| The NLP Procedure |
Example 6.5 Approximate Standard Errors
The NLP procedure provides a variety of ways for estimating parameters in nonlinear statistical models and for obtaining approximate standard errors and covariance matrices for the estimators. These methods are illustrated by estimating the mean of a random sample from a normal distribution with mean 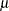 and standard deviation
and standard deviation  . The simplicity of the example makes it easy to compare the results of different methods in NLP with the usual estimator, the sample mean.
. The simplicity of the example makes it easy to compare the results of different methods in NLP with the usual estimator, the sample mean.
The following data step is used:
data x; input x @@; datalines; 1 3 4 5 7 ;
The standard error of the mean, computed with 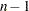 degrees of freedom, is 1. The usual maximum-likelihood approximation to the standard error of the mean, using a variance divisor of
degrees of freedom, is 1. The usual maximum-likelihood approximation to the standard error of the mean, using a variance divisor of  rather than , is 0.894427.
rather than , is 0.894427.
The sample mean is a least squares estimator, so it can be computed using an LSQ statement. Moreover, since this model is linear, the Hessian matrix and crossproduct Jacobian matrix are identical, and all three versions of the COV= option yield the same variance and standard error of the mean. Note that COV=j means that the crossproduct Jacobian is used. This is chosen because it requires the least computation.
proc nlp data=x cov=j pstderr pshort PHISTORY; lsq resid; parms mean=0; resid=x-mean; run;
The results are the same as the usual estimates.
| Optimization Results | ||||||
|---|---|---|---|---|---|---|
| Parameter Estimates | ||||||
| N | Parameter | Estimate | Approx Std Err |
t Value | Approx Pr > |t| |
Gradient Objective Function |
| 1 | mean | 4.000000 | 1.000000 | 4.000000 | 0.016130 | 8.881784E-15 |
PROC NLP can also compute maximum-likelihood estimates of and . In this case it is convenient to minimize the negative log likelihood. To get correct standard errors for maximum-likelihood estimators, the SIGSQ=1 option is required. The following program shows COV=1 but the output that follows has COV=2 and COV=3.
proc nlp data=x cov=1 sigsq=1 pstderr phes pcov pshort;
min nloglik;
parms mean=0, sigma=1;
bounds 1e-12 < sigma;
nloglik=.5*((x-mean)/sigma)**2 + log(sigma);
run;
The variance divisor is instead of , so the standard error of the mean is 0.894427 instead of 1. The standard error of the mean is the same with all six types of covariance matrix, but the standard error of the standard deviation varies. The sampling distribution of the standard deviation depends on the higher moments of the population distribution, so different methods of estimation can produce markedly different estimates of the standard error of the standard deviation.
Output 6.5.2 shows the output when COV=1, Output 6.5.3 shows the output when COV=2, and Output 6.5.4 shows the output when COV=3.
| Optimization Results | ||||||
|---|---|---|---|---|---|---|
| Parameter Estimates | ||||||
| N | Parameter | Estimate | Approx Std Err |
t Value | Approx Pr > |t| |
Gradient Objective Function |
| 1 | mean | 4.000000 | 0.894427 | 4.472136 | 0.006566 | 1.331492E-10 |
| 2 | sigma | 2.000000 | 0.458258 | 4.364358 | 0.007260 | -5.606415E-9 |
| Hessian Matrix | ||
|---|---|---|
| mean | sigma | |
| mean | 1.2500000028 | -1.33149E-10 |
| sigma | -1.33149E-10 | 2.500000014 |
| Covariance Matrix 1: M = (NOBS/d) inv(G) JJ(f) inv(G) |
||
|---|---|---|
| mean | sigma | |
| mean | 0.8 | 1.906775E-11 |
| sigma | 1.906775E-11 | 0.2099999991 |
| Optimization Results | ||||||
|---|---|---|---|---|---|---|
| Parameter Estimates | ||||||
| N | Parameter | Estimate | Approx Std Err |
t Value | Approx Pr > |t| |
Gradient Objective Function |
| 1 | mean | 4.000000 | 0.894427 | 4.472136 | 0.006566 | 1.331492E-10 |
| 2 | sigma | 2.000000 | 0.632456 | 3.162278 | 0.025031 | -5.606415E-9 |
| Hessian Matrix | ||
|---|---|---|
| mean | sigma | |
| mean | 1.2500000028 | -1.33149E-10 |
| sigma | -1.33149E-10 | 2.500000014 |
| Covariance Matrix 2: H = (NOBS/d) inv(G) |
||
|---|---|---|
| mean | sigma | |
| mean | 0.7999999982 | 4.260769E-11 |
| sigma | 4.260769E-11 | 0.3999999978 |
| Optimization Results | ||||||
|---|---|---|---|---|---|---|
| Parameter Estimates | ||||||
| N | Parameter | Estimate | Approx Std Err |
t Value | Approx Pr > |t| |
Gradient Objective Function |
| 1 | mean | 4.000000 | 0.509136 | 7.856442 | 0.000537 | 1.338402E-10 |
| 2 | sigma | 2.000000 | 0.419936 | 4.762634 | 0.005048 | -5.940302E-9 |
| Hessian Matrix | ||
|---|---|---|
| mean | sigma | |
| mean | 1.2500000028 | -1.33149E-10 |
| sigma | -1.33149E-10 | 2.500000014 |
| Covariance Matrix 3: J = (1/d) inv(W) | ||
|---|---|---|
| mean | sigma | |
| mean | 0.2592197879 | 1.091093E-11 |
| sigma | 1.091093E-11 | 0.1763460041 |
Under normality, the maximum-likelihood estimators of and are independent, as indicated by the diagonal Hessian matrix in the previous example. Hence, the maximum-likelihood estimate of can be obtained by using any fixed value for , such as 1. However, if the fixed value of differs from the actual maximum-likelihood estimate (in this case 2), the model is misspecified and the standard errors obtained with COV=2 or COV=3 are incorrect. It is therefore necessary to use COV=1, which yields consistent estimates of the standard errors under a variety of forms of misspecification of the error distribution.
proc nlp data=x cov=1 sigsq=1 pstderr pcov pshort; min sqresid; parms mean=0; sqresid=.5*(x-mean)**2; run;
This formulation produces the same standard error of the mean, 0.894427 (see Output 6.5.5).
| Optimization Results | ||||||
|---|---|---|---|---|---|---|
| Parameter Estimates | ||||||
| N | Parameter | Estimate | Approx Std Err |
t Value | Approx Pr > |t| |
Gradient Objective Function |
| 1 | mean | 4.000000 | 0.894427 | 4.472136 | 0.006566 | 0 |
The maximum-likelihood formulation with fixed is actually a least squares problem. The objective function, parameter estimates, and Hessian matrix are the same as those in the first example in this section using the LSQ statement. However, the Jacobian matrix is different, each row being multiplied by twice the residual. To treat this formulation as a least squares problem, the SIGSQ=1 option can be omitted. But since the Jacobian is not the same as in the formulation using the LSQ statement, the COV=1 | M and COV=3 | J options, which use the Jacobian, do not yield correct standard errors. The correct standard error is obtained with COV=2 | H, which uses only the Hessian matrix:
proc nlp data=x cov=2 pstderr pcov pshort; min sqresid; parms mean=0; sqresid=.5*(x-mean)**2; run;
The results are the same as in the first example.
| Optimization Results | ||||||
|---|---|---|---|---|---|---|
| Parameter Estimates | ||||||
| N | Parameter | Estimate | Approx Std Err |
t Value | Approx Pr > |t| |
Gradient Objective Function |
| 1 | mean | 4.000000 | 0.500000 | 8.000000 | 0.001324 | 0 |
In summary, to obtain appropriate standard errors for least squares estimates, you can use the LSQ statement with any of the COV= options, or you can use the MIN statement with COV=2. To obtain appropriate standard errors for maximum-likelihood estimates, you can use the MIN statement with the negative log likelihood or the MAX statement with the log likelihood, and in either case you can use any of the COV= options provided that you specify SIGSQ=1. You can also use a log-likelihood function with a misspecified scale parameter provided that you use SIGSQ=1 and COV=1. For nonlinear models, all of these methods yield approximations based on asymptotic theory, and should therefore be interpreted cautiously.
Copyright © SAS Institute, Inc. All Rights Reserved.