The GLMSELECT Procedure
-
Overview

- Getting Started
-
Syntax
-
Details
Model-Selection Methods Model Selection Issues Criteria Used in Model Selection Methods CLASS Variable Parameterization and the SPLIT Option Macro Variables Containing Selected Models Using the STORE Statement Building the SSCP Matrix Model Averaging Using Validation and Test Data Cross Validation Displayed Output ODS Table Names ODS Graphics
-
Examples
- References
| MODEL Statement |
- MODEL dependent=<effects> / <options> ;
The MODEL statement names the dependent variable and the explanatory effects, including covariates, main effects, constructed effects, interactions, and nested effects; see the section Specification of Effects in Chapter 41, The GLM Procedure, for more information. If you omit the explanatory effects, the procedure fits an intercept-only model.
After the keyword MODEL, the dependent (response) variable is specified, followed by an equal sign. The explanatory effects follow the equal sign.
Table 44.3 lists the options available in the MODEL statement.
Option |
Description |
|---|---|
Requests details when cross validation is used |
|
Specifies how subsets for cross validation are formed |
|
Specifies details to be displayed |
|
Specifies the hierarchy of effects to impose |
|
Specifies models without an explicit intercept |
|
Requests that parameter estimates be displayed in the order in which the parameters first entered the model |
|
Specifies the model selection method |
|
Specifies additional statistics to be displayed |
|
Requests |
|
Adds standardized coefficients to "Parameter Estimates" tables |
You can specify the following options in the MODEL statement after a slash (/):
- CVDETAILS=ALL
- CVDETAILS=COEFFS
- CVDETAILS=CVPRESS
specifies the details produced when cross validation is requested as the CHOOSE=, SELECT=, or STOP= criterion in the MODEL statement. If
 -fold cross validation is being used, then the training data are subdivided into parts, and at each step of the selection process, models are obtained on each of the subsets of the data obtained by omitting one of these parts. CVDETAILS=COEFFS requests that the parameter estimates obtained for each of these subsets be included in the parameter estimates table. CVDETAILS=CVPRESS requests a table containing the predicted residual sum of squares of each of these models scored on the omitted subset. CVDETAILS=ALL requests both CVDETAILS=COEFFS and CVDETAILS=CVPRESS. If DETAILS=STEPS or DETAILS=ALL has been specified in the MODEL statement, then the requested CVDETAILS are produced for every step of the selection process.
-fold cross validation is being used, then the training data are subdivided into parts, and at each step of the selection process, models are obtained on each of the subsets of the data obtained by omitting one of these parts. CVDETAILS=COEFFS requests that the parameter estimates obtained for each of these subsets be included in the parameter estimates table. CVDETAILS=CVPRESS requests a table containing the predicted residual sum of squares of each of these models scored on the omitted subset. CVDETAILS=ALL requests both CVDETAILS=COEFFS and CVDETAILS=CVPRESS. If DETAILS=STEPS or DETAILS=ALL has been specified in the MODEL statement, then the requested CVDETAILS are produced for every step of the selection process. - CVMETHOD=BLOCK <(n)>
- CVMETHOD=RANDOM <(n)>
- CVMETHOD=SPLIT <(n)>
- CVMETHOD=INDEX (variable)
-
specifies how the training data are subdivided into
parts when you request -fold cross validation by using any of the CHOOSE=CV, SELECT=CV, and STOP=CV suboptions of the SELECTION= option in the MODEL statement. CVMETHOD=BLOCK requests that parts be formed of
blocks of consecutive training observations. CVMETHOD=SPLIT requests that the ith part consist of training observations
 .
. CVMETHOD=RANDOM assigns each training observation randomly to one of the
parts. CVMETHOD=INDEX(variable) assigns observations to parts based on the formatted value of the named variable. This input data set variable is treated as a classification variable and the number of parts
is the number of distinct levels of this variable. By optionally naming this variable in a CLASS statement you can use the CLASS statement options ORDER= and MISSING to control how the levelization of this variable is done.
defaults to 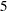 with CVMETHOD=BLOCK, CVMETHOD=SPLIT, or CVMETHOD=RANDOM. If you do not specify the CVMETHOD= option, then the CVMETHOD defaults to CVMETHOD=RANDOM(5).
with CVMETHOD=BLOCK, CVMETHOD=SPLIT, or CVMETHOD=RANDOM. If you do not specify the CVMETHOD= option, then the CVMETHOD defaults to CVMETHOD=RANDOM(5). - DETAILS=level
- DETAILS=STEPS <(step options)>
-
specifies the level of detail produced, where level can be ALL, STEPS, or SUMMARY. The default if the DETAILS= option is omitted is DETAILS=SUMMARY. The DETAILS=ALL option produces the following:
entry and removal statistics for each variable selected in the model building process
ANOVA, fit statistics, and parameter estimates
entry and removal statistics for the top 10 candidates for inclusion or exclusion at each step
a selection summary table
The DETAILS=SUMMARY option produces only the selection summary table.
The option DETAILS=STEPS <(step options)> provides the step information and the selection summary table. The following options can be specified within parentheses after the DETAILS=STEPS option:
- ALL
requests ANOVA, fit statistics, parameter estimates, and entry or removal statistics for the top 10 candidates for inclusion or exclusion at each selection step.
- ANOVA
- FITSTATISTICS | FITSTATS | FIT
requests fit statistics at each selection step. The default set of statistics includes all of the statistics named in the CHOOSE=, SELECT=, and STOP= suboptions specified in the MODEL statement SELECTION= option, but additional statistics can be requested with the STATS= option in the MODEL statement.
- PARAMETERESTIMATES | PARMEST
- CANDIDATES <(SHOW= ALL | n)>
requests entry or removal statistics for the best n candidate effects for inclusion or exclusion at each step. If you specify SHOW=ALL, then all candidates are shown. If SHOW= is not specified. then the best 10 candidates are shown. The entry or removal statistic is the statistic named in the SELECT= option that is specified in the MODEL statement SELECTION= option.
- HIERARCHY=keyword
- HIER=keyword
-
specifies whether and how the model hierarchy requirement is applied. This option also controls whether a single effect or multiple effects are allowed to enter or leave the model in one step. You can specify that only classification effects, or both classification and continuous effects, be subject to the hierarchy requirement. The HIERARCHY= option is ignored unless you also specify one of the following options: SELECTION=FORWARD, SELECTION=BACKWARD, or SELECTION=STEPWISE.
Model hierarchy refers to the requirement that for any term to be in the model, all model effects contained in the term must be present in the model. For example, in order for the interaction A*B to enter the model, the main effects A and B must be in the model. Likewise, neither effect A nor effect B can leave the model while the interaction A*B is in the model.
The keywords you can specify in the HIERARCHY= option are as follows:
- NONE
specifies that model hierarchy not be maintained. Any single effect can enter or leave the model at any given step of the selection process.
- SINGLE
-
specifies that only one effect enter or leave the model at one time, subject to the model hierarchy requirement. For example, suppose that the model contains the main effects A and B and the interaction A*B. In the first step of the selection process, either A or B can enter the model. In the second step, the other main effect can enter the model. The interaction effect can enter the model only when both main effects have already entered. Also, before A or B can be removed from the model, the A*B interaction must first be removed. All effects (CLASS and interval) are subject to the hierarchy requirement.
- SINGLECLASS
is the same as HIERARCHY=SINGLE except that only CLASS effects are subject to the hierarchy requirement.
The default value is HIERARCHY=NONE.
- NOINT
suppresses the intercept term that is otherwise included in the model.
- ORDERSELECT
specifies that for the selected model, effects be displayed in the order in which they first entered the model. If you do not specify the ORDERSELECT option, then effects in the selected model are displayed in the order in which they appeared in the MODEL statement.
- SELECTION=method <(method options)>
-
specifies the method used to select the model, optionally followed by parentheses enclosing options applicable to the specified method. The default if the SELECTION= option is omitted is SELECTION=STEPWISE.
The following methods are available and are explained in detail in the section Model-Selection Methods.
- NONE
no model selection
- FORWARD
forward selection. This method starts with no effects in the model and adds effects.
- BACKWARD
backward elimination. This method starts with all effects in the model and deletes effects.
- STEPWISE
stepwise regression. This is similar to the FORWARD method except that effects already in the model do not necessarily stay there.
- LAR
least angle regression. This method, like forward selection, starts with no effects in the model and adds effects. The parameter estimates at any step are "shrunk" when compared to the corresponding least squares estimates. If the model contains classification variables, then these classification variables are split. See the SPLIT option in the CLASS statement for details.
- LASSO
This method adds and deletes parameters based on a version of ordinary least squares where the sum of the absolute regression coefficients is constrained. If the model contains classification variables, then these classification variables are split. See the SPLIT option in the CLASS statement for details.
Table 44.4 lists the applicable suboptions for each of these methods.
Table 44.4 Applicable SELECTION= Options by Method Option
FORWARD
BACKWARD
STEPWISE
LAR LASSO
STOP =
x
x
x
x
CHOOSE =
x
x
x
x
STEPS =
x
x
x
x
MAXSTEPS =
x
x
x
x
SELECT =
x
x
x
INCLUDE =
x
x
x
SLENTRY =
x
x
SLSTAY =
x
x
DROP =
x
ADAPTIVE
x
LSCOEFFS
x
The syntax of the suboptions that you can specify in parentheses after the SELECTION= option method follows. Note that, as described in Table 44.4, not all selection suboptions are applicable to every SELECTION= method.
- ADAPTIVE <(<GAMMA=non-negative number> <INEST=SAS-data-set> )>
requests that adaptive weights be applied to each of the coefficients in the LAR and LASSO methods. You use the optional INEST= option to name the SAS data set that contains estimates which are used to form the adaptive weights for all the parameters in the model. If you do not specify an INEST= data set, then ordinary least squares estimates of the parameters in the model are used in forming the adaptive weights. You use the GAMMA= option to specify the power transformation that is applied to the parameters in forming the adaptive weights. The default value is GAMMA=1.
- CHOOSE=criterion
-
chooses from the list of models at the steps of the selection process the model that yields the best value of the specified criterion. If the optimal value of the specified criterion occurs for models at more than one step, then the model with the smallest number of parameters is chosen. If you do not specify the CHOOSE= option, then the model selected is the model at the final step in the selection process.
The criteria that you can specify in the CHOOSE= option are shown in Table 44.5. See the section Criteria Used in Model Selection Methods for more detailed descriptions of these criteria.
Table 44.5 Criteria for the CHOOSE= Option Option
Criteria
ADJRSQ
Adjusted R-square statistic
AIC
Akaike’s information criterion
AICC
Corrected Akaike’s information criterion
BIC
Sawa Bayesian information criterion
CP
Mallows C(p) statistic
CV
Predicted residual sum of square with
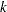 -fold cross validation
-fold cross validation PRESS
Predicted residual sum of squares
SBC
Schwarz Bayesian information criterion
VALIDATE
Average square error for the validation data
For ADJRSQ the chosen value is the largest one; for all other criteria, the smallest value is chosen. You can use the VALIDATE option only if you have specified a VALDATA= data set in the PROC GLMSELECT statement or if you have reserved part of the input data for validation by using either a PARTITION statement or a _ROLE_ variable in the input data.
- DROP=policy
-
specifies when effects are eligible to be dropped in the STEPWISE method. Valid values for policy are BEFOREADD and COMPETITIVE.
If you specify DROP=BEFOREADD, then effects currently in the model are examined to see if any meet the requirements to be removed from the model. If so, the effect that gives the best value of the removal criterion is dropped from the model and the stepwise method proceeds to the next step. Only when no effect currently in the model meets the requirement to be removed from the model are any effects added to the model.
DROP=COMPETITIVE can be specified only if the SELECT= criterion is not SL. If you specify DROP=COMPETITIVE, then the SELECT= criterion is evaluated for all models where an effect currently in the model is dropped or an effect not yet in the model is added. The effect whose removal or addition to the model yields the maximum improvement to the SELECT= criterion is dropped or added.
The default if you do not specify DROP= suboption with the STEPWISE method is DROP=BEFOREADD. If SELECT=SL, then this yields the traditional stepwise method as implemented in PROC REG.
- INCLUDE=n
forces the first n effects listed in the MODEL statement to be included in all models. The selection methods are performed on the other effects in the MODEL statement. The INCLUDE= option is available only with SELECTION=FORWARD, SELECTION=STEPWISE, and SELECTION=BACKWARD.
- LSCOEFFS
requests a hybrid version of the LAR and LASSO methods, where the sequence of models is determined by the LAR or LASSO algorithm but the coefficients of the parameters for the model at any step are determined by using ordinary least squares.
- MAXSTEP=n
specifies the maximum number of selection steps that are done. The default value of n is the number of effects in the model statement for the FORWARD, BACKWARD, and LAR methods and is three times the number of effects for the STEPWISE and LASSO methods.
- SELECT=criterion
specifies the criterion that PROC GLMSELECT uses to determine the order in which effects enter and/or leave at each step of the specified selection method. The SELECT option is not valid with the LAR and LASSO methods. The criteria that you can specify with the SELECT= option are ADJRSQ, AIC, AICC, BIC, CP, CV, PRESS, RSQUARE, SBC, SL, and VALIDATE. See the section Criteria Used in Model Selection Methods for a description of these criteria. The default value of the SELECT= criterion is SELECT=SBC. You can use SELECT=SL to request the traditional approach where effects enter and leave the model based on the significance level. With other SELECT= criteria, the effect that is selected to enter or leave at a step of the selection process is the effect whose addition to or removal from the current model gives the maximum improvement in the specified criterion.
- SLENTRY=value
- SLE=value
specifies the significance level for entry, used when the STOP=SL or SELECT=SL option is in effect. The defaults are 0.50 for FORWARD and 0.15 for STEPWISE.
- SLSTAY=value
- SLS=value
specifies the significance level for staying in the model, used when the STOP=SL or SELECT=SL option is in effect. The defaults are 0.10 for BACKWARD and 0.15 for STEPWISE.
- STEPS=n
specifies the number of selection steps to be done. If the STEPS= option is specified, the STOP= and MAXSTEP= options are ignored.
- STOP=n
- STOP=criterion
-
specifies when PROC GLMSELECT stops the selection process. If the STEPS= option is specified, then the STOP= option is ignored. If the STOP=option does not cause the selection process to stop before the maximum number of steps for the selection method, then the selection process terminates at the maximum number of steps.
If you do not specify the STOP= option but do specify the SELECT= option, then the criterion named in the SELECT=option is also used as the STOP= criterion. If you do not specify either the STOP= or SELECT= option, then the default is STOP=SBC.
If STOP=n is specified, then PROC GLMSELECT stops selection at the first step for which the selected model has n effects.
The nonnumeric arguments that you can specify in the STOP= option are shown in Table 44.6. See the section Criteria Used in Model Selection Methods for more detailed descriptions of these criteria.
Table 44.6 Nonnumeric Criteria for the STOP= Option Option
Criteria
NONE
ADJRSQ
Adjusted R-square statistic
AIC
Akaike’s information criterion
AICC
Corrected Akaike’s information criterion
BIC
Sawa Bayesian information criterion
CP
Mallows C(p) statistic
CV
Predicted residual sum of square with
-fold cross validation PRESS
Predicted residual sum of squares
SBC
Schwarz Bayesian information criterion
SL
Significance level
VALIDATE
Average square error for the validation data
With the SL criterion, selection stops at the step where the significance level for entry of all the effects not yet in the model is greater than the SLE= value for addition steps in the FORWARDS and STEPWISE methods and where the significance level for removal of any effect in the current model is greater than the SLS= value in the BACKWARD and STEPWISE methods. With the ADJRSQ criterion, selection stops at the step where the next step would yield a model with a smaller value of the Adjusted R-square statistic; for all other criteria, selection stops at the step where the next step would yield a model with a larger value of the criteria. You can use the VALIDATE option only if you have specified a VALDATA= data set in the PROC GLMSELECT statement or if you have reserved part of the input data for validation by using either a PARTITION statement or a _ROLE_ variable in the input data.
- STAT|STATS=name
- STATS=(names)
-
specifies which model fit statistics are displayed in the fit summary table and fit statistics tables. If you omit the STATS= option, the default set of statistics that are displayed in these tables includes all the criteria specified in any of the CHOOSE=, SELECT=, and STOP= options specified in the MODEL statement SELECTION= option.
The statistics that you can specify follow:
- ADJRSQ
- AIC
- AICC
- ASE
the average square errors for the training, test, and validation data. The ASE statistics for the test and validation data are reported only if you have specified TESTDATA= and/or VALDATA= in the PROC GLMSELECT statement or if you have reserved part of the input data for testing and/or validation by using either a PARTITION statement or a _ROLE_ variable in the input data.
- BIC
- CP
- FVALUE
- PRESS
- RSQUARE
- SBC
- SL
the significance level of the
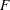 statistic for entering or departing effects
statistic for entering or departing effects
The statistics ADJRSQ, AIC, AICC, FVALUE, RSQUARE, SBC, and SL can be computed with little computation cost. However, computing BIC, CP, CVPRESS, PRESS, and ASE for test and validation data when these are not used in any of the CHOOSE=, SELECT=, and STOP= options specified in the MODEL statement SELECTION= option can hurt performance.
- SHOWPVALUES
- SHOWPVALS
displays
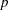 -values in the "ANOVA" and "Parameter Estimates" tables. These -values are generally liberal because they are not adjusted for the fact that the terms in the model have been selected.
-values in the "ANOVA" and "Parameter Estimates" tables. These -values are generally liberal because they are not adjusted for the fact that the terms in the model have been selected. - STB
produces standardized regression coefficients. A standardized regression coefficient is computed by dividing a parameter estimate by the ratio of the sample standard deviation of the dependent variable to the sample standard deviation of the regressor.