SELECT Statement
Retrieves columns and rows of data from tables.
| Categories: | Data Definition |
| Data Manipulation | |
| Supports: | EXECUTE Statement |
| Data source: | SAS data set, SPD Engine data set, SPD Server table, Aster, DB2 under UNIX and PC, Greenplum, HAWQ, HDMD, Hive, Impala, MDS, MySQL, Netezza, ODBC, Oracle, PostgreSQL, SAP, SAP HANA, Sybase IQ, Teradata |
Syntax
[{AND | OR} [NOT] {<sql-expression> | (<search-condition>)}]}]
Arguments
Details
Overview
-
The single row SELECT statement, which can be executed by itself, returns only one row. For example:
select 42; select 42 as x;
The first code fragment returns a single column that contains the value 42. The column is named “column”. The second code fragment returns a similar column. However, the column is named “x”. -
A query specification begins with the SELECT keyword (called a SELECT clause) and cannot be used by itself. It reads column values from one or more tables and enables you to define conditions for the data that will be returned from the tables. It must be used as a part of another SQL statement and can return more than one row. A query specification creates a virtual table. For example:
select column(s) from table(s) where condition(s);
SELECT Clause
Description
Syntax
Arguments
ALL
includes all rows, including duplicate rows in the result table.
DISTINCT
eliminates duplicate rows in the result table.
<select-list>
specifies the columns to be selected for the result table.
*
selects all columns in the table that is listed in the FROM clause.
column-alias
assigns a temporary, alternate name to the column.
column [AS column-alias]
selects a single column. When [AS column-alias] is specified, assigns the column alias to the column.
<query-specification>
specifies an embedded SELECT subquery.
| See | Overview of Subqueries |
<sql-expression> [AS column-alias]
derives a column name from an expression.
| See | <sql-expression> |
table.*
selects all columns in the table.
table-alias.*
selects all columns in the table.
| See | Table Aliases |
table.column [AS column-alias]
selects a single column from the specified table.
Asterisk (*) Notation
Column Aliases
FROM Clause
Description
Syntax
Arguments
CONNECTION TO catalog (<native-syntax>) [[AS] alias]
specifies data from a DBMS catalog by using the SQL pass-through facility. You can use SQL syntax that the DBMS understands, even if that syntax is not valid in FedSQL. For more information, see FedSQL Explicit Pass-Through Facility.
CROSS JOIN
defines a join that is the Cartesian product of two tables.
| See | Cross Joins |
JOIN
defines a join that enables you to filter the data by using a search condition or by using specific columns.
| See | Qualified Joins |
NATURAL JOIN
defines a join that selects rows from two tables that have equal values in columns that share the same name and the same type.
| See | Natural Joins |
(<query-specification>) [AS] alias
specifies an embedded SELECT subquery that functions as an in-line view. alias defines a temporary name for the in-line view and is required. An in-line view saves you a programming step. Rather than creating a view and referring to it in another query, you can specify the view in-line in the FROM clause.
| See | Overview of Subqueries |
table
specifies the name of a table. The name can be in any of the forms described for table.
table-alias
specifies a temporary, alternate name for table. The AS keyword is optional.
INNER
specifies that only the subset of rows from the first table that matches rows from the second table are returned. Unmatched rows from both tables are discarded.
LEFT [OUTER]
specifies that matching rows and rows from the first table that do not match any row in the second table are returned.
RIGHT [OUTER]
specifies that matching rows and rows from the second table that do not match any row in the first table are returned.
FULL [OUTER]
species that all matching and unmatching rows from the first and second table are returned.
column
specifies the name of a column.
ON <search-condition>
specifies a condition join used to match rows from one table to another. If the search condition is satisfied, the matching rows are added to the result table.
| See | <search-condition> |
USING (column [,...column])
specifies which columns to use in an inner or outer join.
| See | ON and USING Clauses |
Overview
Table Aliases
Joined Tables
Specifying the Rows to Be Returned
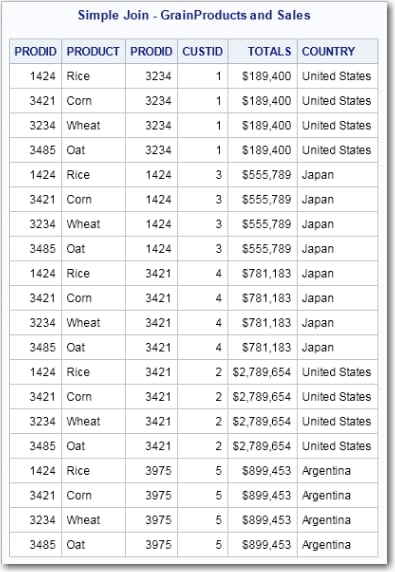
Simple Joins
/* FedSQL code for simple join */ proc fedsql; title 'Simple Join - GrainProducts and Sales'; select * from grainproducts, sales; quit;
/* FedSQL code for equijoin */
proc fedsql;
title 'Equijoin - GrainProducts and Sales';
select * from grainproducts, sales
where grainproducts.prodid=sales.prodid;
quit; 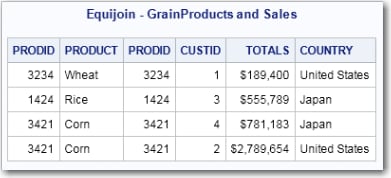
Cross Joins
select * from grainproducts, sales;
select * from grainproducts cross join sales;
Qualified Joins
Inner Joins

proc fedsql;
title 'Inner Join - GrainProducts and Sales';
select *
from grainproducts inner join sales
on grainproducts.prodid=sales.prodid;
quit;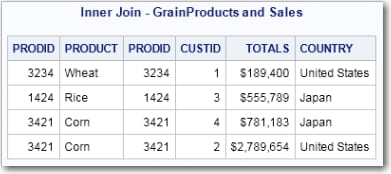
select *
from grainproducts inner join sales
on grainproducts.prodid=sales.prodid;select *
from grainproducts inner join sales
using (prodid);This code produces the same output
as the previous code but uses the inner join construction. select *
from grainproducts, sales
where grainproducts.prodid=sales.prodid; Outer Joins
Left Outer Joins

title 'Left Outer Join - GrainProducts and Sales';
select *
from grainproducts left outer join sales
on grainproducts.prodid=sales.prodid;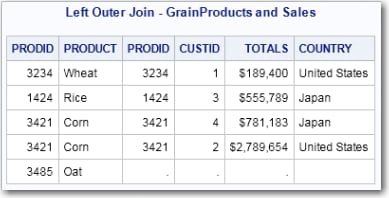
Right Outer Joins

title 'Right Outer Join - GrainProducts and Sales';
select *
from grainproducts right outer join sales
on grainproducts.prodid=sales.prodid;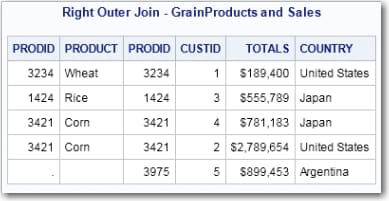
Full Outer Joins

title 'Full Outer Join - GrainProducts and Sales';
select *
from grainproducts full outer join sales
on grainproducts.prodid=sales.prodid;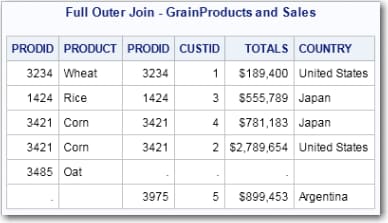
ON and USING Clauses
United
States from the results table.title 'Inner Join - GrainProducts and Sales Outside US';
select *
from grainproducts inner join sales
on sales.country <> 'United States'
AND grainproducts.prodid=sales.prodid;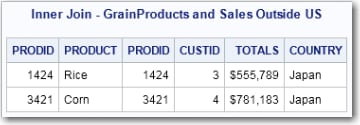
Natural Joins
title 'Natural Left Outer Join - GrainProducts and Sales'; select * from grainproducts natural left outer join sales;
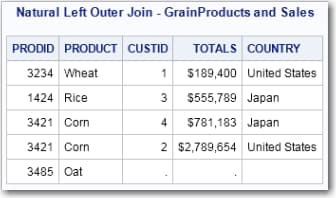
WHERE Clause
Description
Syntax
Arguments
<search-condition>
specifies the conditions for the rows returned by the WHERE clause.
| See | <search-condition> |
Details
where max(inventory1)>10000;However, you can use this WHERE clause.
where max(inventory1, inventory2)>10000;
GROUP BY Clause
Description
Syntax
Arguments
column
specifies the name of a column or a column alias.
column-position-number
specifies a nonnegative integer that equates to a column position.
<sql-expression>
specifies a valid SQL expression.
| See | <sql-expression> |
Details
select x, sum(y) from table1 group by x;
select sum(x), y from table1 group by y;
HAVING Clause
Description
Syntax
Arguments
<search-condition>
specifies the conditions for the rows returned by the HAVING clause.
| See | <search-condition> |
Details
|
HAVING clause attributes
|
WHERE clause attributes
|
|---|---|
|
typically used to specify
conditions for including or excluding groups of rows from a table
|
used to specify conditions
for including or excluding individual rows from a table
|
|
must follow the GROUP
BY clause in a query, if used with a GROUP BY clause
|
must precede the GROUP
BY clause in a query, if used with a GROUP BY clause
|
|
affected by a GROUP
BY clause; when there is no GROUP BY clause, the HAVING clause is
treated like a WHERE clause
|
not affected by a GROUP
BY clause
|
|
processed after the
GROUP BY clause and any aggregate functions
|
processed before a GROUP
BY clause, if there is one, and before any aggregate functions
|
ORDER BY Clause
Description
Syntax
[, ...order-by-expression [COLLATE collating-sequence-options]]
Arguments
order-by-expression
specifies a column on which to sort. The sort column can be one of the following.
column
specifies the name of a column or a column alias.
column-position-number
specifies a nonnegative integer that equates to a column position.
<sql-expression>
specifies any valid SQL expression.
| See | <sql-expression> |
ASC
orders the data in ascending order. This is the default order; if ASC or DESC are not specified, the data is ordered in ascending order.
DESC
orders the data in descending order.
COLLATE collating-sequence-options
specifies linguistic collation, which sorts characters according to rules of the specified language. The rules and default collating sequence options are based on the language specified in the current locale setting. The implementation is provided by the International Components for Unicode (ICU) library and produces results that are largely compatible with the Unicode Collation Algorithms (UCA).
DANISH | FINNISH | ITALIAN | NORWEGIAN | POLISH | SPANISH | SWEDISH
sorts characters according to the language specified.
LINGUISTIC [collating-rules]
collating-rules can be one of the following values:
ALTERNATE_HANDLING=SHIFTED
controls the handling of variable characters like spaces, punctuation, and symbols. When this option is not specified (using the default value NON_IGNORABLE), differences among these variable characters are of the same importance as differences among letters. If the ALTERNATE_HANDLING option is specified, these variable characters are of minor importance.
| Default | NON_IGNORABLE |
| Tip | The SHIFTED value is often used in combination with STRENGTH= set to Quaternary. In such a case, spaces, punctuation, and symbols are considered when comparing strings, but only if all other aspects of the strings (base letters, accents, and case) are identical. |
CASE_FIRST=
specify order of uppercase and lowercase letters. This argument is valid for only TERTIARY, QUATERNARY, or IDENTICAL levels. The following table provides the values and information for the CASE_FIRST argument:
|
Value
|
Description
|
|
UPPER
|
Sorts uppercase letters
first, then the lowercase letters.
|
|
LOWER
|
Sorts lowercase letters
first, then the uppercase letters.
|
COLLATION=
The following table lists the available COLLATION= values. If you do not select a collation value, then the user's locale-default collation is selected.
|
Value
|
Description
|
|---|---|
|
BIG5HAN
|
specifies Pinyin ordering
for Latin and specifies big5 charset ordering for Chinese, Japanese,
and Korean characters.
|
|
DIRECT
|
specifies a Hindi variant.
|
|
GB2312HAN
|
specifies Pinyin ordering
for Latin and specifies gb2312han charset ordering for Chinese, Japanese,
and Korean characters.
|
|
PHONEBOOK
|
specifies a telephone-book
style for ordering of characters. Select PHONEBOOK only with the German
language.
|
|
PINYIN
|
specifies an ordering
for Chinese, Japanese, and Korean characters based on character-by-character
transliteration into Pinyin. This ordering is typically used with
simplified Chinese.
|
|
POSIX
|
is the Portable Operating
System Interface. This option specifies a "C" locale ordering
of characters.
|
|
STROKE
|
specifies a nonalphabetic
writing style ordering of characters. Select STROKE with Chinese,
Japanese, Korean, or Vietnamese languages. This ordering is typically
used with Traditional Chinese.
|
|
TRADITIONAL
|
specifies a traditional
style for ordering of characters. For example, select TRADITIONAL
with the Spanish language.
|
LOCALE= locale_name
specifies the locale name in the form of a POSIX name(for example, ja_JP). For more information, see SAS National Language Support (NLS): Reference Guide
NUMERIC_COLLATION=
orders integer values within the text by the numeric value instead of characters used to represent the numbers.
|
Value
|
Description
|
|
ON
|
Order numbers by the
numeric value. For example, "8 Main St." would sort before
"45 Main St.".
|
|
OFF
|
Order numbers by the
character value. For example, "45 Main St." would sort before
"8 Main St.".
|
| Default | OFF |
STRENGTH=
The value of strength is related to the collation level. There are five collation-level values. The following table provides information about the five levels. The default value for strength is related to the locale.
|
Value
|
Type of Collation
|
Description
|
|
PRIMARY or 1
|
PRIMARY specifies differences
between base characters (for example, "a" < "b").
|
It is the strongest
difference. For example, dictionaries are divided into different sections
by base character.
|
|
SECONDARY or 2
|
Accents in the characters
are considered secondary differences (for example, "as"
< "às" < "at").
|
A secondary difference
is ignored when there is a primary difference anywhere in the strings.
Other differences between letters can also be considered secondary
differences, depending on the language.
|
|
TERTIARY or 3
|
Upper and lowercase
differences in characters are distinguished at the tertiary level
(for example, "ao" < "Ao" < "aò").
|
A tertiary difference
is ignored when there is a primary or secondary difference anywhere
in the strings. Another example is the difference between large and
small Kana.
|
|
QUATERNARY or 4
|
When punctuation is
ignored at level 1–3, an additional level can be used to distinguish
words with and without punctuation (for example, "ab" <
"a-b" < "aB").
|
The quaternary level
should be used if ignoring punctuation is required or when processing
Japanese text. This difference is ignored when there is a primary,
secondary, or tertiary difference.
|
|
IDENTICAL or 5
|
When all other levels
are equal, the identical level is used as a tiebreaker. The Unicode
code point values of the Normalization Form D (NFD) form of each string
are compared at this level, just in case there is no difference at
levels 1–4.
|
This level should be
used sparingly, as only code point values differences between two
strings is an extremely rare occurrence. For example, only Hebrew
cantillation marks are distinguished at this level.
|
| Alias | LEVEL= |
| Restriction | Linguistic collation is not supported on platforms VMS on Itanium (VMI) or 64-bit Windows on Itanium (W64). |
| Tip | The collating-rules must be enclosed in parentheses. More than one collating rule can be specified. |
| See | ICU License - ICU 1.8.1 and later. |
| The section on Linguistic Collation in SAS National Language Support (NLS): Reference Guide. | |
| Refer to http://www.unicode.org for the Unicode Collation Algorithm (UCA) specification. |
Details
LIMIT Clause
Description
Syntax
Arguments
count
specifies the number of rows that the SELECT statement returns.
| Tip | count can be an integer or any simple expression that resolves to an integer value. |
ALL
specifies that all rows are returned.
Details
OFFSET Clause
Description
Syntax
Arguments
number
specifies the number of rows to skip.
| Tip | number can be an integer or any simple expression that resolves to an integer value. |
Details
UNION Operator
Descriptions
Syntax
Arguments
<query-specification> | <query-expression>
specifies one or more SELECT statements that produces a virtual table.
| See | SELECT Statement |
| Overview of Subqueries |
UNION
specifies that multiple result tables are combined and returned as a single result table.
ALL
specifies that all rows, including duplicates, are included in the result table. If not specified, all rows are returned.
DISTINCT
specifies that only unique rows can appear in the result table.
| See | DISTINCT Predicate |
Details
-
INTEGER UNION ALL BIGINT results in INTEGER
-
BIGINT UNION ALL INTEGER results in BIGINT
-
CHAR(20) UNION ALL CHAR(10) results in CHAR(20)
-
CHAR(10) UNION ALL CHAR(20) results in CHAR(10)
EXCEPT Operator
Description
Syntax
Arguments
<query-specification> | <query-expression>
specifies one or more SELECT statements that produces a virtual table.
| See | SELECT Statement |
| Overview of Subqueries |
EXCEPT
specifies that multiple result tables are combined and only those rows that are in the first result table and not in the second result table are included.
ALL
specifies that all rows, including duplicates, are included in the result table. If not specified, all rows are returned.
DISTINCT
specifies that only unique rows can appear in the result table.
| See | DISTINCT Predicate |
CORRESPONDING
specifies the columns to include in the query.
| Tip | If you do not specify the BY clause, the result table will include every column that appears in both of the tables. |
BY
specifies that only these columns be included in the result table.
column
specifies the name of the column.
| Restriction | Every column must be a valid column in both tables. |
Details
INTERSECT Operator
Description
Syntax
Arguments
<query-specification> | <query-expression>
specifies one or more SELECT statements that produces a virtual table.
| See | SELECT Statement |
| Overview of Subqueries |
INTERSECT
specifies that multiple result tables are combined and only those rows that are common to both result tables are included.
ALL
specifies that all rows, including duplicates, are included in the result table. If not specified, all rows are returned.
DISTINCT
specifies that only unique rows can appear in the result table.
| See | DISTINCT Predicate |
CORRESPONDING
specifies the columns to include in the query.
| Tip | If you do not specify the BY clause, the result table will include every column that appears in both of the tables. |
BY
specifies that only these columns to be included in the result table.
column
specifies the name of the column.
| Restriction | Every column must be a valid column in both tables. |
Details
<search-condition>
Description
Syntax
[{AND | OR} [NOT] {<sql-expression> | (<search-condition>)}]}]
Arguments
NOT
negates a Boolean condition. This table outlines the outcomes when you compare true and false values using the NOT operator.
|
NOT
|
Result
|
|---|---|
|
True
|
False
|
|
False
|
True
|
|
Unknown
|
Unknown
|
AND
combines two conditions by finding observations that satisfy both conditions. This table outlines the outcomes when you compare TRUE and FALSE values using the AND operator.
|
AND
|
True
|
False
|
Unknown
|
|---|---|---|---|
|
True
|
True
|
False
|
Unknown
|
|
False
|
False
|
False
|
|
|
Unknown
|
Unknown
|
False
|
Unknown
|
OR
combines two conditions by finding observations that satisfy either condition or both. This table outlines the outcomes when you compare TRUE and FALSE values using the OR operator.
|
OR
|
True
|
False
|
Unknown
|
|---|---|---|---|
|
True
|
True
|
True
|
True
|
|
False
|
True
|
False
|
Unknown
|
|
Unknown
|
True
|
Unknown
|
Unknown
|
<sql-expression>
specifies any valid SQL expression.
| See | <sql-expression> |
Details
select * from test where x = cast (1.0e20 as real); select cast (1.0e20 as real) from test; select cast (col1 as real) from test;