Copy Data to Hadoop

Prerequisites
When you open the Copy
Data to Hadoop directive, the Source Tables task
shows the data sources that are currently defined in SAS Data Loader.
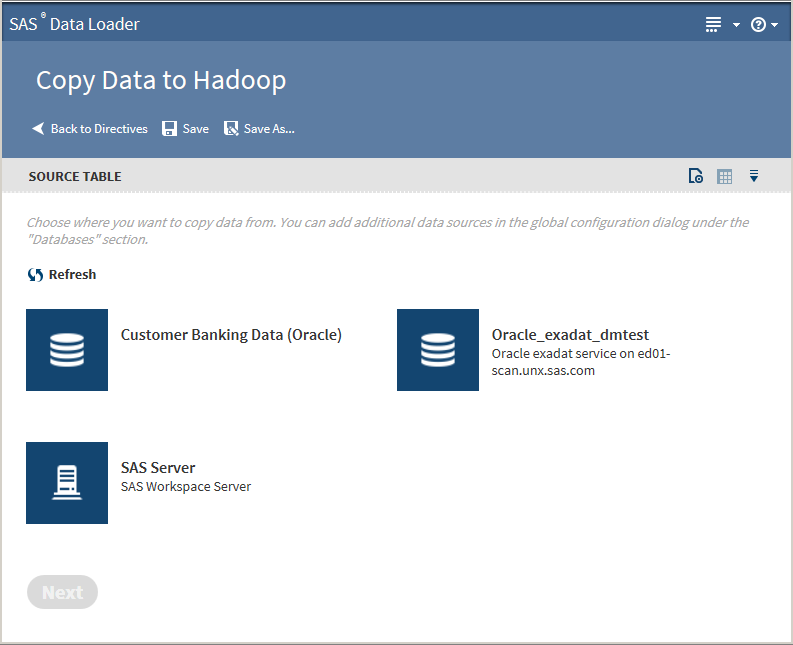
If you do not see the database from which you want to copy, you must
add a connection to that database. See Databases Panel for more information.
Example
Follow these steps to
copy data into Hadoop from a database:
-
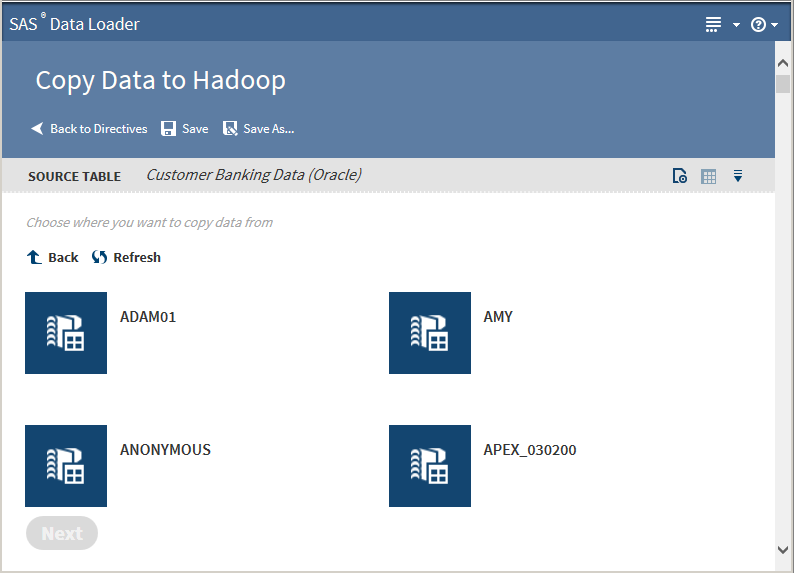
On the SAS Data Loader directives page, click the Copy Data to Hadoop directive. The Source Table task that lists available databases is displayed:Note that the SAS Server data source points to the following location on the vApp host:
vApp-shared-folder/SASData/SAS Data Location. To copy SAS data to Hadoop, all source tables must first be copied to this location.Note: When you select the SAS Server folder, filenames are not translated. For locales other than English, this means that files that exist in the SAS Server folder are not displayed for selection. To work around this issue, you can import entire SAS files. In the Source Table task, select a file outside of the SAS Server folder and click through the directive. Select or create a target table. In the Code task, open the Code Editor to change the source file information, and then run the job. -
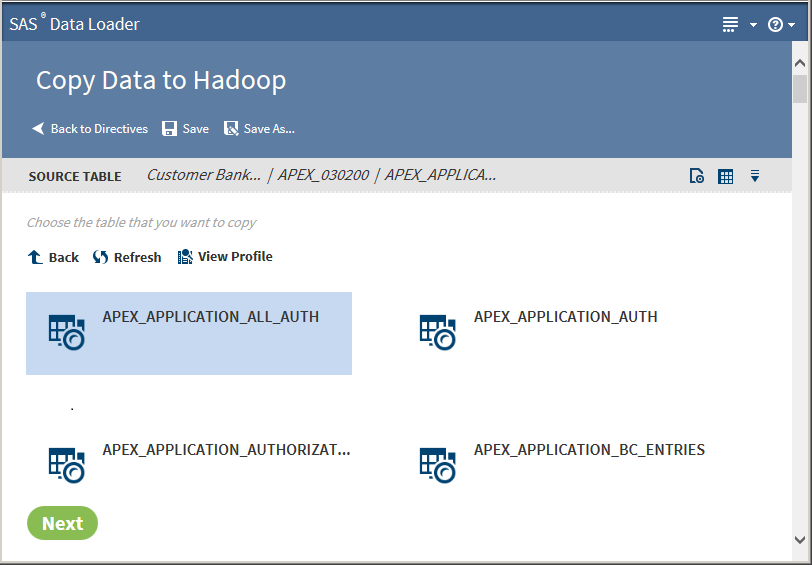
TipIf a profile already exists for a table, PROFILED appears beneath the table name. You can view the existing profile by selecting the table and clicking View Profile.Clicking the Action menu
 enables the following actions:
Openopens the current directive.Table Viewerenables you to view sample data from a table. Select the table, and then click
enables the following actions:
Openopens the current directive.Table Viewerenables you to view sample data from a table. Select the table, and then click to display SAS Table Viewer.
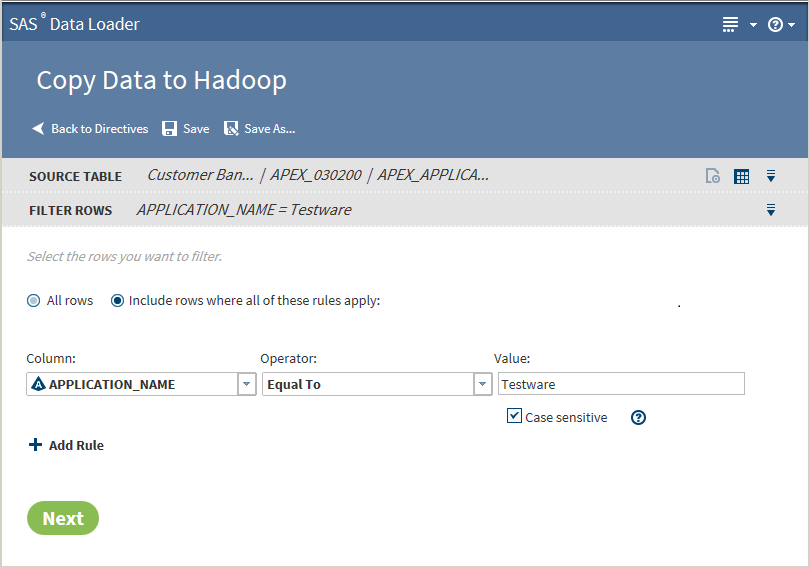
Advanced Optionsopens a dialog box that enables you to modify the advanced options. The advanced options enable additional character variable length to accommodate converted non-UTF8 encoding.TipIt is recommended that you use UTF8 encoding in SAS data when copying data from SAS to Hadoop. The vApp always uses UTF8 encoding. If you copy a non-UTF8 encoded data set from elsewhere, then the Hadoop target table is not able to accommodate all the characters. This limitation is due to the increased number of bytes when the data is converted to UTF8 encoding.Note: Modify only one of the following two advanced options. If you fill in both fields, then the value in the multiplier field is ignored.Number of bytes to add to length of character variables (0 to 32766)Enter an integer value from 0 to 32766.Multiplier to expand the length of character variables (1 to 5)Enter an integer value from 1 to 5.Click Next. The Filter Rows task is displayed:
to display SAS Table Viewer.
Advanced Optionsopens a dialog box that enables you to modify the advanced options. The advanced options enable additional character variable length to accommodate converted non-UTF8 encoding.TipIt is recommended that you use UTF8 encoding in SAS data when copying data from SAS to Hadoop. The vApp always uses UTF8 encoding. If you copy a non-UTF8 encoded data set from elsewhere, then the Hadoop target table is not able to accommodate all the characters. This limitation is due to the increased number of bytes when the data is converted to UTF8 encoding.Note: Modify only one of the following two advanced options. If you fill in both fields, then the value in the multiplier field is ignored.Number of bytes to add to length of character variables (0 to 32766)Enter an integer value from 0 to 32766.Multiplier to expand the length of character variables (1 to 5)Enter an integer value from 1 to 5.Click Next. The Filter Rows task is displayed: -
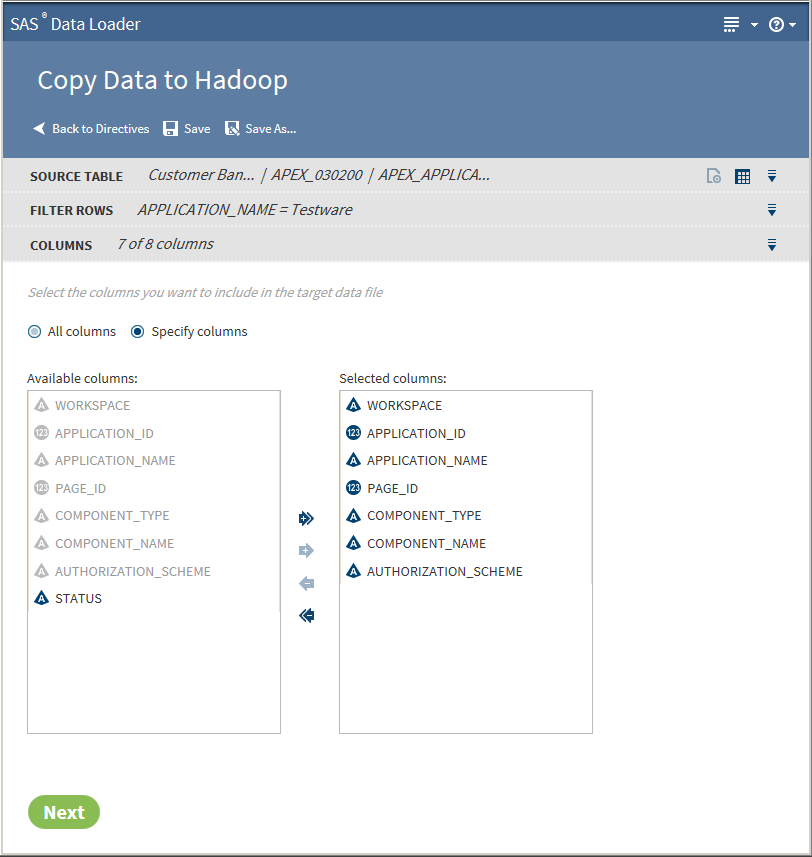
The Columns task enables you to choose the columns to be copied. You can select All columns or Specify columns.The columns in the Selected columns pane are copied to Hadoop. Select an individual column name and click
 or
or  to move the column name between the Available
columns pane and the Selected columns pane until the
correct list of names appears in the Selected columns pane.
Click
to move the column name between the Available
columns pane and the Selected columns pane until the
correct list of names appears in the Selected columns pane.
Click  or
or  to move all column names at once.
When the column selection is complete, click Next. The Options task is displayed:
to move all column names at once.
When the column selection is complete, click Next. The Options task is displayed: -
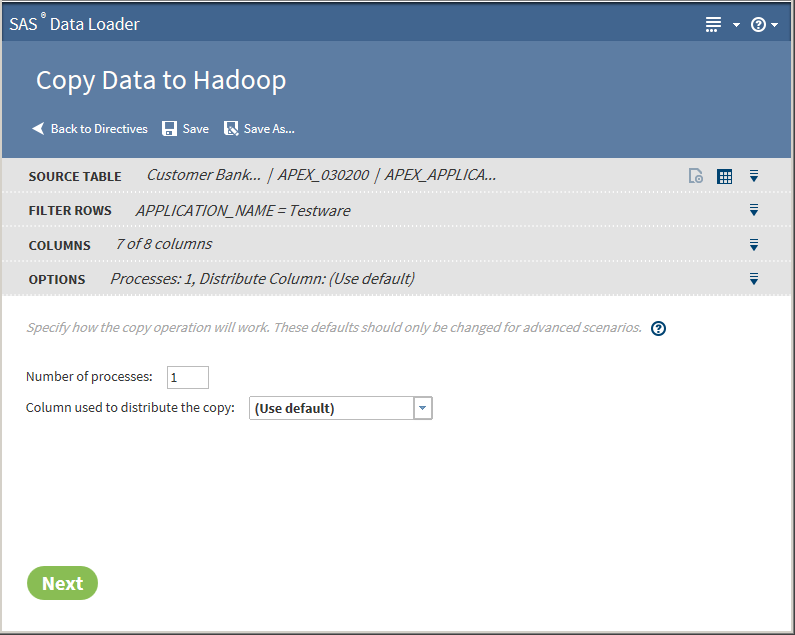
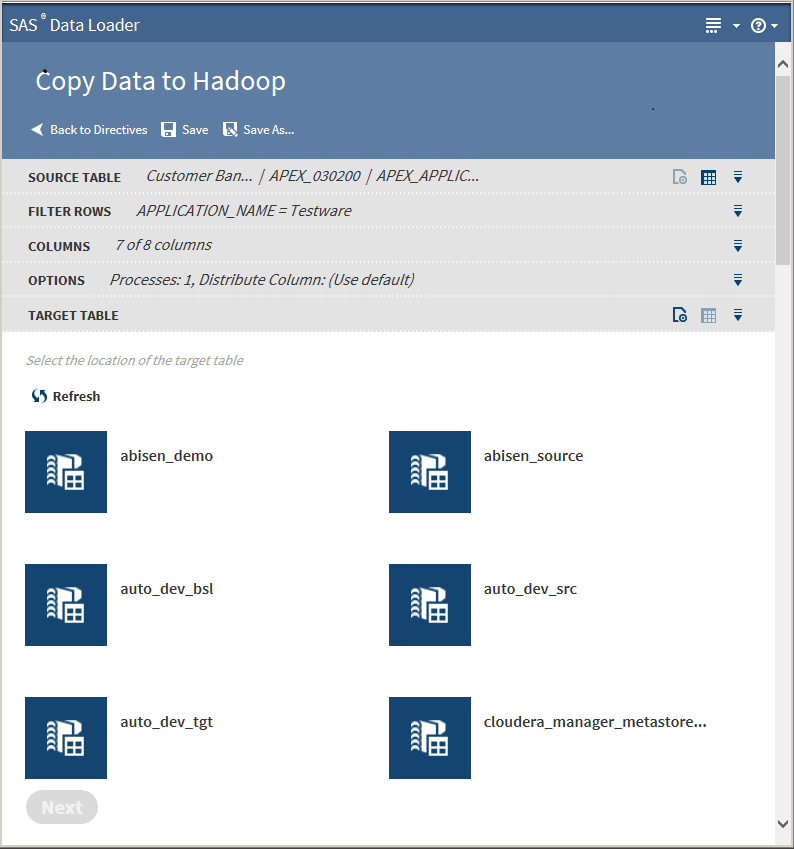
The values in the Options task should not be changed unless you have advanced knowledge of database operations.CAUTION:If you change the number of processes, you are required to select a distribution column.Changing the number of processes to greater than one expands the number of processes and source data connections that are used to import data. When running in this mode, a column must be identified in order to distribute the data across the parallel processes. This column is typically the primary key or index of the table in the data source. Only single columns are allowed. Numeric integer values that are evenly distributed in the data are recommendedClick Next. The Target Table task is displayed with data sources:
-
Tip
-
You can create a new table by clicking New Table.
-
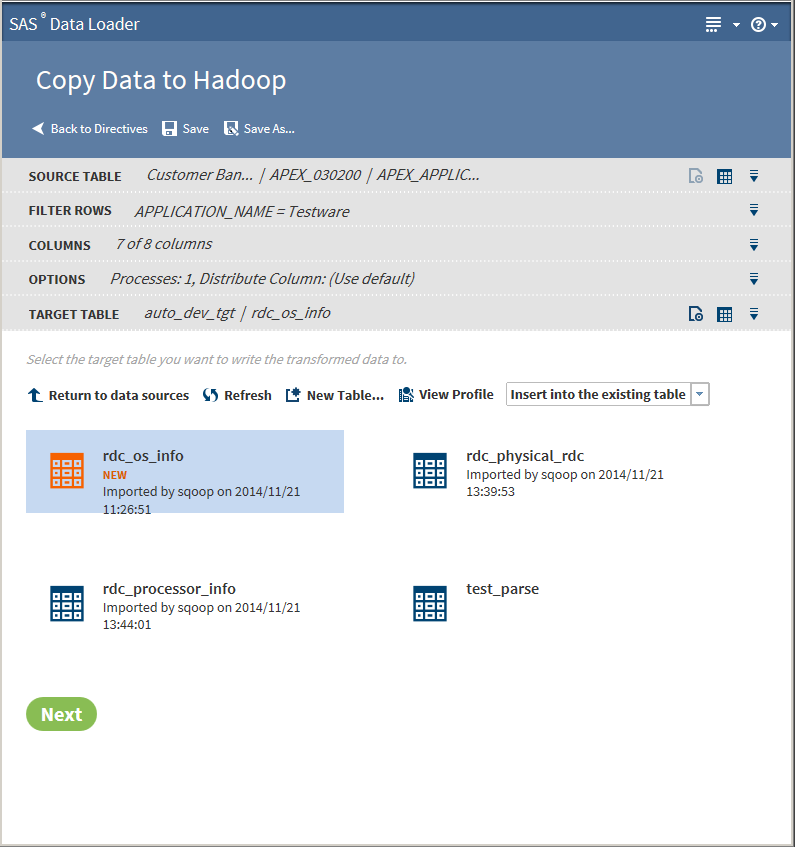
If a profile already exists for a table, PROFILED appears next the table icon. You can view the existing profile by selecting the table and clicking View Profile.
Clicking the Action menu enables the following actions:
Openopens the current directive.Table Viewerenables you to view sample data from a table. Select the table, and then click to display SAS Table Viewer.
Advanced Optionsopens a dialog box that enables you to modify the following advanced options:Output table formatUse the drop-down list to select one of five output table formats: Hive default, Text, Parquet, ORC, or Sequence. The Parquet format is not support for MapR distributions of Hadoop.DelimiterUse the drop-down list to select one of five output table formats: Hive default, Comma, Tab, Space, or Other.Click Next. The Code task is displayed: -
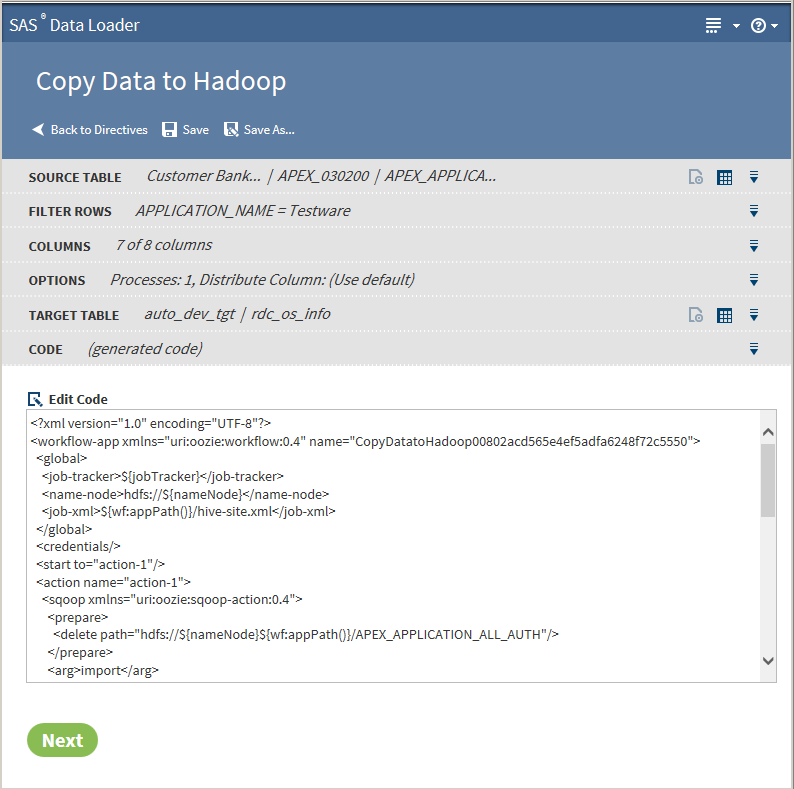
-
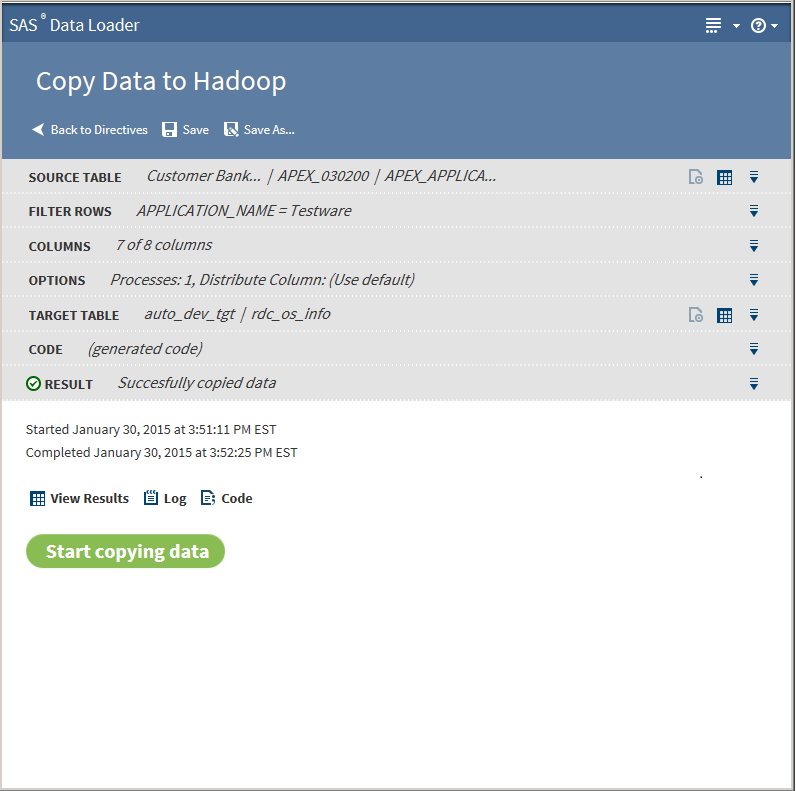
The following actions are available:View Resultsenables you to view the results of the copy process in SAS Table Viewer.Logdisplays the SAS log that is generated during the copy process.Codedisplays the SAS code that copies the data.
Usage Notes
-
If LDAP is used to protect your Hadoop cluster, you cannot use the Copy Data To Hadoop directive to copy data from a DBMS. For more information, see Active Directory (LDAP) Authentication.
-
If necessary, you can change the maximum length of character columns for input tables to this directive. For more information, see Change the Maximum Length for SAS Character Columns.
-
Error messages and log files that are produced by the Copy Data to Hadoop directive include the URL of the Oozie log file. Oozie is a job scheduling application that is used to execute Copy Data to Hadoop jobs. Refer to the Oozie log for additional troubleshooting information.
-
When copying data from Teradata:
-
In Cloudera 5.2 or later, the Teradata source table must have a primary key that is defined, or you must specify a distribution column on the Options task.
-
In Hortonworks 2.1 or later, you are required to insert Teradata data into existing tables. The creation or replacement of tables is not supported. This is due to a limitation in the HortonWorks Sqoop connector. One workaround is to ask your Hadoop administrator to drop an existing table, and then create an empty table with the desired schema. At that point, you can use the Append option in the Copy Data to Hadoop directive to copy a Teradata table into the empty table. For more information, see Step 9 in the Example section.
-
-
When copying data from SQL Server, note that SQL Server does not support the SQL standard syntax for specifying a Date literal, which is as follows:
DATE ‘date_literal’. Edit the generated code and remove the word DATE that appears prior to the quoted date literal. For example, you would change( table0.BEGDATE >= DATE '1990-01-01' )to( table0.BEGDATE >= '1990-01-01' ). For more information about the Code task, see Step 10 in the Example section. -
When copying data from Oracle, note that Oracle table names must be uppercase.
Copyright © SAS Institute Inc. All rights reserved.