| The SEVERITY Procedure |
| An Example of Modeling Regression Effects |
Consider a scenario in which the magnitude of the response variable might be affected by some regressor (exogenous or independent) variables. The SEVERITY procedure enables you to model the effect of such variables on the distribution of the response variable via an exponential link function. In particular, if you have 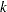 random regressor variables denoted by
random regressor variables denoted by  (
(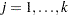 ), then the distribution of the response variable
), then the distribution of the response variable 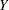 is assumed to have the form
is assumed to have the form
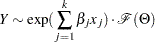 |
where 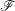 denotes the distribution of with parameters
denotes the distribution of with parameters 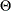 and
and 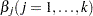 denote the regression parameters (coefficients). For the effective distribution of to be a valid distribution from the same parametric family as , it is necessary for to have a scale parameter. The effective distribution of can be written as
denote the regression parameters (coefficients). For the effective distribution of to be a valid distribution from the same parametric family as , it is necessary for to have a scale parameter. The effective distribution of can be written as
 |
where 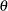 denotes the scale parameter and
denotes the scale parameter and 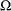 denotes the set of nonscale parameters. The scale is affected by the regressors as
denotes the set of nonscale parameters. The scale is affected by the regressors as
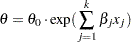 |
where 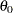 denotes a base value of the scale parameter.
denotes a base value of the scale parameter.
Given this form of the model, PROC SEVERITY allows a distribution to be a candidate for modeling regression effects only if it has an untransformed or a log-transformed scale parameter.
All the predefined distributions, except the lognormal distribution, have a direct scale parameter (that is, a parameter that is a scale parameter without any transformation). For the lognormal distribution, the parameter 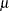 is a log-transformed scale parameter. This can be verified by replacing with a parameter
is a log-transformed scale parameter. This can be verified by replacing with a parameter 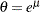 , which results in the following expressions for the PDF
, which results in the following expressions for the PDF 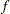 and the CDF
and the CDF 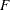 in terms of and
in terms of and  , respectively, where
, respectively, where 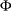 denotes the CDF of the standard normal distribution:
denotes the CDF of the standard normal distribution:
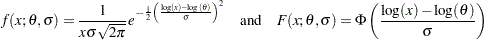 |
With this parameterization, the PDF satisfies the 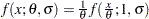 condition and the CDF satisfies the
condition and the CDF satisfies the 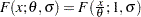 condition. This makes a scale parameter. Hence,
condition. This makes a scale parameter. Hence, 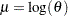 is a log-transformed scale parameter and the lognormal distribution is eligible for modeling regression effects.
is a log-transformed scale parameter and the lognormal distribution is eligible for modeling regression effects.
The following DATA step simulates a lognormal sample whose scale is decided by the values of the three regressors X1, X2, and X3 as follows:
 |
/*----------- Lognormal Model with Regressors ------------*/
data test_sev3(keep=y x1-x3
label='A Lognormal Sample Affected by Regressors');
array x{*} x1-x3;
array b{4} _TEMPORARY_ (1 0.75 -1 0.25);
call streaminit(45678);
label y='Response Influenced by Regressors';
Sigma = 0.25;
do n = 1 to 100;
Mu = b(1); /* log of base value of scale */
do i = 1 to dim(x);
x(i) = rand('UNIFORM');
Mu = Mu + b(i+1) * x(i);
end;
y = exp(Mu) * rand('LOGNORMAL')**Sigma;
output;
end;
run;
The following PROC SEVERITY step fits the lognormal, Burr, and gamma distribution models to this data. The regressors are specified in the MODEL statement.
proc severity data=test_sev3 print=all;
model y = x1-x3 / crit=aicc;
dist logn;
dist burr;
dist gamma;
run;
Some of the key results prepared by PROC SEVERITY are shown in Figure 22.12 through Figure 22.16. The descriptive statistics of all the variables are shown in Figure 22.12.
| Input Data Set | |
|---|---|
| Name | WORK.TEST_SEV3 |
| Label | A Lognormal Sample Affected by Regressors |
The comparison of the fit statistics of all the models is shown in Figure 22.13. It indicates that the lognormal model is the best model according to each of the likelihood-based statistics, whereas the gamma model is the best model according to two of the three EDF-based statistics.
The distribution information and the convergence results of the lognormal model are shown in Figure 22.14. The iteration history gives you a summary of how the optimizer is traversing the surface of the log-likelihood function in its attempt to reach the optimum. Both the change in the log likelihood and the maximum gradient of the objective function with respect to any of the parameters typically approach 0 if the optimizer converges.
| Distribution Information | |
|---|---|
| Name | Logn |
| Description | Lognormal Distribution |
| Number of Distribution Parameters | 2 |
| Number of Regression Parameters | 3 |
| Optimization Iteration History for Logn Distribution | ||||
|---|---|---|---|---|
| Iter | Number of Function Evaluations |
Log Likelihood | Change in Log Likelihood | Maximum Gradient |
| 0 | 2 | -93.75285 | . | 6.16002 |
| 1 | 4 | -93.74805 | 0.0048055 | 0.11031 |
| 2 | 6 | -93.74805 | 1.50188E-6 | 0.00003376 |
| 3 | 8 | -93.74805 | 1.1369E-13 | 3.1513E-12 |
| Optimization Summary for Logn Distribution | |
|---|---|
| Optimization Technique | Trust Region |
| Number of Iterations | 3 |
| Number of Function Evaluations | 8 |
| Log Likelihood | -93.74805 |
The final parameter estimates of the lognormal model are shown in Figure 22.15. All the estimates are significantly different from zero. The estimate that is reported for the parameter Mu is the base value for the log-transformed scale parameter . Let  denote the observed value for regressor X
denote the observed value for regressor X . If the lognormal distribution is chosen to model , then the effective value of the parameter varies with the observed values of regressors as
. If the lognormal distribution is chosen to model , then the effective value of the parameter varies with the observed values of regressors as
 |
These estimated coefficients are reasonably close to the population parameters (that is, within one or two standard errors).
The estimates of the gamma distribution model, which is the best model according to a majority of the EDF-based statistics, are shown in Figure 22.16. The estimate that is reported for the parameter Theta is the base value for the scale parameter . If the gamma distribution is chosen to model , then the effective value of the scale parameter is  .
.
Note: This procedure is experimental.
Copyright © SAS Institute, Inc. All Rights Reserved.