Troubleshooting
Active Directory (LDAP) Authentication
If Active Directory
and LDAP (Lightweight Directory Access Protocol) are used to protect
your Hadoop cluster, an LDAP user and password must be specified in
the Hadoop connection for SAS Data Loader. For more information
about the Hadoop connection, see Hadoop Configuration Panel.
Oozie does not support
LDAP authentication. SAS Data Loader uses the SQOOP and Oozie components
installed with the Hadoop cluster to move data to and from a DBMS.
Accordingly, when LDAP authentication is used with your Hadoop cluster,
directives that rely on Oozie, such as Copy Data To Hadoop, do not
receive the authentication benefits provided by LDAP. However, the
operation of these directives is otherwise unaffected.
Change the File Format of Hadoop Target Tables
In Hadoop file system
(HDFS), tables are stored as one or more files. Each file is formatted
according to the Output Table Format option, which is specified in
each file. In SAS Data Loader, when you create a new target table
in Hadoop, the Output Table Format option is set by the value of the Output
table format field.
You can change the default
value of the Output table format field in
the SAS Data Loader Configuration window.
In any given directive, you can override the default value using the Action menu
icon in the Target Table task.
The default format is
applied to all new target tables that are created with SAS Data Loader.
To override the default format in a new table or an existing table,
you select a different format in the directive and run the job.
To change the default
value of the Output table format field, go
to the SAS Data Loader directives page, click the More icon  , and select Configuration.
In the Configuration window, click General
Preferences. In the General Preferences panel, change
the value of Output table format.
, and select Configuration.
In the Configuration window, click General
Preferences. In the General Preferences panel, change
the value of Output table format.
, and select Configuration.
In the Configuration window, click General
Preferences. In the General Preferences panel, change
the value of Output table format.
To override the default
value of the Output table format field for
a given target in a given directive, open the directive and proceed
to the Target Table task. Select a target
table, and then click the Action menu  for that target table. Select Advanced
Options, and then, in the Advanced Options window,
set the value of Output table format. The
format that you select applies only to the selected target table.
The default table format is not changed. The default format continues
to be applied to all new target tables.
for that target table. Select Advanced
Options, and then, in the Advanced Options window,
set the value of Output table format. The
format that you select applies only to the selected target table.
The default table format is not changed. The default format continues
to be applied to all new target tables.
for that target table. Select Advanced
Options, and then, in the Advanced Options window,
set the value of Output table format. The
format that you select applies only to the selected target table.
The default table format is not changed. The default format continues
to be applied to all new target tables.
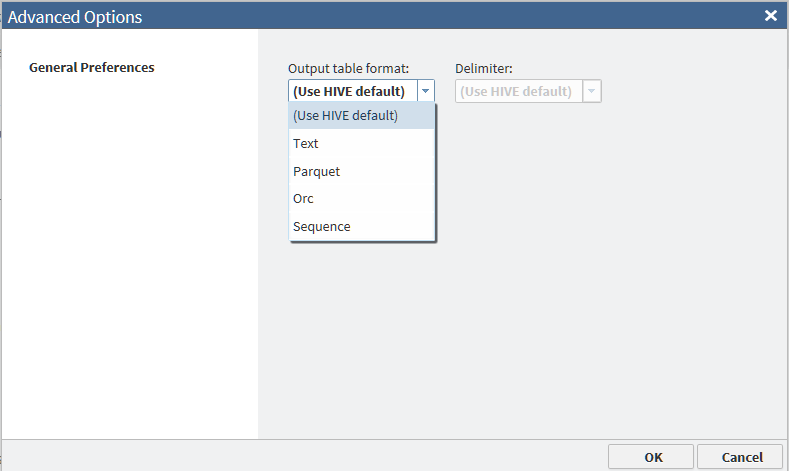
The available values
of the Output table format field are defined
as follows:
Use HIVE default
specifies that the
new target table receives the Output Table Format option value that
is specified in HDFS. This is the default value for the Output
table format field in SAS Data Loader.
Text
specifies that the
new target table is formatted as a series of text fields that are
separated by delimiters. For this option, you select a value for the Delimiter field.
The default value of the Delimiter field
is (Use HIVE default). You can also select
the value Comma, Space, Tab,
or Other. If you select Other,
then you enter a delimiter value. To see a list of valid delimiter
values, click the question mark icon to the right of the Delimiter field.
Parquet
specifies the Parquet
format, which is optimized for nested data. The Parquet algorithm
is considered to be more efficient than using flattened nested namespaces.
Note: If your cluster uses a MapR
distribution of Hadoop, then the Parquet output table format is not
supported.
ORC
specifies the Optimized
Row Columnar format, which is a columnar format that efficiently manages
large amounts of data in Hive and HDFS.
Sequence
specifies the SequenceFile
output format, which enables Hive to efficiently run MapReduce. This
format enables Hive to efficiently split large tables into separate
threads.
Consult your Hadoop
administrator for advice about output file formats. Testing might
be required to establish the format that has the highest efficiency
on your Hadoop cluster.
Change the Maximum Length for SAS Character Columns
Some directives use
a SAS Workspace Server to read or write tables. By default, the character
columns for the input tables to such directives are expanded to 1024
characters in length. The valid range for the maximum length option
is 1–32,767 characters. The default length should perform well
in most cases, though there might be situations where a larger value
is required. For example, if you have cells in your columns with data
larger than 1024 characters, SAS directives that use DS2 truncates
the data. In such situations, you should increase the maximum length.
Note: You should not change this
value unless you need to because of your data requirements. As you
increase the maximum length for SAS character columns, you also increase
the likelihood that performance will be affected.
The affected directives
are as follows:
-
Transform Data in Hadoop
-
Transpose Data in Hadoop
-
Load Data to LASR
-
Copy Data to Hadoop (when a data set from the SAS Server is selected as the input table)
-
Copy Data from Hadoop (when the SAS Server is selected as the location for the target table)
If you want to change
the default maximum length for SAS character columns for all directives,
go to the SAS Data Loader directives page, click the Action menu  , and select Configuration.
In the Configuration window, select General
Preferences, and specify the desired length for SAS character
columns.
, and select Configuration.
In the Configuration window, select General
Preferences, and specify the desired length for SAS character
columns.
, and select Configuration.
In the Configuration window, select General
Preferences, and specify the desired length for SAS character
columns.
You can override the
default maximum length for SAS character columns in a given directive
without changing the default. In one of the directives listed above,
open the Source Table task, click the Action menu,
and select Advanced Options . In the Advanced
Options window, specify the desired length for SAS character
columns. The value that you specify applies only to the current instance
of the current directive.
Change the Temporary Storage Location
If the default temporary
storage directory for SAS Data Loader is not appropriate for some
reason, you can change that directory. For example, some SAS Data
Loader directives might fail to run if they cannot write to the temporary
directory. If that happens, ask your Hadoop administrator if the sticky
bit has been set on the default temporary directory (typically
/tmp).
If that is the case, specify an alternate location for temporary storage.
For more information, see the description of the SAS HDFS
temporary storage location field in the topic Hadoop Configuration Panel.Discover New Columns Added to a Source after Job Execution
When
you add columns to a source table, any directives that need to use
the new columns need to discover them. To make the new columns visible
in a directive, open the Source Table task,
click the source table again, and click Next.
The new columns are then available for use in the body of the directive,
in a transformation or query, for example.
Hive Limit of 127 Expressions per Table
Due to a limitation in the Hive database, tables can
contain a maximum of 127 expressions. When the 128th expression is
read, the directive fails and the SAS log receives a message similar
to the following:
ERROR: java.sql.SQLException: Error while processing statement: FAILED:
Execution Error, return
code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
ERROR: Unable to execute Hadoop query.
ERROR: Execute error.
SQL_IP_TRACE: None of the SQL was directly passed to the DBMS.The Hive limitation
applies anytime a table is read as part of a directive. For SAS Data
Loader, the error can occur in aggregations, profiles, when viewing
results, and when viewing sample data.
Overriding the Hive Storage Location for Target Tables
When you work with directives
that create target tables, those tables are stored in a directory
location in the Hadoop file system. The default location is defined
in the configuration settings for SAS Data Loader, as described in Hadoop Configuration Panel.
If you prefer, you can
override the storage location for a target table for an individual
job.
To override the storage
location for a target table:


Unsupported Hive Data Types and Values
The Hive
database in Hadoop identifies table columns by name and data type.
To access a column of data, SAS Data Loader
first converts the Hadoop column name and data type into its SAS equivalent.
When the transformation is complete, SAS Data Loader
writes the data into the target table using the original Hadoop column
name and data type.
If your target data
is incorrectly formatted, then you might have encountered a data type
conversion error.
The Hive database in
Hadoop supports a Boolean data type. SAS does not support the Boolean
data type in Hive at this time. Boolean columns in source tables are
not available for selection in SAS Data Loader.
The BIGINT data type in Hive supports
integer values larger than those that are currently supported in SAS.
BIGINT values that exceed +/–9,223,372,036,854,775,807 generate
a stack overflow error in SAS.
Restarting a Session after Time-out
SAS Data Loader
records periods of inactivity in the user interface. After a period
of continuous inactivity, the current web page receives a session
time-out warning message in a window. If you do not provide input
within three minutes after you receive the warning, the current web
page is replaced by the Session Time-out page.
You can restart your session by clicking the text Return
to the SAS Data Loader
application.
When a session terminates,
any directives that you did not save or run are lost.
To open an unsaved directive
that you ran before your session terminated, follow these steps:

Copyright © SAS Institute Inc. All rights reserved.