The GLMSELECT Procedure
-
Overview

- Getting Started
-
Syntax
-
Details
Model-Selection Methods Model Selection Issues Criteria Used in Model Selection Methods CLASS Variable Parameterization and the SPLIT Option Macro Variables Containing Selected Models Using the STORE Statement Building the SSCP Matrix Model Averaging Using Validation and Test Data Cross Validation Displayed Output ODS Table Names ODS Graphics
-
Examples
- References
| Using Validation and Test Data |
When you have sufficient data, you can subdivide your data into three parts called the training, validation, and test data. During the selection process, models are fit on the training data, and the prediction error for the models so obtained is found by using the validation data. This prediction error on the validation data can be used to decide when to terminate the selection process or to decide what effects to include as the selection process proceeds. Finally, once a selected model has been obtained, the test set can be used to assess how the selected model generalizes on data that played no role in selecting the model.
In some cases you might want to use only training and test data. For example, you might decide to use an information criterion to decide what effects to include and when to terminate the selection process. In this case no validation data are required, but test data can still be useful in assessing the predictive performance of the selected model. In other cases you might decide to use validation data during the selection process but forgo assessing the selected model on test data. Hastie, Tibshirani, and Friedman (2001) note that it is difficult to give a general rule on how many observations you should assign to each role. They note that a typical split might be 50% for training and 25% each for validation and testing.
PROC GLMSELECT provides several methods for partitioning data into training, validation, and test data. You can provide data for each role in separate data sets that you specify with the DATA=, TESTDATA=, and VALDATA= options in the PROC GLMSELECT procedure. An alternative method is to use a PARTITION statement to logically subdivide the DATA= data set into separate roles. You can name the fractions of the data that you want to reserve as test data and validation data. For example, specifying
proc glmselect data=inData; partition fraction(test=0.25 validate=0.25); ... run;
randomly subdivides the "inData" data set, reserving 50% for training and 25% each for validation and testing.
In some cases you might need to exercise more control over the partitioning of the input data set. You can do this by naming a variable in the input data set as well as a formatted value of that variable that correspond to each role. For example, specifying
proc glmselect data=inData; partition roleVar=group(test='group 1' train='group 2') ... run;
assigns all roles observations in the "inData" data set based on the value of the variable named group in that data set. Observations where the value of group is ’group 1’ are assigned for testing, and those with value ’group 2’ are assigned to training. All other observations are ignored.
You can also combine the use of the PARTITION statement with named data sets for specifying data roles. For example,
proc glmselect data=inData testData=inTest; partition fraction(validate=0.4); ... run;
reserves 40% of the "inData" data set for validation and uses the remaining 60% for training. Data for testing is supplied in the "inTest" data set. Note that in this case, because you have supplied a TESTDATA= data set, you cannot reserve additional observations for testing with the PARTITION statement.
When you use a PARTITION statement, the output data set created with an OUTPUT statement contains a character variable _ROLE_ whose values "TRAIN," "TEST," and "VALIDATE" indicate the role of each observation. _ROLE_ is blank for observations that were not assigned to any of these three roles. When the input data set specified in the DATA= option in the PROC GLMSELECT statement contains an _ROLE_ variable and no PARTITION statement is used, and TESTDATA= and VALDATA= are not specified, then the _ROLE_ variable is used to define the roles of each observation. This is useful when you want to rerun PROC GLMSELECT but use the same data partitioning as in a previous PROC GLMSELECT step. For example, the following statements use the same data for testing and training in both PROC GLMSELECT steps:
proc glmselect data=inData; partition fraction(test=0.5); model y=x1-x10/selection=forward; output out=outDataForward; run; proc glmselect data=outDataForward; model y=x1-x10/selection=backward; run;
When you have reserved observations for training, validation, and testing, a model fit on the training data is scored on the validation and test data, and the average squared error, denoted by ASE, is computed separately for each of these subsets. The ASE for each data role is the error sum of squares for observations in that role divided by the number of observations in that role.
Using the Validation ASE as the STOP= Criterion
If you have provided observations for validation, then you can specify STOP=VALIDATE as a suboption of the SELECTION= option in the MODEL statement. At step 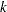 of the selection process, the best candidate effect to enter or leave the current model is determined. Note that here "best candidate" means the effect that gives the best value of the SELECT= criterion that need not be based on the validation data. The validation ASE for the model with this candidate effect added is computed. If this validation ASE is greater than the validation ASE for the model at step , then the selection process terminates at step .
of the selection process, the best candidate effect to enter or leave the current model is determined. Note that here "best candidate" means the effect that gives the best value of the SELECT= criterion that need not be based on the validation data. The validation ASE for the model with this candidate effect added is computed. If this validation ASE is greater than the validation ASE for the model at step , then the selection process terminates at step .
Using the Validation ASE as the CHOOSE= Criterion
When you specify the CHOOSE=VALIDATE suboption of the SELECTION= option in the MODEL statement, the validation ASE is computed for the models at each step of the selection process. The model at the first step yielding the smallest validation ASE is selected.
Using the Validation ASE as the SELECT= Criterion
You request the validation ASE as the selection criterion by specifying the SELECT=VALIDATE suboption of the SELECTION= option in the MODEL statement. At step of the selection process, the validation ASE is computed for each model where a candidate for entry is added or candidate for removal is dropped. The selected candidate for entry or removal is the one that yields a model with the minimal validation ASE.