The SSM Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsState Space Model and NotationTypes of Sequence DataOverview of Model Specification SyntaxFiltering, Smoothing, Likelihood, and Structural Break DetectionEstimation of User-Specified Linear Combination of State ElementsContrasting PROC SSM with Other SAS Procedures Predefined Trend ModelsPredefined Structural ModelsCovariance ParameterizationMissing ValuesComputational IssuesDisplayed OutputODS Table NamesODS Graph NamesOUT= Data Set
-
ExamplesBivariate Basic Structural Model Panel Data: Two-Way Random-Effects and Autoregressive ModelsBackcasting, Forecasting, and InterpolationLongitudinal Data: Smoothing of Repeated MeasuresA User-Defined Trend ModelModel with Multiple ARIMA ComponentsDynamic Factor ModelingDiagnostic Plots and Structural Break AnalysisLongitudinal Data: Variable Bandwidth SmoothingA Transfer Function Model for the Gas Furnace DataPanel Data: Dynamic Panel Model for the Cigar DataMultivariate Modeling: Analysis of Long-Term Temperature Trends
- References
The state space model specification in the SSM procedure requires proper understanding of both the data organization and the form of the model. The SSMs that are appropriate for time series data might not be appropriate for irregularly spaced longitudinal data. The SSM procedure distinguishes three types of data organization based on the way the observations are sequenced by the index variable. If an index variable is not specified, it is assumed that the observations are sequenced according to the observation number.
- Regular:
-
The observations are recorded at regularly spaced intervals; that is,
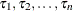 are regularly spaced. Moreover, at each observation instance
are regularly spaced. Moreover, at each observation instance 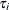 a single observation is recorded; that is,
a single observation is recorded; that is, 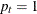 for all
for all  . The standard time series data (both univariate and multivariate) fall in this category.
. The standard time series data (both univariate and multivariate) fall in this category.
- Regular with Replication:
-
The observations are recorded at regularly spaced intervals, but
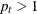 for at least one . Here the word replication is used loosely—it does not mean that the multiple observations at
for at least one . Here the word replication is used loosely—it does not mean that the multiple observations at 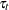 are replications in the precise statistical sense. The panel or cross-sectional data types fall into this category. In the
panel data case with
are replications in the precise statistical sense. The panel or cross-sectional data types fall into this category. In the
panel data case with 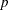 cross-sections,
cross-sections, 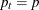 for all .
for all .
- Irregular:
-
The observations are not recorded at regular intervals, and the number of observations
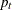 at each index instance can be different. The longitudinal data fall into this category.
at each index instance can be different. The longitudinal data fall into this category.
It is not always easy to decide whether the specified model is appropriate for the given data type. Whenever possible, the SSM procedure issues a note regarding the possible mismatch between the specified model and the data type being analyzed.