The HPSPLIT Procedure

The PROC HPSPLIT statement invokes the procedure. Table 15.2 summarizes the options in the PROC HPSPLIT statement.
Table 15.2: PROC HPSPLIT Statement Options
|
Option |
Description |
|---|---|
|
Basic Options |
|
|
Specifies the input data set |
|
|
Specifies the formatted value of the target event (decision trees) |
|
|
Specifies the number of bins for interval variables |
|
|
Sets the minimum variance for a regression tree leaf to be split |
|
|
Specifies the number of surrogate rules to create |
|
|
Specifies that variables should be split only once per branch |
|
|
Splitting Options |
|
|
Specifies the minimum number of observations per leaf |
|
|
Specifies the maximum leaves per node |
|
|
Specifies the maximum tree depth |
|
|
Specifies the number of observations per level to consider a level for splitting |
|
|
Specifies how to handle missing values in an input variable |
|
|
FastCHAID and chi-square Options |
|
|
Specifies the maximum p-value for a split to be considered |
|
|
Enables the Bonferroni adjustment to after-split p-values |
|
|
F Test Options |
|
|
Specifies the maximum p-value for a split to be considered |
|
|
FastCHAID Options |
|
|
Specifies the minimum Kolmogorov-Smirnov distance |
|
You can specify the following options:
- ALPHA=number
-
specifies the maximum p-value for a split to be considered if you specify FASTCHAID, CHISQUARE, or FTEST in the CRITERION statement. Otherwise, this option is ignored.
By default, ALPHA=0.3.
- BONFERRONI
-
enables the Bonferroni adjustment to the p-value of each variable’s split after the split has been determined by the Kolmogorov-Smirnov distance or chi-squared value if you specify FASTCHAID or CHISQUARE in the CRITERION statement. Otherwise, this option is ignored.
By default, there is no Bonferroni adjustment.
- DATA=SAS-data-set
-
names the input SAS data set to be used by PROC HPSPLIT. The default is the most recently created data set.
If the procedure executes in distributed mode, the input data are distributed to memory on the appliance nodes and analyzed in parallel, unless the data are already distributed in the appliance database. In that case the procedure reads the data alongside the distributed database. See the section Processing Modes about the various execution modes and the section Alongside-the-Database Execution about the alongside-the-database model. Both sections are in Chapter 3: Shared Concepts and Topics.
- EVENT='value'
-
specifies a formatted value of the target level variable to use for sorting nominal input levels when PROC HPSPLIT uses the fastest splitting category. (FastCHAID always uses the fastest splitting category.) Ties are broken in internal order.
See section Input Variable Splitting and Selection for details on splitting categories and the FastCHAID criterion.
The default is the first level of the target as specified by the ORDER= option in the TARGET statement.
- INTERVALBINS=number
-
specifies the number of bins for interval variables. For more information about interval variable binning, see the section Details: HPSPLIT Procedure.
By default, INTERVALBINS=100.
- LEAFSIZE=number
-
specifies the minimum number of observations that a split must contain in the training data set in order for the split to be considered.
By default, LEAFSIZE=1.
- MAXBRANCH=number
-
specifies the maximum number of children per node in the tree. PROC HPSPLIT tries to create this number of children unless it is impossible (for example, if a split variable does not have enough levels).
The default is the number of target levels.
- MAXDEPTH=number
-
specifies the maximum depth of the tree to be grown.
The default depends on the value of the MAXBRANCH= option. If MAXBRANCH=2, the default is MAXDEPTH=10. Otherwise, the MAXDEPTH= option is set using the following equation:
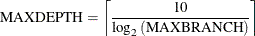
- MINCATSIZE=number
-
specifies the number of observations that a nominal variable level must have in order to be considered in the split. Input variable levels that have fewer observations than number receive the non-surrogate missing value assignment for that split.
By default, MINCATSIZE=1.
- MINDIST=number
-
specifies the minimum Kolmogorov-Smirnov distance for a split to be considered when you specify FASTCHAID in the CRITERION statement. Otherwise, this option is ignored.
By default, MINDIST=0.01.
- MINVARIANCE=value
-
specifies the minimum variance for a regression tree leaf to be eligible for splitting. That is, leaves whose variance is less than value are not split any further.
By default, MINVARIANCE=
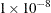 .
.
- MISSING=BRANCH | POPULARITY | SIMILARITY
-
specifies how a splitting rule handles missing values. You can specify one of the following:
By default, MISSING=POPULARITY.
- NSURROGATES=number
-
specifies the number of surrogate rules to create for each splitting rule.
By default, NSURROGATES=0.
- USEVARONCE
-
specifies that variables are to be split only once on a branch. However, a variable can be used more than once across branches. That is, a variable cannot be split more than once on the path from any leaf to the root node.