Model Fitting: Robust Regression
The example in Chapter 21: Model Fitting: Linear Regression, models 1987 salaries of Major League Baseball players as a function of several explanatory variables in the Baseball data set by using ordinary least squares regression. In that example, two conclusions are reached:
-
no_home, the number of home runs is not a significant variable in the model. -
Several players are high leverage points. Pete Rose has the highest leverage because of his 25 years in the major leagues. Graig Nettles and Steve Sax are leverage points and also outliers.
However, the model fitted by using ordinary least squares is influenced by high leverage points and outliers. Robust regression
is a preferable method of detecting influential observations. This example uses the Robust Regression analysis to identify
leverage points and outliers in the Baseball data.
To model the logarithm of salary by using no_hits and yr_major as explanatory variables:
-
Open the
Baseballdata set.The following two steps are the same as for the example in the Example: Fit a Linear Regression Model section in Chapter 21:
-
Use the Variable Transformation Wizard to create a new variable,
Log10_salary, which contains the logarithmic transformation of thesalaryvariable. -
Choose
nameto be the label variable for these data.The following steps model
Log10_salaryas a function of two explanatory variables. -
Select → → from the main menu, as shown in Figure 22.1.
The Robust Regression dialog box appears. (See Figure 22.2.)
-
Scroll to the end of the variable list. Select the
Log10_salary, and click . -
Select
no_hits. While holding down the CTRL key, selectyr_major. Click . -
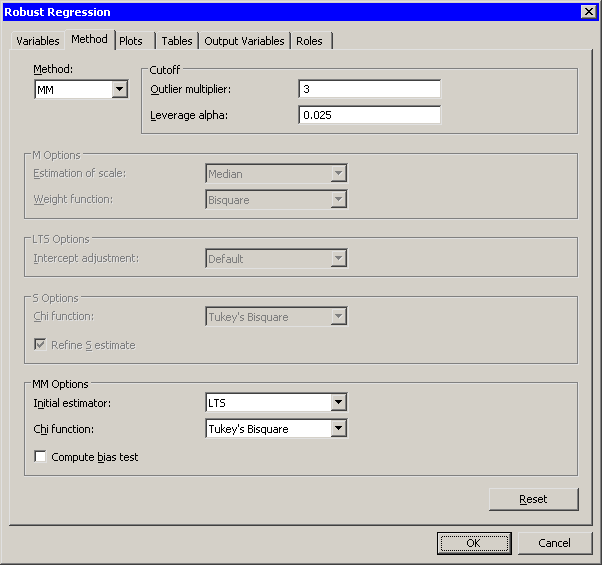
Click the Method tab.
The Method tab becomes active, as shown in Figure 22.3. There are four robust estimation methods. The default method, known as M estimation, is not robust in the presence of high leverage points. The LTS and MM methods are better suited for handling high leverage points.
-
Select for the method.
Note: If you use M estimation on data that contain leverage points, the ROBUSTREG procedure prints the following message to the error log:
WARNING: The data set contains one or more high leverage points, for which M estimation is not robust. It is recommended that you use METHOD=LTS or METHOD=MM for this data set.
-
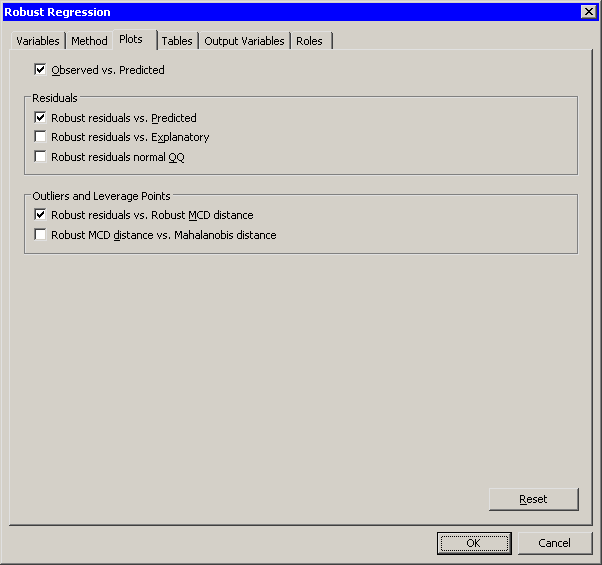
Click the Plots tab.
The Plots tab becomes active, as shown in Figure 22.4. This tab controls which graphs are produced by the analysis. One plot is selected by default. For this example, select the following additional plots:
-
Select .
-
Select .
-
Click the Output Variables tab.
The Output Variables tab becomes active, as shown in Figure 22.5. This tab controls which analysis variables are added to the data table.
-
Select .
Note that the and options are selected by default. These options create indicator variables in the data table that you can use to identify outliers and leverage points.
-
Click to run the analysis.
Several plots appear, along with output from the ROBUSTREG procedure. Some plots might be hidden beneath others. Move the windows so that they are arranged as in Figure 22.6. In the figure, five players are selected to facilitate comparison with Figure 21.9 and Figure 21.12.

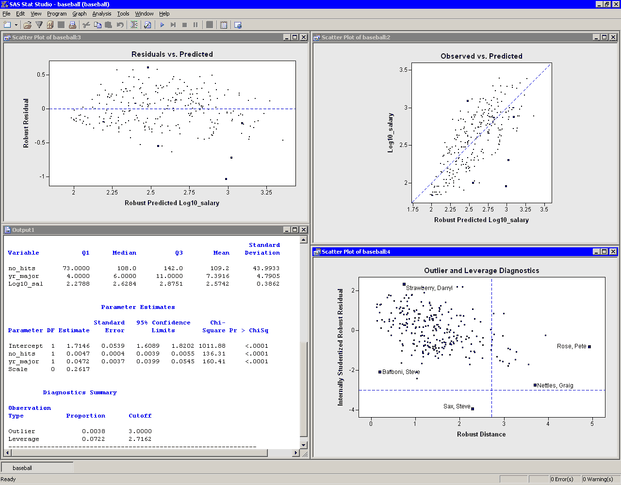
The plots that display predicted values are similar to those in Figure 21.9. The Residuals vs. Predicted plot does not show any obvious trends. The Observed vs. Predicted plot shows a reasonable fit, with a few exceptions.
The plot of (internally) studentized robust residuals versus robust distance (known as an RD plot) identifies which observations are outliers and which are high leverage points. Observations outside the horizontal lines at
![]() are outliers; observations to the right of the vertical line at 2.7162 are leverage points. The values of the outlier and
leverage cutoffs are displayed in the "Diagnostics Summary" table in the output window. You can control these values from
the Method tab.
are outliers; observations to the right of the vertical line at 2.7162 are leverage points. The values of the outlier and
leverage cutoffs are displayed in the "Diagnostics Summary" table in the output window. You can control these values from
the Method tab.
The robust regression model identifies Steve Sax as an outlier and identifies 19 other players (including Pete Rose and Graig Nettles) as leverage points. As displayed in the "Diagnostics Summary" table, these 19 players represent 7.2% of the 263 observations used in the analysis. (For comparison, the analysis in Chapter 21: Model Fitting: Linear Regression, suggests 11 outliers and 16 leverage points.)