Managing Large SPD Server Files
Besides being a performance issue, managing large
files has file storage and disk space issues. Optimally, an SPD Server
administrator manages storage space for SPD Server LIBNAME domains.
In this case, you do not need to consider storage issues. SPD Server
does the work for you. Optimizing SPD Server Performance contains more information on managing large SPD Server
files.
Initial Setup of SPD Server LIBNAME Domain Storage
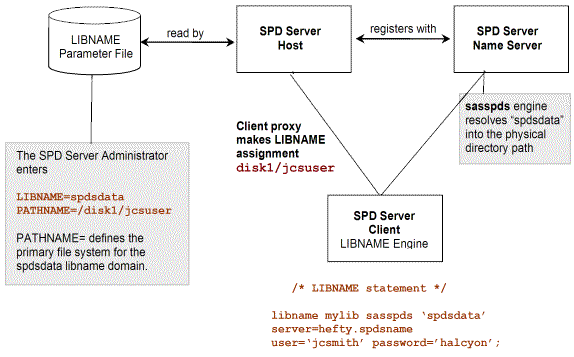
Figure 4.2 reviews how
an SPD Server domain is set up. An SPD Server administrator must define
the name and primary path for the domain in the LIBNAME parameter
file for SPD Server. The path that the administrator defines for each
domain is referred to as the primary file system for that domain.
The LIBNAME parameter file is read by the SPD Server at startup. The
SPD Server registers the domains with the SPD Server Name Server.
When the user issues a LIBNAME statement, the client sends a message
to the SPD Server Name Server that resolves the domain name to its
physical directory path, and determines the SPD Server that registered
the domain.
SAS Scalable Performance Data (SPD) Server Overview discusses LIBNAME path options that allow a user to specify
additional storage devices and paths for a domain. To manage his or
her own disk space, a user must be aware of the DATAPATH=, METAPATH=,
and INDEXPATH= options, as well as the ROPTIONS= option that the SPD
Server administrator uses.
Effect of the Administrator Option, ROPTIONS=
After defining a primary
file system for a domain, an SPD Server administrator can use LIBNAME
parameter file options, identical to the DATAPATH=, METAPATH=, and
INDEXPATH= options in the LIBNAME statement, to set up additional
paths for the domain. However, the administrator can restrict a user
from defining additional paths using the LIBNAME statement with the
ROPTIONS= LIBNAME parameter file option. When an SPD Server administrator
uses the ROPTIONS= option, the administrator's specification takes
precedence over the user's specification. More information is available
in “Configuring LIBNAME Domain Disk Space” in the SAS Scalable Performance Data Server: Administrator's Guide.
For example, assume
that a user uses the DATAPATH= option to specify a path to store table
data for a domain, and that the SPD Server administrator also uses
the DATAPATH= option with ROPTIONS= for that domain entry in the LIBNAME
parameter file. The user's DATAPATH= specifications are ignored.
The administrator's
use of ROPTIONS= with path options is recommended. It relieves users
of the complicated task of managing disk space and avoids the need
to embed physical path information in SAS programs. Instead, SAS jobs
refer to only the logical LIBNAME and rely on ROPTIONS= embedded by
the administrator to specify all of the physical path information.
This approach uses the power of the Name Server, allowing it to resolve
path information for an SPD Server domain.
Explicit or Default Storage Paths
You might wonder why
SPD Server offers you path options, and then discourages their use.
The answer is flexibility. A site can allow users to manage their
own disk space. While this is not recommended, the software allows
it.
To use path options
effectively, you must know that the first LIBNAME assignment or SQL
pass-through CONNECT statement naming a domain establishes an initial
set of paths for the domain. You can specify the paths, or the software
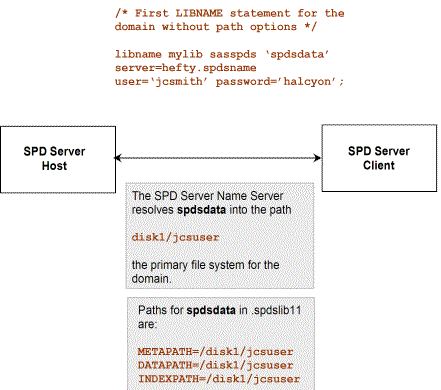
can establish a default set of paths. Figure 4.3 shows a default set
of paths. Figure 4.4 shows an explicit initial set of paths.
The path options METAPATH=,
DATAPATH=, and INDEXPATH= store partitions for the components—metadata,
data, and indexes. Subsequent LIBNAME assignments augment the path
list created by the initial LIBNAME assignment. In other words, SPD
Server appends each new path assignment to any existing list for the
component file.

In summary, unless you
or an SPD Server administrator specifies an initial set of paths,
the software uses the domain's primary file system in the LIBNAME
parameter file for the default path set. In the next section, information
about whether the default path set is ample for large tables or provides
optimal performance is discussed.
Understanding SPD Server Component Storage
SPD Server creates a
list of paths for storing table files in an SPD Server domain. However,
file partition storage has not been discussed. This section focuses
on using path options when an SPD Server administrator has not used
the ROPTIONS= option.
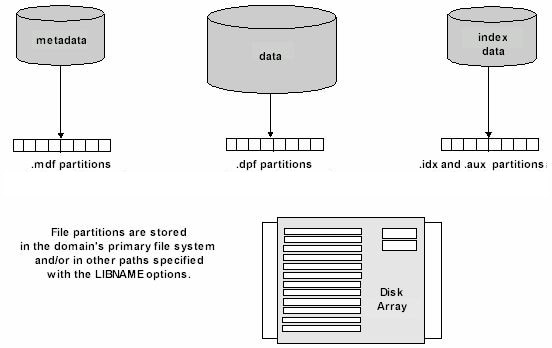
Each table consists
of a metadata component and a data component. Each component file
consists of one or more partition files on disk. The software requires
that the first metadata partition reside in the primary file system.
The primary file system is the path defined for the domain by an SPD
Server administrator. Other metadata partitions can overflow to additional
paths specified using the METAPATH= option.
If no paths are specified
for index and data components by the INDEXPATH= or DATAPATH= options,
SPD Server stores these partitions in the primary file system, too.
If other paths are specified, it stores the initial partition for
these components in the first path with available space. (Unlike metadata
partitions, data and index partitions do not have to start in the
primary file system.) A partition can expand until the path fills
up. Remaining partitions overflow to the next path with available
space, and so on. (See SPD Server Component Storage.)
Forced Partitioning of the Data Component
To improve parallel
processing of operations involving full-table scans (for example,
WHERE clause evaluations without indexes or SQL GROUP BY evaluations),
the SPD Server enables you to force the creation of data component
partitions at fixed-size intervals. To specify the size interval,
use the PARTSIZE= table option. By default, the SPD Server sets PARTSIZE=
to 16 MB. For more information, see SPD Server Table Options.
The SPD Server uses
the file systems that you specify with the DATAPATH= option to distribute
partitions in a cyclic (round-robin) pattern. Instead of creating
partitions until the first file system is full, the SPD Server randomly
chooses a file system from the DATAPATH= list for the first partition.
Then, it sequentially assigns partitions to successive file systems
in the DATAPATH= list. The software continues to cycle through the
file system set as many times as needed until all data partitions
for the table are stored. Assume that you specify the following:
Subsequently, you store
the BIGONE table in the domain. SPD Server uses random placement of
data partitions in the DATAPATH= list. So, the first BIGONE partition
can be stored in either the
/data1 or
the /data2 directory. Subsequent partitions
alternate between the /data1 and /data2 directories, and so on.
If you set PARTSIZE=0,
SPD Server uses the DATAPATH= file systems strictly for overflow.
It creates partitions in the first file system, up to the file size
limit of your operating system. Then, when the first file system is
full, it proceeds to the second file system, and so on.
What happens when you
issue the first LIBNAME statement for a domain, but you do not specify
path options? If your tables are small, most likely, the primary file
system is adequate. However, if your tables are large, the primary
file system can fill up quickly. How do you know when the primary
file system is full? SPD Server returns an error message when you
perform an append operation on an existing table, or when you create
a new table in the domain.
Importance of the First Metadata Partition
If the primary file
system is full, you can issue a subsequent LIBNAME statement that
specifies additional paths. This allows an append operation on an
existing table, but might not allow creation of a new table in the
domain. The reason why new paths do not prevent the failure of creating
a new table might not be obvious. The reason is the software cannot
store the first metadata file partition because the primary file system
is still full. What is the solution? You need to either free space
in the primary file system or have the SPD Server administrator create
a new LIBNAME domain.
Using Path Options for Large Table Storage
Overview of Using Path Options
If you must manage your
table storage, anticipate disk space for large tables. Use the LIBNAME
path options with the first LIBNAME statement for the domain. Store
data and index partitions using the DATAPATH= and INDEXPATH= options
on a different storage device other than the primary file system.
This reserves the primary file system for metadata files.
Specify Explicit Initial Set of Paths
SITEUSR1 issues the
first LIBNAME statement for the MYLIB domain. By default, the domain's
primary file system is used to store metadata partitions. But, another
device—MYDISK30—and directory—SITEUSER—are
specified to store the data and index partitions. (The SPD Server
administrator created the primary file system for MYLIB.)
/* I anticipate the primary file system for the MYLIB domain */
/* is ample for metadata files, but I will use MYDISK30 */
/* to store my data and index partitions. */
LIBNAME myref sasspds 'mylib'
datapath=('/mydisk30/siteuser')
indexpath=('/mydisk30/siteuser')
server=husky.spdsname
user='siteusr1' prompt=yes;
Specify Subsequent LIBNAME Statement to Add Paths
SITEUSR1 issues a subsequent
LIBNAME statement for the MYLIB domain, specifying additional paths
for the data and index partitions. The user is storing large tables,
so two storage devices and directories for the data are listed. A
third device for indexes associated with the tables is listed.
/* I noticed today MYDISK30 is getting full. */
/* I am adding MYDISK31 for possible overflow. */
LIBNAME expand sasspds 'mylib'
datapath=('/mydisk31/siteuser' '/mydisk32/siteuser')
indexpath=('/mydisk33/siteuser')
server=husky.spdsname
user='siteusr1' prompt=yes;
SPD Server appends the
new paths to the existing list for each component type. The entire
path list that spdslibll maintains is the following:
datapath=('mydisk30/siteuser'
'/mydisk31/siteuser'
'/mydisk32/siteuser')
indexpath=('mydisk30/siteuser'
'/mydisk33/siteuser')
How does SPD Server
use the path list? It stores partitions of the data components for
MYLIB tables in the specified data paths. (How the software uses the
data paths depends on the value of the PARTSIZE= option.) For index
components, it stores partitions in the first path listed until that
space is full, and then it proceeds to the next path listed.