Creating a Hadoop Container Job
Solution
You can create a SAS
Data Integration Studio job that contains the Hadoop Container transformation.
This transformation enables you to run a series of Hadoop steps such
as transfers to and from Hadoop, Map Reduce processing, and Pig Latin
processing without adding the dedicated transformations for those
tasks to the job.
For example, you can
create a sample job that performs the following tasks that are run
through the Hadoop Container transformation:
Tasks
Create a Hadoop Container Job
You can create a Hadoop
Container job similar to the sample job, which contains four Hadoop
steps that correspond to four rows of tables and transformations.
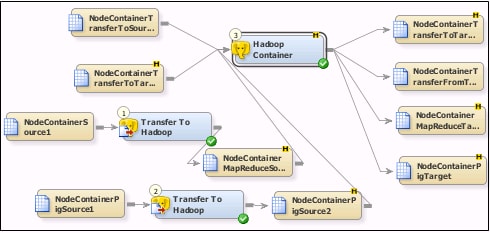
The two rows at the
top of the tab are used for the Transfer To and Transfer From steps.
Note that the first row contains a text source table and Hadoop target
table, where the second row contains a Hadoop source table and a text
target table. The two rows at the bottom of the tab are used for the
Map Reduce and Pig steps. Note that each row begins with a text source
and a Transfer To Hadoop transformation that creates the Hadoop source
table for the Hadoop Container transformation. Both rows feed steps
that send output to Hadoop target tables.
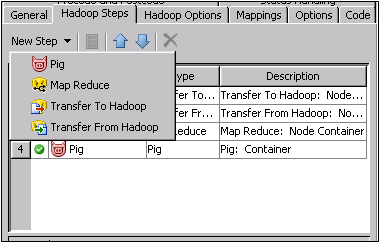
Add and Review Hadoop Steps
The steps processed
in the Hadoop Container transformation are listed in a table on the Hadoop
Steps tab. You can add, edit, reorder, and delete steps
by clicking the buttons in the toolbar at the top of the tab.
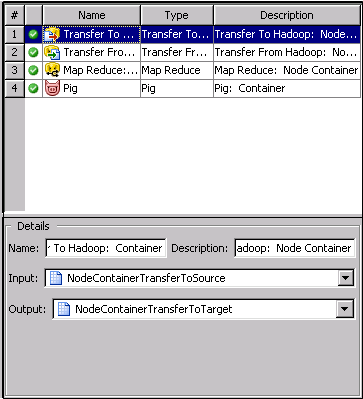
You can click a row
in the table to review its name, description, input, and output in
the Details panel at the bottom of the tab. If a step has multiple
inputs or outputs, you can use the drop-down arrow to select the object
that you need.
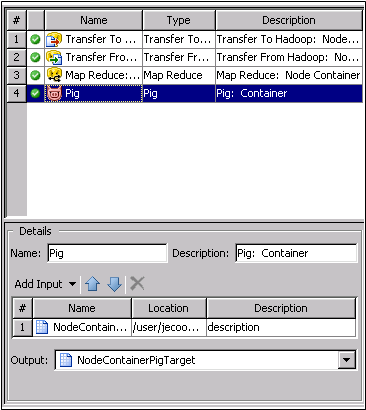
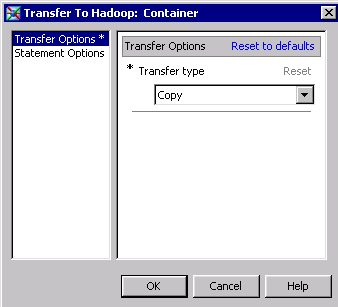
Configure a Map Reduce Step

The window contains
an additional Map Reduce JAR. Install only Hadoop JAR files required
by SAS on your SAS machine. Note that the SAS Hadoop implementation
does not include the Hadoop JAR files that are open-source files.
You must copy the required Hadoop JAR files to be copied from your
Hadoop server onto your SAS machine where the workspace server resides.
The window also includes
required arguments for the mapper and optional arguments for the reducer
and combiner.
The Map Reduce Options section
of the Advanced Options window also contains
several other options that are not set in the sample job.
Finally, the Map Reduce
step in the sample job includes the following advanced options (accessed
by clicking Advanced Options):
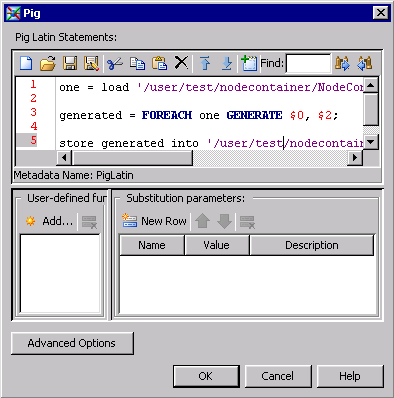
Configure a Pig Step
Configure the Hadoop Options Tab
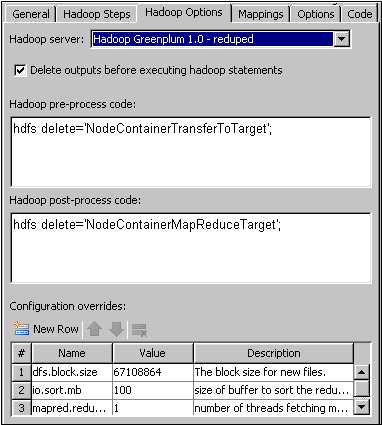
The Hadoop
Options tab enables you to set options such as server
selection, output deletion, pre- and post-process code, and configuration
overrides for all of the steps. Note that the pre- and post-process
code on this tab is run against the Hadoop server only. This code
is not the standard pre- and post-process code that is run on the
SAS workspace server. Therefore, SAS code is not appropriate input
for these fields.