The COPULA Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsSklar’s TheoremDependence MeasuresNormal CopulaStudent’s t copulaArchimedean CopulasHierarchical Archimedean Copula (HAC)Canonical Maximum Likelihood Estimation (CMLE)Exact Maximum Likelihood Estimation (MLE)Calibration EstimationNonlinear Optimization OptionsDisplayed OutputOUTCOPULA= Data SetOUTPSEUDO=, OUT=, and OUTUNIFORM= Data SetsODS Table NamesODS Graph Names
-
Examples
- References
Canonical Maximum Likelihood Estimation (CMLE)
In the canonical maximum likelihood estimation (CMLE) method, it is assumed that the sample data 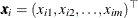 ,
, 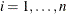 have been transformed into uniform variates
have been transformed into uniform variates 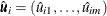 , . One commonly used transformation is the nonparametric estimation of the CDF of the marginal distributions, which is closely
related to empirical CDF,
, . One commonly used transformation is the nonparametric estimation of the CDF of the marginal distributions, which is closely
related to empirical CDF,
![\[ \hat{u}_{i,j}= \hat{F}_{j,n}(x_{i,j}) \]](images/etsug_copula0247.png)
where
![\[ \hat{F}_{j,n}(x) = \frac{1}{n+1}\sum _{i=1}^ n I_{[x_{i,j}\le x]} \]](images/etsug_copula0248.png)
The transformed data 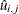 are used as if they had uniform marginal distributions; hence, they are called pseudo-samples. The function
are used as if they had uniform marginal distributions; hence, they are called pseudo-samples. The function 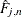 is different from the standard empirical CDF in the scalar
is different from the standard empirical CDF in the scalar 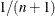 , which is to ensure that the transformed data cannot be on the boundary of the unit interval
, which is to ensure that the transformed data cannot be on the boundary of the unit interval ![$[0,1]$](images/etsug_copula0025.png) . It is clear that
. It is clear that
![\[ \hat{u}_{i,j} = \frac{1}{n+1} \textrm{rank}(x_{i,j}) \]](images/etsug_copula0252.png)
where 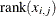 is the rank among in increasing order.
is the rank among in increasing order.
Let 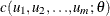 be the density function of a copula
be the density function of a copula 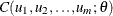 , and let
, and let 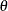 be the parameter vector to be estimated. The parameter is estimated by maximum likelihood:
be the parameter vector to be estimated. The parameter is estimated by maximum likelihood:
![\[ \hat{\theta } = \arg \max _{{\theta }\in {\Theta }} \sum _{i=1}^{n} \log c(\hat{u}_{i1}, {\ldots }, \hat{u}_{im}; {\theta }) \]](images/etsug_copula0256.png)