| The MCMC Procedure |
| MODEL Statement |
- MODEL dependent-variable-list
 distribution ;
distribution ;
The MODEL statement is used to specify the conditional distribution of the data given the parameters (the likelihood function). You must specify a single dependent variable or a list of dependent variables, a tilde  , and then a distribution with its arguments. The dependent variables can be variables from the input data set or functions of the symbols in the program. The dependent variables must be specified unless the functions GENERAL or DGENERAL are used (see the section Specifying a New Distribution for more details). Multiple MODEL statements are allowed for defining models with multiple independent components. The log likelihood value is the sum of the log likelihood values from each MODEL statement.
, and then a distribution with its arguments. The dependent variables can be variables from the input data set or functions of the symbols in the program. The dependent variables must be specified unless the functions GENERAL or DGENERAL are used (see the section Specifying a New Distribution for more details). Multiple MODEL statements are allowed for defining models with multiple independent components. The log likelihood value is the sum of the log likelihood values from each MODEL statement.
PROC MCMC is a programming language that is similar to the DATA step, and the order of statement evaluation is important. For example, the MODEL statement must come after any SAS programming statements that define or modify arguments used in the construction of the log likelihood. In PROC MCMC, a symbol is allowed to be defined multiple times and used at different places. Using an expression out of order produces erroneous results that can also be hard to detect.
Standard distributions that the MODEL statement supports are listed in the Table 52.2 (see the section Standard Distributions for density specification). These distributions can also be used in the PRIOR and HYPERPRIOR statements. PROC MCMC allows some distributions to be parameterized in multiple ways. For example, you can specify a normal distribution with variance (VAR=), standard deviation (SD=), or precision (PRECISION=) parameter. For distributions that have different parameterizations, you must specify an option to clearly name the ambiguous parameter. In the normal distribution, for example, you must indicate whether the second argument is a variance, a standard deviation, or a precision.
All distributions, with the exception of binary and uniform, can have the optional arguments of LOWER= and UPPER=, which specify a truncated density. See the section Truncation and Censoring for more details.
Distribution Name |
Definition |
|---|---|
beta(<a=> |
beta distribution with shape parameters |
binary(<prob|p=> |
binary (Bernoulli) distribution with probability of success |
binomial (<n=> |
binomial distribution with count |
cauchy (<location|loc|l=> |
Cauchy distribution with location |
chisq(<df=> |
|
dgeneral(ll) |
general log-likelihood function that you construct using SAS programming statements for single or multiple discrete variables. Also see the function general. The name dlogden is an alias for this function. |
expchisq(<df=> |
log transformation of a |
log transformation of an exponential distribution with scale or inverse-scale parameter |
|
expGamma(<shape|sp=> a, scale|s= |
log transformation of a gamma distribution with shape |
expichisq(<df=> |
log transformation of an inverse |
expiGamma(<shape|sp=> a, scale|s= |
log transformation of an inverse-gamma distribution with shape |
expsichisq(<df=> |
log transformation of a scaled inverse |
exponential distribution with scale or inverse-scale parameter |
|
gamma(<shape|sp=> a, scale|s= |
gamma distribution with shape |
geo(<prob|p=> |
geometric distribution with probability |
general(ll) |
general log likelihood function that you construct using SAS programming statements for a single or multiple continuous variables. The argument ll is an expression for the log of the distribution. If there are multiple variables specified before the tilde in a MODEL, PRIOR, or HYPERPRIOR statement, ll is interpreted as the log of the joint distribution for these variables. Note that in the MODEL statement, the response variable specified before the tilde is just a place holder and is of no consequence; the variable must have appeared in the construction of ll in the programming statements. general(constant) is equivalent to a uniform distribution on the real line. You can use the alias logden for this distribution. |
ichisq(<df=> |
inverse |
igamma(<shape|sp=> a, scale|s= |
inverse-gamma distribution with shape |
laplace(<location|loc|l=> |
Laplace distribution with location |
logistic(<location|loc|l=> |
logistic distribution with location |
lognormal(<mean|m=> |
log-normal distribution with mean |
negbin(<n=> |
negative binomial distribution with count |
normal(<mean|m=> |
normal (Gaussian) distribution with mean |
pareto(<shape|sp=> |
Pareto distribution with shape |
poisson(<mean|m=> |
Poisson distribution with mean |
sichisq(<df=> |
scaled inverse |
t(<mean|m=> |
|
uniform(<left|l=> |
uniform distribution with range |
wald(<mean|m=> |
Wald distribution with mean parameter |
weibull( |
Weibull distribution with location (threshold) parameter |
 , <b=>
, <b=>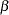 )
)  )
)  , <prob|p=>
, <prob|p=>  , <scale|s=>
, <scale|s=> )
)  )
) 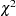 distribution with
distribution with 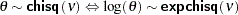 . You can use the alias echisq for this distribution.
. You can use the alias echisq for this distribution. 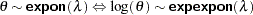 . You can use the alias eexpon for this distribution.
. You can use the alias eexpon for this distribution.  and scale or inverse-scale
and scale or inverse-scale  . You can use the alias egamma for this distribution.
. You can use the alias egamma for this distribution. 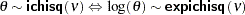 . You can use the alias eichisq for this distribution.
. You can use the alias eichisq for this distribution.  . You can use the alias eigamma for this distribution.
. You can use the alias eigamma for this distribution.  )
) 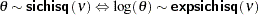 . You can use the alias esichisq for this distribution.
. You can use the alias esichisq for this distribution.  )
)  , sd=
, sd=  distribution with mean
distribution with mean 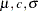 )
)  , and scale parameter
, and scale parameter  .
. Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.