The FREQ Procedure

Cochran-Mantel-Haenszel Statistics
The CMH option in the TABLES statement gives a stratified statistical analysis of the relationship between the row and column
variables after controlling for the strata variables in a multiway table. For example, for the table request A*B*C*D, the CMH option provides an analysis of the relationship between C and D, after controlling for A and B. The stratified analysis provides a way to adjust for the possible confounding effects of A and B without being forced to estimate parameters for them.
The CMH analysis produces Cochran-Mantel-Haenszel statistics, which include the correlation statistic, the ANOVA (row mean
scores) statistic, and the general association statistic. For 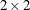 tables, the CMH option also provides Mantel-Haenszel and logit estimates of the common odds ratio and the common relative
risks, in addition to the Breslow-Day test for homogeneity of the odds ratios.
tables, the CMH option also provides Mantel-Haenszel and logit estimates of the common odds ratio and the common relative
risks, in addition to the Breslow-Day test for homogeneity of the odds ratios.
Exact statistics are also available for stratified tables. If you specify the EQOR option in the EXACT statement, PROC FREQ provides Zelen’s exact test for equal odds ratios.
If you specify the COMOR option in the EXACT statement, PROC FREQ provides exact confidence limits for the common odds ratio
and an exact test that the common odds ratio equals one.
Let the number of strata be denoted by q, indexing the strata by 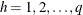 . Each stratum contains a contingency table with
. Each stratum contains a contingency table with X representing the row variable and Y representing the column variable. For table h, denote the cell frequency in row i and column j by 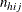 , with corresponding row and column marginal totals denoted by
, with corresponding row and column marginal totals denoted by 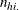 and
and 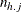 , and the overall stratum total by
, and the overall stratum total by 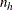 .
.
Because the formulas for the Cochran-Mantel-Haenszel statistics are more easily defined in terms of matrices, the following
notation is used. Vectors are presumed to be column vectors unless they are transposed  .
.
![\[ \begin{array}{lllll} \mb{n}_{hi}^{\prime } & = & (n_{hi1},n_{hi2},\ldots ,n_{hiC}) & & (1 \times C) \\[0.10in] \mb{n}_ h^{\prime } & = & (\mb{n}_{h1}^{\prime },\mb{n}_{h2}^{\prime },\ldots , \mb{n}_{hR}^{\prime }) & & (1 \times RC) \\[0.10in] p_{hi \cdot } & = & n_{hi \cdot } ~ / ~ n_ h & & (1 \times 1) \\[0.10in] p_{h \cdot j} & = & n_{h \cdot j} ~ / ~ n_ h & & (1 \times 1) \\[0.10in] \mb{P}_{h* \cdot }^{\prime } & = & (p_{h1 \cdot },p_{h2 \cdot }, \ldots ,p_{hR \cdot }) & & (1 \times R) \\[0.10in] \mb{P}_{h \cdot *}^{\prime } & = & (p_{h \cdot 1},p_{h \cdot 2}, \ldots ,p_{h \cdot C}) & & (1 \times C) \\ \end{array} \]](images/procstat_freq0569.png)
Assume that the strata are independent and that the marginal totals of each stratum are fixed. The null hypothesis, 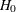 , is that there is no association between
, is that there is no association between X and Y in any of the strata. The corresponding model is the multiple hypergeometric; this implies that, under , the expected value and covariance matrix of the frequencies are, respectively,
![\[ \mb{m}_ h = \mb{E}[\mb{n}_ h ~ |~ H_0] = n_ h(\mb{P}_{h \cdot *} \otimes \mb{P}_{h* \cdot }) \]](images/procstat_freq0571.png)
![\[ \mb{Var}[\mb{n}_ h ~ |~ H_0] = c \left( ~ (\mb{D}_{\mb{P}h \cdot *} - \mb{P}_{h \cdot *}\mb{P}_{h \cdot *}^{\prime }) \otimes (\mb{D}_{\mb{P}h* \cdot } - \mb{P}_{h* \cdot }\mb{P}_{h* \cdot }^{\prime }) ~ \right) \]](images/procstat_freq0572.png)
where
![\[ c = n_ h^2 ~ / ~ (n_ h-1) \]](images/procstat_freq0573.png)
and where 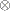 denotes Kronecker product multiplication and
denotes Kronecker product multiplication and 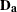 is a diagonal matrix with the elements of
is a diagonal matrix with the elements of  on the main diagonal.
on the main diagonal.
The generalized CMH statistic (Landis, Heyman, and Koch 1978) is defined as
![\[ Q_{\mi{CMH}} = \mb{G}^{\prime }\mb{V_ G}^{-1}\mb{G} \]](images/procstat_freq0577.png)
where
![\begin{eqnarray*} \mb{G} & = & \sum _ h \mb{B}_ h(\mb{n}_ h - \mb{m}_ h ) \\[0.10in] \mb{V}_{\mb{G}} & = & \sum _ h \mb{B}_ h \left( \mb{Var}[\mb{n}_ h ~ |~ H_0] \right) \mb{B}_ h^{\prime } \end{eqnarray*}](images/procstat_freq0578.png)
and where
![\[ \mb{B}_ h = \mb{C}_ h \otimes \mb{R}_ h \]](images/procstat_freq0579.png)
is a matrix of fixed constants based on column scores 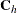 and row scores
and row scores 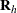 . When the null hypothesis is true, the CMH statistic has an asymptotic chi-square distribution with degrees of freedom equal
to the rank of
. When the null hypothesis is true, the CMH statistic has an asymptotic chi-square distribution with degrees of freedom equal
to the rank of 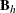 . If
. If 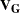 is found to be singular, PROC FREQ prints a message and sets the value of the CMH statistic to missing.
is found to be singular, PROC FREQ prints a message and sets the value of the CMH statistic to missing.
PROC FREQ computes three CMH statistics by using this formula for the generalized CMH statistic, with different row and column score definitions for each statistic. The CMH statistics that PROC FREQ computes are the correlation statistic, the ANOVA (row mean scores) statistic, and the general association statistic. These statistics test the null hypothesis of no association against different alternative hypotheses. The following sections describe the computation of these CMH statistics.
Caution: The CMH statistics have low power for detecting an association in which the patterns of association for some of the strata are in the opposite direction of the patterns displayed by other strata. Thus, a nonsignificant CMH statistic suggests either that there is no association or that no pattern of association has enough strength or consistency to dominate any other pattern.
Correlation Statistic
The correlation statistic, popularized by Mantel and Haenszel, has 1 degree of freedom and is known as the Mantel-Haenszel statistic (Mantel and Haenszel 1959; Mantel 1963).
The alternative hypothesis for the correlation statistic is that there is a linear association between X and Y in at least one stratum. If either X or Y does not lie on an ordinal (or interval) scale, this statistic is not meaningful.
To compute the correlation statistic, PROC FREQ uses the formula for the generalized CMH statistic with the row and column
scores determined by the SCORES= option in the TABLES statement. See the section Scores for more information about the available score types. The matrix of row scores has dimension 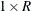 , and the matrix of column scores has dimension
, and the matrix of column scores has dimension 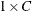 .
.
When there is only one stratum, this CMH statistic reduces to 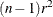 , where r is the Pearson correlation coefficient between X and Y. When nonparametric (RANK or RIDIT) scores are specified, the statistic reduces to
, where r is the Pearson correlation coefficient between X and Y. When nonparametric (RANK or RIDIT) scores are specified, the statistic reduces to 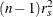 , where
, where 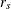 is the Spearman rank correlation coefficient between
is the Spearman rank correlation coefficient between X and Y. When there is more than one stratum, this CMH statistic becomes a stratum-adjusted correlation statistic.
ANOVA (Row Mean Scores) Statistic
The ANOVA statistic can be used only when the column variable Y lies on an ordinal (or interval) scale so that the mean score of Y is meaningful. For the ANOVA statistic, the mean score is computed for each row of the table, and the alternative hypothesis
is that, for at least one stratum, the mean scores of the R rows are unequal. In other words, the statistic is sensitive to location differences among the R distributions of Y.
The matrix of column scores has dimension , and the column scores are determined by the SCORES= option.
The matrix of row scores has dimension 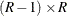 and is created internally by PROC FREQ as
and is created internally by PROC FREQ as
![\[ \mb{R}_ h = \left[ \mb{I}_{R-1} , -\mb{J}_{R-1} \right] \]](images/procstat_freq0590.png)
where 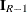 is an identity matrix of rank R – 1 and
is an identity matrix of rank R – 1 and 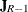 is an
is an 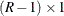 vector of ones. This matrix has the effect of forming R – 1 independent contrasts of the R mean scores.
vector of ones. This matrix has the effect of forming R – 1 independent contrasts of the R mean scores.
When there is only one stratum, this CMH statistic is essentially an analysis of variance (ANOVA) statistic in the sense that
it is a function of the variance ratio F statistic that would be obtained from a one-way ANOVA on the dependent variable Y. If nonparametric scores are specified in this case, the ANOVA statistic is a Kruskal-Wallis test.
When there is more than one stratum, this CMH statistic corresponds to a stratum-adjusted ANOVA or Kruskal-Wallis test. In the special case where there is one subject per row and one subject per column in the contingency table of each stratum, this CMH statistic is identical to Friedman’s chi-square. See Example 3.9 for an illustration.
General Association Statistic
The alternative hypothesis for the general association statistic is that, for at least one stratum, there is some kind of
association between X and Y. This statistic is always interpretable because it does not require an ordinal scale for either X or Y.
For the general association statistic, the matrix is the same as the one used for the ANOVA statistic. The matrix is defined similarly as
![\[ \mb{C}_ h = \left[ \mb{I}_{C-1} , -\mb{J}_{C-1} \right] \]](images/procstat_freq0594.png)
PROC FREQ generates both score matrices internally. When there is only one stratum, the general association CMH statistic
reduces to 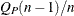 , where
, where 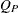 is the Pearson chi-square statistic. When there is more than one stratum, the CMH statistic becomes a stratum-adjusted Pearson
chi-square statistic. Note that a similar adjustment can be made by summing the Pearson chi-squares across the strata. However,
the latter statistic requires a large sample size in each stratum to support the resulting chi-square distribution with q(R–1)(C–1) degrees of freedom. The CMH statistic requires only a large overall sample size because it has only (R–1)(C–1) degrees of freedom.
is the Pearson chi-square statistic. When there is more than one stratum, the CMH statistic becomes a stratum-adjusted Pearson
chi-square statistic. Note that a similar adjustment can be made by summing the Pearson chi-squares across the strata. However,
the latter statistic requires a large sample size in each stratum to support the resulting chi-square distribution with q(R–1)(C–1) degrees of freedom. The CMH statistic requires only a large overall sample size because it has only (R–1)(C–1) degrees of freedom.
See Cochran (1954); Mantel and Haenszel (1959); Mantel (1963); Birch (1965); Landis, Heyman, and Koch (1978).
Mantel-Fleiss Criterion
If you specify the CMH(MANTELFLEISS) option in the TABLES statement, PROC FREQ computes the Mantel-Fleiss criterion for stratified
tables. The Mantel-Fleiss criterion can be used to assess the validity of the chi-square approximation for the distribution
of the Mantel-Haenszel statistic for tables. For more information, see Mantel and Fleiss (1980); Mantel and Haenszel (1959); Stokes, Davis, and Koch (2012); Dmitrienko et al. (2005).
The Mantel-Fleiss criterion is computed as
![\[ \mathit{MF} = \min ~ \left( ~ \left[ \sum _ h m_{h11} - \sum _ h (n_{h11})_ L \right], ~ ~ \left[ \sum _ h (n_{h11})_ U - \sum _ h m_{h11} \right] ~ \right) \]](images/procstat_freq0597.png)
where 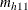 is the expected value of
is the expected value of 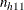 under the hypothesis of no association between the row and column variables in table h,
under the hypothesis of no association between the row and column variables in table h, 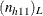 is the minimum possible value of the table cell frequency, and
is the minimum possible value of the table cell frequency, and 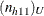 is the maximum possible value,
is the maximum possible value,
![\begin{eqnarray*} m_{h11} & =& n_{h1 \cdot } ~ n_{h \cdot 1} ~ / ~ n_ h \\[0.10in] (n_{h11})_ L & =& \max \left( ~ 0, ~ ~ n_{h1 \cdot } - n_{h \cdot 2} ~ \right) \\[0.10in] (n_{h11})_ U & =& \min \left( ~ n_{h \cdot 1}, ~ ~ n_{h1 \cdot } ~ \right) \end{eqnarray*}](images/procstat_freq0602.png)
The Mantel-Fleiss guideline accepts the validity of the Mantel-Haenszel approximation when the value of the criterion is at least 5. When the criterion is less than 5, PROC FREQ displays a warning.
Adjusted Odds Ratio and Relative Risk Estimates
The CMH option provides adjusted odds ratio and relative risk estimates for stratified tables. For each of these measures, PROC FREQ computes a Mantel-Haenszel estimate and a logit estimate. These estimates apply
to n-way table requests in the TABLES statement, when the row and column variables both have two levels.
For example, for the table request A*B*C*D, if the row and column variables C and D both have two levels, PROC FREQ provides odds ratio and relative risk estimates, adjusting for the confounding variables
A and B.
The choice of an appropriate measure depends on the study design. For case-control (retrospective) studies, the odds ratio is appropriate. For cohort (prospective) or cross-sectional studies, the relative risk is appropriate. See the section Odds Ratio and Relative Risks for 2 x 2 Tables for more information on these measures.
Throughout this section, z denotes the 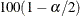 th percentile of the standard normal distribution.
th percentile of the standard normal distribution.
Odds Ratio, Case-Control Studies
PROC FREQ provides Mantel-Haenszel and logit estimates for the common odds ratio for stratified tables.
Mantel-Haenszel Estimator
The Mantel-Haenszel estimate of the common odds ratio is computed as
![\[ \mathit{OR}_{\mi{MH}} = \left( \sum _ h n_{h11} ~ n_{h22} / n_ h \right) ~ / ~ \left( \sum _ h n_{h12} ~ n_{h21} / n_ h \right) \]](images/procstat_freq0603.png)
It is always computed unless the denominator is 0. For more information, see Mantel and Haenszel (1959) and Agresti (2002).
To compute confidence limits for the common odds ratio, PROC FREQ uses the Robins, Breslow, and Greenland (1986) variance estimate for 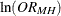 . The % confidence limits for the common odds ratio are
. The % confidence limits for the common odds ratio are
![\[ \bigl ( ~ \mathit{OR}_{\mi{MH}} \times \exp (-z \hat{\sigma }), ~ ~ \mathit{OR}_{\mi{MH}} \times \exp ( z \hat{\sigma }) ~ \bigr ) \]](images/procstat_freq0605.png)
where
![\begin{eqnarray*} \hat{\sigma }^2 & = & \widehat{\mr{Var}}(~ \ln (\mathit{OR}_{\mi{MH}})~ ) \\[0.10in]& = & \frac{\sum _ h (n_{h11} + n_{h22}) (n_{h11} ~ n_{h22}) / n_ h^2}{2 \left( \sum _ h n_{h11} ~ n_{h22} / n_ h \right)^2} \\[0.10in]& & + ~ \frac{\sum _ h [ (n_{h11} + n_{h22})(n_{h12} ~ n_{h21}) + (n_{h12} + n_{h21})(n_{h11} ~ n_{h22}) ] / n_ h^2}{2 \left( \sum _ h n_{h11} ~ n_{h22} / n_ h \right) \left( \sum _ h n_{h12} ~ n_{h21} / n_ h \right)} \\[0.10in]& & + ~ \frac{\sum _ h (n_{h12} + n_{h21}) (n_{h12} ~ n_{h21}) / n_ h^2}{2 \left( \sum _ h n_{h12} ~ n_{h21} / n_ h \right)^2} \end{eqnarray*}](images/procstat_freq0606.png)
Note that the Mantel-Haenszel odds ratio estimator is less sensitive to small 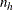 than the logit estimator.
than the logit estimator.
Logit Estimator
The adjusted logit estimate of the common odds ratio (Woolf 1955) is computed as
![\[ \mathit{OR}_{\mi{L}} = \exp \left( \sum _ h w_ h \ln (\mathit{OR}_ h) ~ / ~ \sum _ h w_ h \right) \]](images/procstat_freq0608.png)
and the corresponding 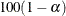 % confidence limits are
% confidence limits are
![\[ \left( ~ \mathit{OR}_{\mi{L}} \times \exp \left( -z / \sqrt {\sum _ h w_ h} \right) , ~ ~ \mathit{OR}_{\mi{L}} \times \exp \left( z / \sqrt {\sum _ h w_ h} \right) ~ \right) \]](images/procstat_freq0609.png)
where 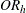 is the odds ratio for stratum h, and
is the odds ratio for stratum h, and
![\[ w_ h = 1 / \mr{Var}(\ln (\mathit{OR}_ h)) \]](images/procstat_freq0611.png)
If any table cell frequency in a stratum h is 0, PROC FREQ adds 0.5 to each cell of the stratum before computing and 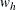 (Haldane 1955) for the logit estimate. The procedure provides a warning when this occurs.
(Haldane 1955) for the logit estimate. The procedure provides a warning when this occurs.
Relative Risks, Cohort Studies
PROC FREQ provides Mantel-Haenszel and logit estimates of the common relative risks for stratified tables.
Mantel-Haenszel Estimator
The Mantel-Haenszel estimate of the common relative risk for column 1 is computed as
![\[ \mathit{RR}_{\mi{MH}} = \left( \sum _ h n_{h11} ~ n_{h2 \cdot } ~ / ~ n_ h \right) ~ / ~ \left( \sum _ h n_{h21} ~ n_{h1 \cdot } ~ / ~ n_ h \right) \]](images/procstat_freq0613.png)
It is always computed unless the denominator is 0. See Mantel and Haenszel (1959) and Agresti (2002) for more information.
To compute confidence limits for the common relative risk, PROC FREQ uses the Greenland and Robins (1985) variance estimate for 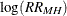 . The % confidence limits for the common relative risk are
. The % confidence limits for the common relative risk are
![\[ \bigl ( ~ \mathit{RR}_{\mi{MH}} \times \exp (-z \hat{\sigma }), ~ ~ \mathit{RR}_{\mi{MH}} \times \exp ( z \hat{\sigma }) ~ \bigr ) \]](images/procstat_freq0615.png)
where
![\[ \hat{\sigma }^2 = \widehat{\mr{Var}}(~ \ln (\mathit{RR}_{\mi{MH}})~ ) = \frac{\sum _ h (n_{h1 \cdot } ~ n_{h2 \cdot } ~ n_{h \cdot 1} - n_{h11} ~ n_{h21} ~ n_ h) / n_ h^2 }{ \left( \sum _ h n_{h11} ~ n_{h2 \cdot } / n_ h \right) \left( \sum _ h n_{h21} ~ n_{h1 \cdot } / n_ h \right) } \]](images/procstat_freq0616.png)
Logit Estimator
The adjusted logit estimate of the common relative risk for column 1 is computed as
![\[ \mathit{RR}_{\mi{L}} = \exp \left( \sum _ h w_ h \ln (\mathit{RR}_ h) ~ / ~ \sum w_ h \right) \]](images/procstat_freq0617.png)
and the corresponding % confidence limits are
![\[ \left( ~ \mathit{RR}_{\mi{L}} \times \exp \left( -z ~ / ~ \sqrt {\sum _ h w_ h} \right), ~ ~ \mathit{RR}_{\mi{L}} \times \exp \left( z ~ / ~ \sqrt {\sum _ h w_ h} \right) ~ \right) \]](images/procstat_freq0618.png)
where 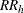 is the column 1 relative risk estimate for stratum h and
is the column 1 relative risk estimate for stratum h and
![\[ w_ h = 1 ~ / ~ \mbox{Var}( \ln ( \mathit{RR}_ h ) ) \]](images/procstat_freq0620.png)
If or 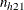 is 0, PROC FREQ adds 0.5 to each cell of the stratum before computing and for the logit estimate. The procedure prints a warning when this occurs. For more information, see Kleinbaum, Kupper, and
Morgenstern (1982, Sections 17.4 and 17.5).
is 0, PROC FREQ adds 0.5 to each cell of the stratum before computing and for the logit estimate. The procedure prints a warning when this occurs. For more information, see Kleinbaum, Kupper, and
Morgenstern (1982, Sections 17.4 and 17.5).
Breslow-Day Test for Homogeneity of the Odds Ratios
When you specify the CMH option, PROC FREQ computes the Breslow-Day test for stratified tables. It tests the null hypothesis that the odds ratios for the q strata are equal. When the null hypothesis is true, the statistic has approximately a chi-square distribution with q–1 degrees of freedom. See Breslow and Day (1980) and Agresti (2007) for more information.
The Breslow-Day statistic is computed as
![\[ Q_{\mi{BD}} = \sum _ h \left( n_{h11} - \mr{E}( n_{h11}~ |~ \mathit{OR}_{\mi{MH}} ) \right)^2 ~ / ~ \mr{Var}( n_{h11}~ |~ \mathit{OR}_{\mi{MH}} ) \]](images/procstat_freq0622.png)
where E and Var denote expected value and variance, respectively. The summation does not include any table that contains
a row or column that has a total frequency of 0. If 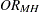 equals 0 or if it is undefined, PROC FREQ does not compute the statistic and prints a warning message.
equals 0 or if it is undefined, PROC FREQ does not compute the statistic and prints a warning message.
For the Breslow-Day test to be valid, the sample size should be relatively large in each stratum, and at least 80% of the
expected cell counts should be greater than 5. Note that this is a stricter sample size requirement than the requirement for
the Cochran-Mantel-Haenszel test for 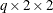 tables, in that each stratum sample size (not just the overall sample size) must be relatively large. Even when the Breslow-Day
test is valid, it might not be very powerful against certain alternatives, as discussed in Breslow and Day (1980).
tables, in that each stratum sample size (not just the overall sample size) must be relatively large. Even when the Breslow-Day
test is valid, it might not be very powerful against certain alternatives, as discussed in Breslow and Day (1980).
If you specify the BDT option, PROC FREQ computes the Breslow-Day test with Tarone’s adjustment, which subtracts an adjustment
factor from 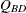 to make the resulting statistic asymptotically chi-square. The Breslow-Day-Tarone statistic is computed as
to make the resulting statistic asymptotically chi-square. The Breslow-Day-Tarone statistic is computed as
![\[ Q_{\mi{BDT}} = Q_{\mi{BD}} ~ - ~ \left( \sum _ h \left( n_{h11} - \mr{E}(n_{h11}~ |~ \mathit{OR}_{\mi{MH}}) \right) \right) ^2 ~ / ~ \sum _ h \mr{Var} (n_{h11}~ |~ \mathit{OR}_{\mi{MH}}) \]](images/procstat_freq0626.png)
See Tarone (1985); Jones et al. (1989); Breslow (1996) for more information.
Zelen’s Exact Test for Equal Odds Ratios
If you specify the EQOR option in the EXACT statement, PROC FREQ computes Zelen’s exact test for equal odds ratios for stratified
tables. Zelen’s test is an exact counterpart to the Breslow-Day asymptotic test for equal odds ratios. The reference set
for Zelen’s test includes all possible tables with the same row, column, and stratum totals as the observed multiway table and with the same sum of cell (1,1) frequencies
as the observed table. The test statistic is the probability of the observed table conditional on the fixed margins, which is a product of hypergeometric probabilities.
The p-value for Zelen’s test is the sum of all table probabilities that are less than or equal to the observed table probability, where the sum is computed over all tables in the reference set determined by the fixed margins and the observed sum of cell (1,1) frequencies. This test is similar to Fisher’s exact test for two-way tables. For more information, see Zelen (1971); Hirji (2006); Agresti (1992). PROC FREQ computes Zelen’s exact test by using the polynomial multiplication algorithm of Hirji et al. (1996).
Exact Confidence Limits for the Common Odds Ratio
If you specify the COMOR option in the EXACT statement, PROC FREQ computes exact confidence limits for the common odds ratio
for stratified tables. This computation assumes that the odds ratio is constant over all the tables. Exact confidence limits are constructed from the distribution of 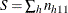 , conditional on the marginal totals of the tables.
, conditional on the marginal totals of the tables.
Because this is a discrete problem, the confidence coefficient for these exact confidence limits is not exactly 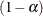 but is at least . Thus, these confidence limits are conservative. See Agresti (1992) for more information.
but is at least . Thus, these confidence limits are conservative. See Agresti (1992) for more information.
PROC FREQ computes exact confidence limits for the common odds ratio by using an algorithm based on Vollset, Hirji, and Elashoff (1991). See also Mehta, Patel, and Gray (1985).
Conditional on the marginal totals of table h, let the random variable 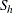 denote the frequency of table cell (1,1). Given the row totals
denote the frequency of table cell (1,1). Given the row totals 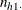 and
and 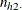 and column totals
and column totals 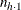 and
and 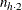 , the lower and upper bounds for
, the lower and upper bounds for 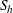 are
are 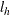 and
and 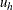 ,
,
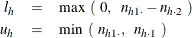
Let 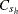 denote the hypergeometric coefficient,
denote the hypergeometric coefficient,
![\[ C_{s_ h} = \binom { n_{h \cdot 1} }{ s_ h } \binom { n_{h \cdot 2} }{ n_{h 1 \cdot } - s_ h } \]](images/procstat_freq0638.png)
and let  denote the common odds ratio. Then the conditional distribution of is
denote the common odds ratio. Then the conditional distribution of is
![\[ P (~ S_ h = s_ h ~ | ~ n_{1 \cdot }, ~ n_{\cdot 1}, ~ n_{\cdot 2}~ ) = C_{s_ h} ~ \phi ^{~ s_ h} ~ / ~ \sum _{x~ =~ l_ h}^{x~ =~ u_ h} ~ C_{x} ~ \phi ^{~ x} \]](images/procstat_freq0640.png)
Summing over all the tables, 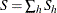 , and the lower and upper bounds of S are l and u,
, and the lower and upper bounds of S are l and u,
![\[ l = \sum _ h l_ h \hspace{.2in} \mr{and} \hspace{.2in} u = \sum _ h u_ h \]](images/procstat_freq0642.png)
The conditional distribution of the sum S is
![\[ P (~ S = s ~ | ~ n_{h1 \cdot }, ~ n_{h\cdot 1}, ~ n_{h\cdot 2};~ ~ h = 1, \ldots , q ~ ) = C_{s} ~ \phi ^{~ s} ~ / ~ \sum _{x~ =~ l}^{x~ =~ u} ~ C_{x} ~ \phi ^{~ x} \]](images/procstat_freq0643.png)
where
![\[ C_{s} = \sum _{s_1 + \cdots + s_ q ~ = ~ s} ~ \left( ~ \prod _ h ~ C_{s_ h} ~ \right) \]](images/procstat_freq0644.png)
Let 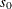 denote the observed sum of cell (1,1) frequencies over the q tables. The following two equations are solved iteratively for lower and upper confidence limits for the common odds ratio,
denote the observed sum of cell (1,1) frequencies over the q tables. The following two equations are solved iteratively for lower and upper confidence limits for the common odds ratio,
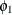 and
and 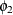 :
:
![\begin{eqnarray*} \sum _{x~ =~ s_0}^{x~ =~ u} ~ C_ x ~ \phi _1^{~ x} ~ / ~ \sum _{x~ =~ l}^{x~ =~ u} ~ C_ x ~ \phi _1^{~ x} & = & \alpha / 2 \\[0.10in] \sum _{x~ =~ l}^{x~ =~ s_0} ~ C_ x ~ \phi _2^{~ x} ~ / ~ \sum _{x~ =~ l}^{x~ =~ u} ~ C_ x ~ \phi _2^{~ x} & = & \alpha / 2 \end{eqnarray*}](images/procstat_freq0646.png)
When the observed sum equals the lower bound l, PROC FREQ sets the lower confidence limit to 0 and determines the upper limit with level  . Similarly, when the observed sum equals the upper bound u, PROC FREQ sets the upper confidence limit to infinity and determines the lower limit with level .
. Similarly, when the observed sum equals the upper bound u, PROC FREQ sets the upper confidence limit to infinity and determines the lower limit with level .
When you specify the COMOR option in the EXACT statement, PROC FREQ also computes the exact test that the common odds ratio
equals one. Setting 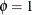 , the conditional distribution of the sum S under the null hypothesis becomes
, the conditional distribution of the sum S under the null hypothesis becomes
![\[ P_0 (~ S = s ~ | ~ n_{h1 \cdot }, ~ n_{h\cdot 1}, ~ n_{h\cdot 2};~ ~ h = 1, \ldots , q ~ ) = C_{s} ~ / ~ \sum _{x~ =~ l}^{x~ =~ u} ~ C_{x} \]](images/procstat_freq0648.png)
The point probability for this exact test is the probability of the observed sum under the null hypothesis, conditional on the marginals of the stratified tables, and is denoted by 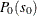 . The expected value of S under the null hypothesis is
. The expected value of S under the null hypothesis is
![\[ \mr{E}_0(S) = \sum _{x~ =~ l}^{x~ =~ u} x ~ C_{x} ~ / ~ \sum _{x~ =~ l}^{x~ =~ u} C_{x} \]](images/procstat_freq0650.png)
The one-sided exact p-value is computed from the conditional distribution as 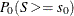 or
or 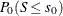 , depending on whether the observed sum is greater or less than
, depending on whether the observed sum is greater or less than 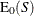 ,
,
![\begin{eqnarray*} P_{1} & =& P_0(~ S >= s_0~ ) = \sum _{x~ =~ s_0}^{x~ =~ u} C_ x ~ / ~ \sum _{x~ =~ l}^{x~ =~ u} C_{x} \hspace{.2in} \mr{if} \hspace{.1in} s_0 > \mr{E}_0(S) \\[0.10in] P_{1} & =& P_0(~ S <= s_0~ ) = \sum _{x~ =~ l}^{x~ =~ s_0} C_ x ~ / ~ \sum _{x~ =~ l}^{x~ =~ u} C_{x} \hspace{.2in} \mr{if} \hspace{.1in} s_0 \leq \mr{E}_0(S) \end{eqnarray*}](images/procstat_freq0654.png)
PROC FREQ computes two-sided p-values for this test according to three different definitions. A two-sided p-value is computed as twice the one-sided p-value, setting the result equal to one if it exceeds one,
![\[ P_{2}^{~ a} = 2 \times P_{1} \]](images/procstat_freq0655.png)
In addition, a two-sided p-value is computed as the sum of all probabilities less than or equal to the point probability of the observed sum , summing over all possible values of s, 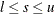 ,
,
![\[ P_{2}^{~ b} = \sum _{l \leq s \leq u: P_0(s) \leq P_0(s_0)} P_0( s ) \]](images/procstat_freq0657.png)
Also, a two-sided p-value is computed as the sum of the one-sided p-value and the corresponding area in the opposite tail of the distribution, equidistant from the expected value,
![\[ P_{2}^{~ c} = P_0~ ( ~ | S - \mr{E}_0(S) | ~ \geq ~ | s_0 - \mr{E}_0(S) | ~ ) \]](images/procstat_freq0658.png)