| Principal Components Analysis |
Principal component analysis was originated by Pearson (1901) and later developed by Hotelling (1933). The application of principal components is discussed by Rao (1964), Cooley and Lohnes (1971), Gnanadesikan (1977), and Jackson (1991). Excellent statistical treatments of principal components are found in Kshirsagar (1972), Morrison (1976), and Mardia, Kent, and Bibby (1979).
Principal components modeling focuses on the number of components used. The analysis begins with an eigenvalue decomposition of the sample covariance matrix, 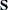 ,
,
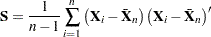 |
as
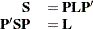 |
where 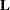 is a diagonal matrix and
is a diagonal matrix and 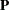 is an orthogonal matrix (Jackson; 1991; Mardia, Kent, and Bibby; 1979). The columns of are the eigenvectors, and the diagonal elements of are the eigenvalues. The eigenvectors are customarily scaled so that they have unit length.
is an orthogonal matrix (Jackson; 1991; Mardia, Kent, and Bibby; 1979). The columns of are the eigenvectors, and the diagonal elements of are the eigenvalues. The eigenvectors are customarily scaled so that they have unit length.
A principal component, 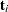 , is a linear combination of the original variables. The coefficients are the eigenvectors of the covariance matrix. The principal component scores for the
, is a linear combination of the original variables. The coefficients are the eigenvectors of the covariance matrix. The principal component scores for the 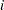 th observation are computed as
th observation are computed as
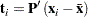 |
The principal components are sorted by descending order of the eigenvalues, which are equal to the variances of the components.
The eigenvectors are the principal component loadings. The eigenvectors are orthogonal, so the principal components represent jointly perpendicular directions through the space of the original variables. The scores on the first j principal components have the highest possible generalized variance of any set of 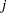 unit-length linear combinations of the original variables.
unit-length linear combinations of the original variables.
The first j principal components provide a least squares solution to the model
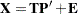 |
where 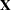 is an
is an 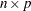 matrix of the centered observed variables,
matrix of the centered observed variables, 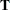 is the
is the 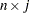 matrix of scores on the first j principal components,
matrix of scores on the first j principal components, 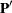 is the
is the 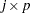 matrix of eigenvectors, and
matrix of eigenvectors, and 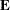 is an matrix of residuals. The first principal components are the vectors (rows of
is an matrix of residuals. The first principal components are the vectors (rows of 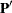 ) which minimize trace
) which minimize trace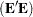 , the sum of all the squared elements in .
, the sum of all the squared elements in .
The first j principal components are the best linear predictors of the process variables among all possible sets of j variables, although any nonsingular linear transformation of the first j principal components would provide equally good prediction. The same result is obtained by minimizing the determinant or the Euclidean norm of 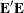 rather than the trace.
rather than the trace.
Note: This procedure is experimental.