine Test
For this test, the contrast trend coefficients 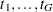 are centered to the values
are centered to the values 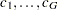 , where
, where 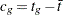 ,
, 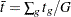 , and
, and 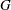 is the number of groups. The numerator of this test statistic is
is the number of groups. The numerator of this test statistic is
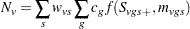 |
where the weights 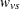 take on three different types of values depending upon your specification of the WEIGHT= option in the STRATA statement. The default value is the within-strata sample size
take on three different types of values depending upon your specification of the WEIGHT= option in the STRATA statement. The default value is the within-strata sample size 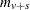 , ensuring comparability with the ordinary CA trend statistic. WEIGHT=HARMONIC sets equal to the harmonic mean
, ensuring comparability with the ordinary CA trend statistic. WEIGHT=HARMONIC sets equal to the harmonic mean
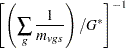 |
where 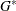 is the number of nonmissing groups and the summation is over only the nonmissing elements. The harmonic means analysis places more weight on the smaller sample sizes than does the default sample size method, and is similar to a Type 2 analysis in PROC GLM. WEIGHT=EQUAL sets
is the number of nonmissing groups and the summation is over only the nonmissing elements. The harmonic means analysis places more weight on the smaller sample sizes than does the default sample size method, and is similar to a Type 2 analysis in PROC GLM. WEIGHT=EQUAL sets 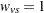 for all and , and is similar to a Type 3 analysis in PROC GLM.
for all and , and is similar to a Type 3 analysis in PROC GLM.
The function 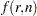 is the double arcsine transformation:
is the double arcsine transformation:
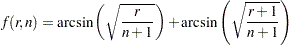 |
The variance estimate is
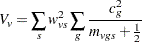 |
The test statistic is
|
The Freeman-Tukey transformation and its variance are described by Freeman and Tukey (1950) and Miller (1978). Since its variance is not weighted by the pooled probabilities, as is the CA test, the FT test can be more useful than the CA test for tests involving only a subset of the groups.
Peto Mortality-Prevalence Trend Test
The Peto test is a modified Cochran-Armitage procedure incorporating mortality and prevalence information. The Peto test is computed like two Cochran-Armitage -score approximations, one for prevalence and one for mortality (Peto, Pike, and Day; 1980). It represents a special case in PROC MULTTEST because the data structure requirements are different, and the resampling methods used for adjusting p-values are not valid. The TIME= option variable is required to specify "death" times or, more generally, times of occurrence. In addition, the test variables must assume one of the following three values:
0 = no occurrence
1 = incidental occurrence
2 = fatal occurrence
Use the TIME= option variable to define the mortality strata, and use the STRATA statement variable to define the prevalence strata.
In the following notation, the subscript represents the variable, represents the treatment group, represents the stratum, and  represents the time. Recall that a plus sign
represents the time. Recall that a plus sign 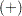 in a subscript location denotes summation over that subscript.
in a subscript location denotes summation over that subscript.
Let 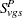 be the number of incidental occurrences, and let
be the number of incidental occurrences, and let 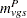 be the total sample size for variable in group , stratum , excluding fatal tumors.
be the total sample size for variable in group , stratum , excluding fatal tumors.
Let 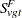 be the number of fatal occurrences in time period , and let
be the number of fatal occurrences in time period , and let 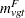 be the number of patients alive at the end of time
be the number of patients alive at the end of time 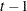 .
.
The pooled probability estimates are given by
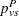 |
|
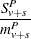 |
|||
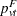 |
|
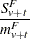 |
The expected values are
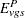 |
|
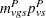 |
|||
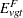 |
|
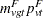 |
Let denote a contrast trend coefficient, and define the numerator terms as follows:
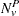 |
|
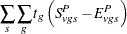 |
|||
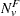 |
|
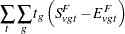 |
Define the denominator variance terms by using the binomial variance:
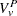 |
|
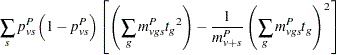 |
|||
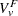 |
|
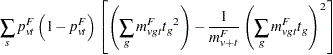 |
The hypergeometric variances (the default) are calculated by weighting the within-strata variances as discussed in the section Z-Score Approximation.
The Peto statistic is computed as
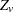 |
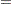 |
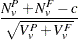 |
where is a continuity correction. The p-value is determined from the standard normal distribution unless the PERMUTATION=number option is used. When you use the PERMUTATION= option for PETO in the TEST statement, PROC MULTTEST computes the "discrete approximation" permutation distribution described by Mantel (1980) and Soper and Tonkonoh (1993). Specifically, the permutation distribution of 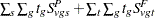 is computed, assuming that
is computed, assuming that 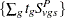 and
and 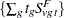 are independent over all and . Note that the contrast trend coefficients must be integer valued. The p-values are exact under this independence assumption. However, the independence assumption is valid only asymptotically, which is why these p-values are called "approximate."
are independent over all and . Note that the contrast trend coefficients must be integer valued. The p-values are exact under this independence assumption. However, the independence assumption is valid only asymptotically, which is why these p-values are called "approximate."
An exact permutation distribution is available only under the assumption of equal risk of censoring in all treatment groups; even then, computing this distribution can be cumbersome. Soper and Tonkonoh (1993) describe situations where the discrete approximation distribution closely fits the exact permutation distribution.
Fisher Exact Test
The CONTRAST statement in PROC MULTTEST enables you to compute Fisher exact tests for two-group comparisons. No stratification variable is allowed for this test. Note, however, that the FISHER exact test is a special case of the exact permutation tests performed by PROC MULTTEST and that these permutation tests allow a stratification variable. Recall that contrast coefficients can be 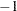 ,
, 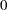 , or
, or  for the Fisher test. The frequencies and sample sizes of the groups scored as are combined, as are the frequencies and sample sizes of the groups scored as . Groups scored as are excluded. The group is then compared with the group by using the Fisher exact test.
for the Fisher test. The frequencies and sample sizes of the groups scored as are combined, as are the frequencies and sample sizes of the groups scored as . Groups scored as are excluded. The group is then compared with the group by using the Fisher exact test.
Letting  and
and  denote the frequency and sample size of the group, and letting
denote the frequency and sample size of the group, and letting 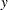 and
and  denote those of the group, the p-value is calculated as
denote those of the group, the p-value is calculated as
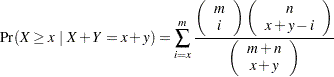 |
where and 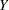 are independent binomially distributed random variables with sample sizes and and common probability parameters. The hypergeometric distribution is used to determine the stated probability; Yates (1984) discusses this technique. PROC MULTTEST computes the two-tailed p-values by adding probabilities from both tails of the hypergeometric distribution. The first tail is from the observed and , and the other tail is chosen so that the resulting probability is as large as possible without exceeding the probability from the first tail. If the variable being tested has only one level, then the p-value is set to 1.
are independent binomially distributed random variables with sample sizes and and common probability parameters. The hypergeometric distribution is used to determine the stated probability; Yates (1984) discusses this technique. PROC MULTTEST computes the two-tailed p-values by adding probabilities from both tails of the hypergeometric distribution. The first tail is from the observed and , and the other tail is chosen so that the resulting probability is as large as possible without exceeding the probability from the first tail. If the variable being tested has only one level, then the p-value is set to 1.
t Test for the Mean
For continuous variables, PROC MULTTEST automatically centers the contrast trend coefficients, as in the Freeman-Tukey test. These centered coefficients 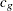 are then used to form a t statistic contrasting the within-group means. Let
are then used to form a t statistic contrasting the within-group means. Let 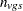 denote the sample size within group and stratum ; it depends on variable only when there are missing values. Determine the weights as in the Freeman-Tukey test with replacing . Define
denote the sample size within group and stratum ; it depends on variable only when there are missing values. Determine the weights as in the Freeman-Tukey test with replacing . Define
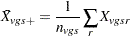 |
as the sample mean within a group-and-stratum combination, and let 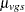 denote the treatment means. Write the null hypothesis as
denote the treatment means. Write the null hypothesis as
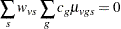 |
Also define
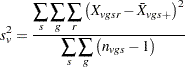 |
as the pooled sample variance.
Homogeneous Variance
Assuming constant variance for all group-and-stratum combinations, the t statistic for the mean is
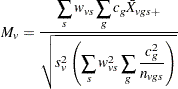 |
Then under the null hypothesis and assuming normality, independence, and homoscedasticity, 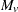 follows a t distribution with
follows a t distribution with 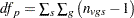 degrees of freedom.
degrees of freedom.
Whenever a denominator of 0 is computed, the p-value is set to 1. When missing data force 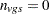 , the contribution to the denominator of the pooled variance is 0 and not . This is also true for the degrees of freedom.
, the contribution to the denominator of the pooled variance is 0 and not . This is also true for the degrees of freedom.
Heterogeneous Variance
If you do not assume constant variance for all group-and-stratum combinations, then the approximate t test is
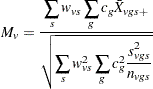 |
Under the null hypothesis and assuming normality and independence, the Satterthwaite (1946) approximation for the degrees of freedom of the t test is given by
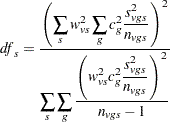 |
under the restriction 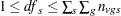 .
.
Whenever a denominator of 0 for is computed, the p-value is set to 1. If the denominator for 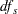 is computed as 0, then set
is computed as 0, then set 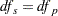 . When missing data force , that group-and-stratum combination does not contribute to the computation.
. When missing data force , that group-and-stratum combination does not contribute to the computation.