Visualizing Data Features across Subsets of Data
Suppose that you are interested in visualizing the location of tropical cyclones for each month (irrespective of the year). That is, you want to examine a scatter plot that shows the location of all April cyclones, another that shows the locations of May cyclones, and so on. There are at least two methods to accomplish this:
-
One approach is to create a bar chart of months, select a bar (that is, a particular month) in the bar chart, and look at the selected observations in a scatter plot of wind_kts versus latitude. This technique is illustrated in Figure 12.2.
This works well for many data sets. However, the selected observations might not be visible when the scatter plot suffers from overplotting (as in Figure 12.2), or when the number of selected observations is small relative to the total number of observations. A variation of this technique is to show only the selected observations. See the section Displaying Only Selected Observations for a complete example that illustrates this approach.
Overplotting can also make it difficult to compare features of the data across months. For example, in Figure 12.2, do early-summer cyclones originate in the same regions as autumn cyclones? Does the general shape of cyclone trajectories vary by month?
Figure 12.2 Selecting Cyclones in Certain Months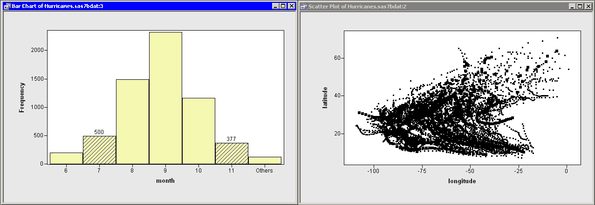
A second visualization approach, known as BY-group processing, attempts to circumvent these problems by abandoning the concept of viewing all of the data in one plot. The idea behind BY-group processing is simple: instead of using a single scatter plot linked to a bar chart, you subset the data into mutually exclusive BY groups and make a scatter plot for each subset. This enables you to see each month’s data in isolation, rather than superimposed on a single plot.