| The MODEL Procedure |
| Choice of Instruments |
Several of the estimation methods supported by PROC MODEL are instrumental variables methods. There is no standard method for choosing instruments for nonlinear regression. Few econometric textbooks discuss the selection of instruments for nonlinear models. See Bowden and Turkington (1984, pp. 180–182) for more information.
The purpose of the instrumental projection is to purge the regressors of their correlation with the residual. For nonlinear systems, the regressors are the partials of the residuals with respect to the parameters.
Possible instrumental variables include the following:
any variable in the model that is independent of the errors
lags of variables in the system
derivatives with respect to the parameters, if the derivatives are independent of the errors
low-degree polynomials in the exogenous variables
variables from the data set or functions of variables from the data set
Selected instruments must not have any of the following characteristics:
depend on any variable endogenous with respect to the equations estimated
depend on any of the parameters estimated
be lags of endogenous variables if there is serial correlation of the errors
If the preceding rules are satisfied and there are enough observations to support the number of instruments used, the results should be consistent and the efficiency loss held to a minimum.
You need at least as many instruments as the maximum number of parameters in any equation, or some of the parameters cannot be estimated. Note that number of instruments means linearly independent instruments. If you add an instrument that is a linear combination of other instruments, it has no effect and does not increase the effective number of instruments.
You can, however, use too many instruments. In order to get the benefit of instrumental variables, you must have more observations than instruments. Thus, there is a trade-off; the instrumental variables technique completely eliminates the simultaneous equation bias only in large samples. In finite samples, the larger the excess of observations over instruments, the more the bias is reduced. Adding more instruments might improve the efficiency, but after some point efficiency declines as the excess of observations over instruments becomes smaller and the bias grows.
The instruments used in an estimation are printed out at the beginning of the estimation. For example, the following statements produce the instruments list shown in Figure 18.57.
proc model data=test2;
exogenous x1 x2;
parms b1 a1 a2 b2 2.5 c2 55;
y1 = a1 * y2 + b1 * exp(x1);
y2 = a2 * y1 + b2 * x2 * x2 + c2 / x2;
fit y1 y2 / n2sls;
inst b1 b2 c2 x1 ;
run;
| The 2 Equations to Estimate | |
|---|---|
| y1 = | F(b1, a1(y2)) |
| y2 = | F(a2(y1), b2, c2) |
| Instruments | 1 x1 @y1/@b1 @y2/@b2 @y2/@c2 |
This states that an intercept term, the exogenous variable X1, and the partial derivatives of the equations with respect to B1, B2, and C2, were used as instruments for the estimation.
Examples
Suppose that Y1 and Y2 are endogenous variables, that X1 and X2 are exogenous variables, and that A, B, C, D, E, F, and G are parameters. Consider the following model:
y1 = a + b * x1 + c * y2 + d * lag(y1); y2 = e + f * x2 + g * y1; fit y1 y2; instruments exclude=(c g);
The INSTRUMENTS statement produces X1, X2, LAG(Y1), and an intercept as instruments.
In order to estimate the Y1 equation by itself, it is necessary to include X2 explicitly in the instruments since F, in this case, is not included in the following estimation:
y1 = a + b * x1 + c * y2 + d * lag(y1); y2 = e + f * x2 + g * y1; fit y1; instruments x2 exclude=(c);
This produces the same instruments as before. You can list the parameter associated with the lagged variable as an instrument instead of using the EXCLUDE= option. Thus, the following is equivalent to the previous example:
y1 = a + b * x1 + c * y2 + d * lag(y1); y2 = e + f * x2 + g * y1; fit y1; instruments x1 x2 d;
For an example of declaring instruments when estimating a model involving identities, consider Klein’s Model I:
proc model data=klien;
endogenous c p w i x wsum k y;
exogenous wp g t year;
parms c0-c3 i0-i3 w0-w3;
a: c = c0 + c1 * p + c2 * lag(p) + c3 * wsum;
b: i = i0 + i1 * p + i2 * lag(p) + i3 * lag(k);
c: w = w0 + w1 * x + w2 * lag(x) + w3 * year;
x = c + i + g;
y = c + i + g-t;
p = x-w-t;
k = lag(k) + i;
wsum = w + wp;
run;
The three equations to estimate are identified by the labels A, B, and C. The parameters associated with the predetermined terms are C2, I2, I3, W2, and W3 (and the intercepts, which are automatically added to the instruments). In addition, the system includes five identities that contain the predetermined variables G, T, LAG(K), and WP. Thus, the INSTRUMENTS statement can be written as
lagk = lag(k); instruments c2 i2 i3 w2 w3 g t wp lagk;
where LAGK is a program variable used to hold LAG(K). However, this is more complicated than it needs to be. Except for LAG(K), all the predetermined terms in the identities are exogenous variables, and LAG(K) is already included as the coefficient of I3. There are also more parameters for predetermined terms than for endogenous terms, so you might prefer to use the EXCLUDE= option. Thus, you can specify the same instruments list with the simpler statement
instruments _exog_ exclude=(c1 c3 i1 w1);
To illustrate the use of polynomial terms as instrumental variables, consider the following model:
y1 = a + b * exp( c * x1 ) + d * log( x2 ) + e * exp( f * y2 );
The parameters are A, B, C, D, E, and F, and the right-hand-side variables are X1, X2, and Y2. Assume that X1 and X2 are exogenous (independent of the error), while Y2 is endogenous. The equation for Y2 is not specified, but assume that it includes the variables X1, X3, and Y1, with X3 exogenous, so the exogenous variables of the full system are X1, X2, and X3. Using as instruments quadratic terms in the exogenous variables, the model is specified to PROC MODEL as follows:
proc model;
parms a b c d e f;
y1 = a + b * exp( c * x1 ) + d * log( x2 ) + e * exp( f * y2 );
instruments inst1-inst9;
inst1 = x1; inst2 = x2; inst3 = x3;
inst4 = x1 * x1; inst5 = x1 * x2; inst6 = x1 * x3;
inst7 = x2 * x2; inst8 = x2 * x3; inst9 = x3 * x3;
fit y1 / 2sls;
run;
It is not clear what degree polynomial should be used. There is no way to know how good the approximation is for any degree chosen, although the first-stage 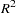 s might help the assessment.
s might help the assessment.
First-Stage R-Squares
When the FSRSQ option is used on the FIT statement, the MODEL procedure prints a column of first-stage (FSRSQ) statistics along with the parameter estimates. The FSRSQ measures the fraction of the variation of the derivative column associated with the parameter that remains after projection through the instruments.
Ideally, the FSRSQ should be very close to 1.00 for exogenous derivatives. If the FSRSQ is small for an endogenous derivative, it is unclear whether this reflects a poor choice of instruments or a large influence of the errors in the endogenous right-hand-side variables. When the FSRSQ for one or more parameters is small, the standard errors of the parameter estimates are likely to be large.
Note that you can make all the FSRSQs larger (or 1.00) by including more instruments, because of the disadvantage discussed previously. The FSRSQ statistics reported are unadjusted s and do not include a degrees-of-freedom correction.
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.