Functions
BAYESACT Call
computes posterior probabilities that observations are contaminated with a larger variance.
Syntax
CALL BAYESACT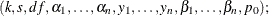
where
|
k |
is the contamination coefficient, where |
|
s |
is an independent estimate of |
|
df |
is the number of degrees of freedom for s, where |
|
|
is the prior probability of contamination for the ith observation in the sample, where |
|
|
is the ith observation in the sample, where |
|
|
is the variable that contains the returned posterior probability of contamination for the ith observation in the sample, where |
|
|
is the variable that contains the posterior probability that the sample is uncontaminated. |
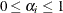
Description
The BAYESACT call computes posterior probabilities (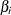 ) that observations in a sample are contaminated with a larger variance than other observations and computes the posterior probability (
) that observations in a sample are contaminated with a larger variance than other observations and computes the posterior probability (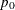 ) that the entire sample is uncontaminated.
) that the entire sample is uncontaminated.
Specifically, the BAYESACT call assumes a normal random sample of n independent observations, with a mean of 0 (a centered sample) where some of the observations may have a larger variance than others:
![\[ \mbox{Var}(y_ i) = \left\{ \begin{array}{ll} \sigma ^2 & \mbox{with probability } 1-\alpha _ i \\ k^2\sigma ^2 & \mbox{with probability } \alpha _ i \end{array} \right. \]](images/qcug_functions0038.png)
where 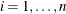 . The parameter k is called the contamination coefficient. The value of
. The parameter k is called the contamination coefficient. The value of 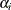 is the prior probability of contamination for the ith observation. Based on the prior probability of contamination for each observation, the call gives the posterior probability
of contamination for each observation and the posterior probability that the entire sample is uncontaminated.
is the prior probability of contamination for the ith observation. Based on the prior probability of contamination for each observation, the call gives the posterior probability
of contamination for each observation and the posterior probability that the entire sample is uncontaminated.
Box and Meyer (1986) suggest computing posterior probabilities of contamination for the analysis of saturated orthogonal factorial designs. Although
these designs give uncorrelated estimates for effects, the significance of effects cannot be tested in an analysis of variance
since there are no degrees of freedom for error. Box and Meyer suggest computing posterior probabilities of contamination
for the effect estimates. The prior probabilities () give the likelihood that an effect will be significant, and the contamination coefficient (k) gives a measure of how large the significant effect will be. Box and Meyer recommend using 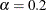 and k = 10, implying that about 1 in 5 effects will be about 10 times larger than the remaining effects. To adequately explore
posterior probabilities, examine them over a range of values for prior probabilities and a range of contamination coefficients.
and k = 10, implying that about 1 in 5 effects will be about 10 times larger than the remaining effects. To adequately explore
posterior probabilities, examine them over a range of values for prior probabilities and a range of contamination coefficients.
If an independent estimate of  is unavailable (as is the case when the
is unavailable (as is the case when the 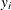 s are effects from a saturated orthogonal design), use 0 for s and df in the BAYESACT call. Otherwise, the call assumes s is proportional to the square root of a
s are effects from a saturated orthogonal design), use 0 for s and df in the BAYESACT call. Otherwise, the call assumes s is proportional to the square root of a 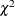 random variable with df degrees of freedom. For example, if the s are estimated effects from an orthogonal design that is not saturated, then use the BAYESACT call with s equal to the estimated standard error of the estimates and df equal to the degrees of freedom for error.
random variable with df degrees of freedom. For example, if the s are estimated effects from an orthogonal design that is not saturated, then use the BAYESACT call with s equal to the estimated standard error of the estimates and df equal to the degrees of freedom for error.
From Bayes’ theorem, the posterior probability that is contaminated is
![\[ \beta _ i(\sigma )=\frac{\alpha _ if(y_ i;0,k^2\sigma ^2) }{\alpha _ if(y_ i;0,k^2\sigma ^2) + (1-\alpha _ i)f(y_ i;0,\sigma ^2) } \]](images/qcug_functions0041.png)
for a given value of , where 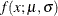 is the density of a normal distribution with mean
is the density of a normal distribution with mean 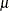 and variance
and variance 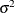 .
.
The probability that the sample is uncontaminated is
![\[ p=\prod _{i=1}^{n}(1-\beta _ i(\sigma )) \]](images/qcug_functions0045.png)
Posterior probabilities that are independent of are derived by integrating 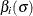 and p over a noninformative prior for . If an estimate of is available (when df > 0), it is appropriately incorporated. Refer to Box and Meyer (1986) for details.
and p over a noninformative prior for . If an estimate of is available (when df > 0), it is appropriately incorporated. Refer to Box and Meyer (1986) for details.
Examples
The statements
data;
retain post1-post7 postnone;
call bayesact(10,0,0,
0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2,
-5.4375,1.3875,8.2875,0.2625,1.7125,-11.4125,1.5875,
post1, post2, post3, post4, post5, post6, post7,
postnone);
run;
return the following posterior probabilities:
POST1 0.42108 POST2 0.037412 POST3 0.53438 POST4 0.024679 POST5 0.050294 POST6 0.64329 POST7 0.044408 POSTNONE 0.28621
The probability that the sample is uncontaminated is 0.28621. A situation where this BAYESACT call would be appropriate is
a saturated 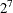 design in 8 runs, where the estimates for main effects are as shown in the function above (-5.4375, 1.3875, . . . , 1.5875).
design in 8 runs, where the estimates for main effects are as shown in the function above (-5.4375, 1.3875, . . . , 1.5875).