PROC CAPABILITY and General Statements

Robust Estimators
The CAPABILITY procedure provides several methods for computing robust estimates of location and scale, which are insensitive to outliers in the data.
Winsorized Means
The k-times Winsorized mean is a robust estimator of location which is computed as
![\[ \bar{x}_{wk} = \frac{1}{n} \left( (k+1)x_{(k+1)} + \sum _{i=k+2}^{n-k-1} x_{(i)} + (k+1)x_{(n-k)} \right) \]](images/qcug_capability0153.png)
where n is the number of observations, and 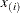 is the ith order statistic when the observations are arranged in increasing order:
is the ith order statistic when the observations are arranged in increasing order:
![\[ x_{(1)} \leq x_{(2)} \leq \ldots \leq x_{(n)} \]](images/qcug_capability0155.png)
The Winsorized mean is the mean computed after replacing the k smallest observations with the (k + 1)st smallest observation, and the k largest observations with the (k + 1)st largest observation.
For data from a symmetric distribution, the Winsorized mean is an unbiased estimate of the population mean. However, the Winsorized mean does not have a normal distribution even if the data are normally distributed.
The Winsorized sum of squared deviations is defined as
![\[ s_{wk}^{2} = (k+1) (x_{(k+1)} - \bar{x}_{wk})^2 + \sum _{i=k+2}^{n-k-1} ( x_{(i)} - \bar{x}_{wk} )^2 + (k+1) (x_{(n-k)} - \bar{x}_{wk})^2 \]](images/qcug_capability0156.png)
A Winsorized t test is given by
![\[ t_{wk} = \frac{\bar{x}_{wk} - \mu _0}{\mr{STDERR}(\bar{x}_{wk}) } \]](images/qcug_capability0157.png)
where the standard error of the Winsorized mean is
![\[ \mr{STDERR}(\bar{x}_{wk}) = \frac{n-1}{n-2k-1} \frac{s_{wk}}{\sqrt {n(n-1)}} \]](images/qcug_capability0158.png)
When the data are from a symmetric distribution, the distribution of 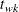 is approximated by a Student’s t distribution with
is approximated by a Student’s t distribution with 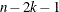 degrees of freedom. Refer to Tukey and McLaughlin (1963) and Dixon and Tukey (1968).
degrees of freedom. Refer to Tukey and McLaughlin (1963) and Dixon and Tukey (1968).
A 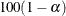 % Winsorized confidence interval for the mean has upper and lower limits
% Winsorized confidence interval for the mean has upper and lower limits
![\[ \bar{x}_{wk} \pm t_{1 - \alpha /2} \mr{STDERR}( \bar{x}_{wk} ) \]](images/qcug_capability0161.png)
where 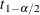 is the
is the 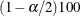 th percentile of the Student’s t distribution with degrees of freedom.
th percentile of the Student’s t distribution with degrees of freedom.
Trimmed Means
The k-times trimmed mean is a robust estimator of location which is computed as
![\[ \bar{x}_{tk} = \frac{1}{n-2k} \sum _{i=k+1}^{n-k} x_{(i)} \]](images/qcug_capability0164.png)
where n is the number of observations, and is the ith order statistic when the observations are arranged in increasing order:
The trimmed mean is the mean computed after the k smallest observations and the k largest observations in the sample are deleted.
For data from a symmetric distribution, the trimmed mean is an unbiased estimate of the population mean. However, the trimmed mean does not have a normal distribution even if the data are normally distributed.
A robust estimate of the variance of the trimmed mean 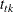 can be obtained from the Winsorized sum of squared deviations; refer to Tukey and McLaughlin (1963). the corresponding trimmed t test is given by
can be obtained from the Winsorized sum of squared deviations; refer to Tukey and McLaughlin (1963). the corresponding trimmed t test is given by
![\[ t_{tk} = \frac{\bar{x}_{tk} - \mu _0}{\mr{STDERR}(\bar{x}_{tk}) } \]](images/qcug_capability0166.png)
where the standard error of the trimmed mean is
![\[ \mr{STDERR}(\bar{x}_{tk}) = \frac{s_{tk}}{\sqrt {(n-2k)(n-2k-1)}} \]](images/qcug_capability0167.png)
and 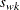 is the square root of the Winsorized sum of squared deviations.
is the square root of the Winsorized sum of squared deviations.
When the data are from a symmetric distribution, the distribution of is approximated by a Student’s t distribution with degrees of freedom. Refer to Tukey and McLaughlin (1963) and Dixon and Tukey (1968).
A % trimmed confidence interval for the mean has upper and lower limits
![\[ \bar{x}_{tk} \pm t_{1 - \alpha /2} \mr{STDERR}( \bar{x}_{tk} ) \]](images/qcug_capability0169.png)
where is the th percentile of the Student’s t distribution with degrees of freedom.
Robust Estimates of Scale
The sample standard deviation, which is the most commonly used estimator of scale, is sensitive to outliers. Robust scale
estimators, on the other hand, remain bounded when a single data value is replaced by an arbitrarily large or small value.
The CAPABILITY procedure computes several robust measures of scale, including the interquartile range Gini’s mean difference
G, the median absolute deviation about the median (MAD), 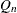 , and
, and 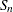 . In addition, the procedure computes estimates of the normal standard deviation
. In addition, the procedure computes estimates of the normal standard deviation  derived from each of these measures.
derived from each of these measures.
The interquartile range (IQR) is simply the difference between the upper and lower quartiles. For a normal population, can be estimated as IQR/1.34898.
Gini’s mean difference is computed as
![\[ G = \frac{1}{ \left( \begin{array}{c} n \\ 2 \end{array} \right) } \sum _{i<j} |x_ i - x_ j | \]](images/qcug_capability0170.png)
For a normal population, the expected value of G is 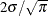 . Thus
. Thus 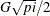 is a robust estimator of when the data are from a normal sample. For the normal distribution, this estimator has high efficiency relative to the usual
sample standard deviation, and it is also less sensitive to the presence of outliers.
is a robust estimator of when the data are from a normal sample. For the normal distribution, this estimator has high efficiency relative to the usual
sample standard deviation, and it is also less sensitive to the presence of outliers.
A very robust scale estimator is the MAD, the median absolute deviation from the median (Hampel 1974), which is computed as
![\[ \mr{MAD} = \mr{med}_{i}( | x_ i - \mr{med}_{j}( x_ j ) | ) \]](images/qcug_capability0173.png)
where the inner median, 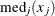 , is the median of the n observations, and the outer median (taken over i) is the median of the n absolute values of the deviations about the inner median. For a normal population, 1.4826MAD is an estimator of .
, is the median of the n observations, and the outer median (taken over i) is the median of the n absolute values of the deviations about the inner median. For a normal population, 1.4826MAD is an estimator of .
The MAD has low efficiency for normal distributions, and it may not always be appropriate for symmetric distributions. Rousseeuw and Croux (1993) proposed two statistics as alternatives to the MAD. The first is
![\[ S_ n = 1.1926 \ \mr{med}_{i} ( \mr{med}_{j} ( |x_ i - x_ j | ) ) \]](images/qcug_capability0175.png)
where the outer median (taken over i) is the median of the n medians of 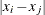 ,
, 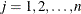 . To reduce small-sample bias,
. To reduce small-sample bias, 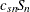 is used to estimate , where
is used to estimate , where 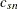 is a correction factor; refer to Croux and Rousseeuw (1992).
is a correction factor; refer to Croux and Rousseeuw (1992).
The second statistic is
![\[ Q_ n = 2.2219 \ \{ | x_ i - x_ j |; i < j \} _{(k)} \]](images/qcug_capability0180.png)
where
![\[ k = \left( \begin{array}{c} h \\ 2 \end{array} \right) \]](images/qcug_capability0181.png)
and ![$h = [n/2] + 1$](images/qcug_capability0182.png) . In other words, is 2.2219 times the kth order statistic of the
. In other words, is 2.2219 times the kth order statistic of the 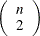 distances between the data points. The bias-corrected statistic
distances between the data points. The bias-corrected statistic 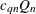 is used to estimate , where
is used to estimate , where 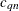 is a correction factor; refer to Croux and Rousseeuw (1992).
is a correction factor; refer to Croux and Rousseeuw (1992).