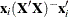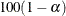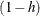The HPREG Procedure

OUTPUT Statement
-
OUTPUT <OUT=SAS-data-set><COPYVARS=(variables)><keyword <=name>>…<keyword <=name>> ;
The OUTPUT statement creates a data set that contains observationwise statistics, which are computed after fitting the model. The variables in the input data set are not included in the output data set to avoid data duplication for large data sets; however, variables specified in the ID statement or COPYVARS= option are included.
If the input data are in distributed form, where access of data in a particular order cannot be guaranteed, the HPREG procedure copies the distribution or partition key to the output data set so that its contents can be joined with the input data.
The output statistics are computed based on the parameter estimates for the selected model.
You can specify the following syntax elements in the OUTPUT statement:
In addition to the preceding statistics, you can also use the keywords listed in Table 15.4 in the OUTPUT statement to obtain additional statistics. These statistics are not available if you use METHOD=LAR or METHOD=LASSO in the SELECTION statement, unless you also specify the LSCOEFFS option. See the section Diagnostic Statistics for computational formulas. All the statistics available in the OUTPUT statement are conditional on the selected model and do not take into account the variability introduced by doing model selection.
Table 15.4: Keywords for OUTPUT Statement
|
Keyword |
Description |
|---|---|
|
COOKD |
Cook’s D influence statistic |
|
COVRATIO |
Standard influence of observation on covariance of betas |
|
DFFIT |
Standard influence of observation on predicted value |
|
H |
Leverage, |
|
LCL |
Lower bound of a |
|
LCLM |
Lower bound of a |
|
PRESS |
ith residual divided by |
|
RSTUDENT |
A studentized residual with the current observation deleted |
|
STDI |
Standard error of the individual predicted value |
|
STDP |
Standard error of the mean predicted value |
|
STDR |
Standard error of the residual |
|
STUDENT |
Studentized residuals, which are the residuals divided by their |
|
UCL |
Upper bound of a |
|
UCLM |
Upper bound of a |