Import a File
Introduction

Use the Import a File
directive to copy a delimited source file into a target table in HDFS
and register the target in Hive.
As you use the directive,
it samples the source data and generates default column definitions
for the target. You can then edit the column names, types, and lengths.
To simplify future imports,
the Import a File directive enables you to save column definitions
to a file and import column definitions from a file. After you import
column definitions, you can then edit those definitions and update
the column definitions file.
The directive can be
configured to create delimited Text-format targets in Hadoop using
an efficient bulk-copy operation.
In the source file,
the delimiter must consist of a single character or symbol. The delimiter
must have an ASCII character code in the range of 0 to 255.
To learn more about
delimiters and column definitions files, refer to the following example.
To copy database tables
into Hadoop using a database-specific JDBC driver, use the Copy Data to Hadoop directive.
Example
Follow these steps to
use the Import a File directive:
-
In the File Specification task, click
 . You will see the delimiter that separates the variable
values. Check to see whether the delimiter is used as part of a variable
value.
Notes:
. You will see the delimiter that separates the variable
values. Check to see whether the delimiter is used as part of a variable
value.
Notes:-
In the source file, all variable values that contain the delimiter character must be enclosed in quotation marks (
"). -
In Hadoop distributions that run Hive 13 or earlier, a backslash character ( \ ) is introduced into the target when the delimiter appears in source values. For example, the source data
One, "Two, Three", Fourwould be represented in the target as Column A:One, Column B:Two\, Three, and Column C:Four. In Hive 14 and later, the backslash character is not introduced into the target.
-
-
Click Input format delimiter to display a list of available delimiters. Click the delimiter that you see in your source file, or click Other. If you clicked Other, then enter into the text field the single-character delimiter or the octal delimiter that you see in the source file. Octal delimiters use the format \nnn, where n is a digit from 0 to 9. The default delimiter in Hive is \001.Note: Input delimiters must have ASCII character codes that range from 0 to 255, or octal values that range from \000 to \177.
-
To efficiently register and store the source data in Hadoop using a bulk-copy, select Use the input delimiter as the delimiter for the target table. The bulk-copy operation is efficient, but the source data is not analyzed or validated in any way. For example, the directive does not ensure that each row has the expected number of columns.Note:
-
The bulk-copy operation is used only if the next two options are not selected. If this condition is met, then the source file is bulk-copied to the target. The format of the target is Text. The Text format is used regardless of another format that might be specified in the Target Table task.
-
If your source file uses
\Nto represent null values, you can preserve those null values in the target. A bulk-copy operation is required. In Hive, the default null value is\N.
CAUTION:Bulk-copies include newline characters in the target without generating error messages or log entries. Newline characters in the target can cause data selection errors.Remove newline characters from the source as needed to create a usable target in Hadoop. -
-
If the source file is formatted accordingly, select Check the input file for records wrapped in quotation marks ("). Quotation marks are required when the delimiter appears within a variable value.Quotation marks that appear inside a quoted value need to be represented as two quotation marks ("").CAUTION:Except for bulk-copy operations, jobs fail if the source contains newline characters.For all jobs other than bulk-copies, ensure that the source file does not contain newline characters.In all cases, newline characters within source values will cause the import job to fail.
-
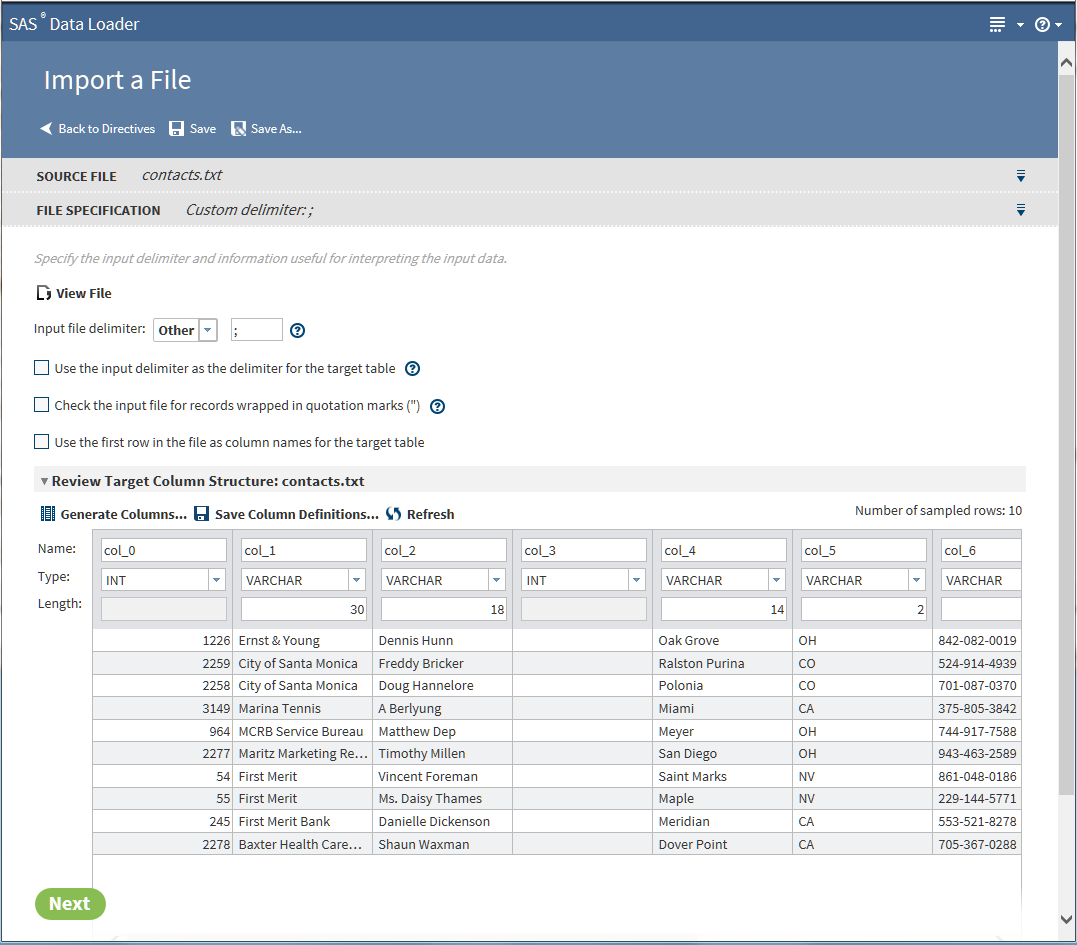
Click Review Target Column Structure to display a sample of the target table. The target is displayed with default column names (unless they were specified in the source), types, and lengths (as available according to the type). Review and update the default column definitions as needed, or apply a column definitions file as described in subsequent steps.TipTo display a larger data sample, click
 . In the Generate Columns window,
enter a new value for Number of rows to sample.
CAUTION:Time and datetime values in the source must be formatted in one of two ways in order for those columns to be assigned the correct type in the target.To accurately assign a column type, the directive requires that the source file use a DATE column format of
. In the Generate Columns window,
enter a new value for Number of rows to sample.
CAUTION:Time and datetime values in the source must be formatted in one of two ways in order for those columns to be assigned the correct type in the target.To accurately assign a column type, the directive requires that the source file use a DATE column format ofYYYY-MM-DDand a DATETIME column format ofYYYY-MM-DD HH:MM:SS.fffffffff. The DATETIME format requires either zero or nine decimal places after the seconds valueSS. Source columns that do not meet these requirements are assigned the VARCHAR type. In the directive, the VARCHAR cannot be changed to a relevant Hadoop type such as DATE or TIMESTAMP. -
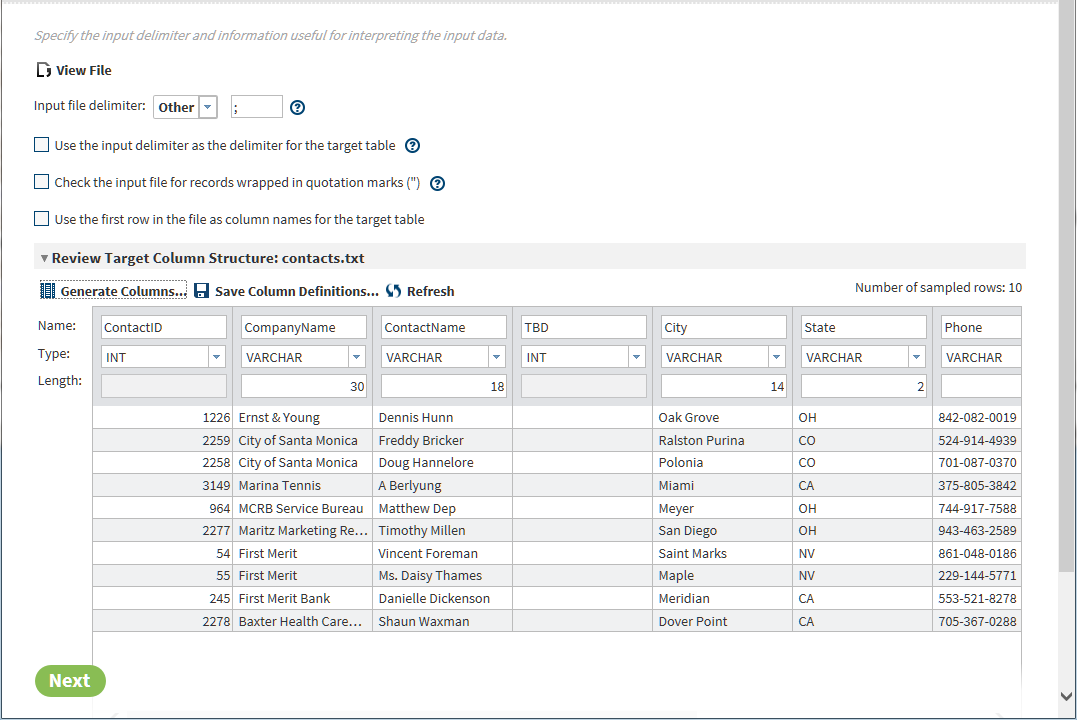
When your columns are correctly formatted, you can save your column definitions to a file. You can then reuse that file to import column definitions the next time you import this or another similar source file. To generate and save a column definitions file, click
 . In the Save Column Definitions window,
enter a filename to generate a new file, or select an existing file
to overwrite the previous contents of that file. Click OK to
save your column definitions to the designated file.
. In the Save Column Definitions window,
enter a filename to generate a new file, or select an existing file
to overwrite the previous contents of that file. Click OK to
save your column definitions to the designated file.
-
If you previously saved a column definitions file, and if you want to import those column definitions to quickly update the defaults, then follow these steps:
-
In the Generate Columns window, click Generate to close the window and format the target columns as specified in the column definitions file.TipAs is the case with the default column definitions, you can enter changes to imported column names, types, and lengths. You can then save your changes to the original column definitions file or to a new file.TipDuring the definition of columns, you can replace your changes with the default column definitions at any time. Select, click Guess the columns based on a sample
of data , and click Generate.
-
The format of the target table is specified by default for all directives in the Configuration window. To see the default target format, click the More icon
 , and then select Configuration.
In the Configuration window, click General
Preferences.
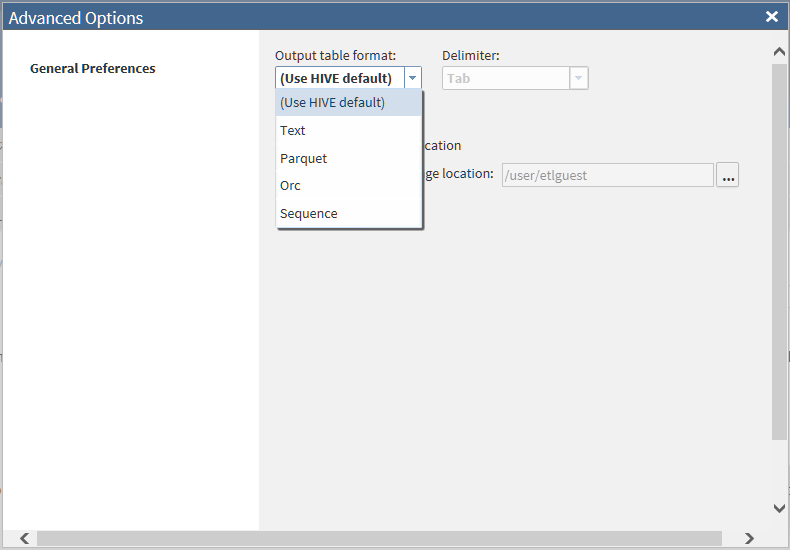
To override the default target file format for this one target, click the target and select Advanced Options
, and then select Configuration.
In the Configuration window, click General
Preferences.
To override the default target file format for this one target, click the target and select Advanced Options .
Note: If you are using a bulk-copy operation, as described in Step 6, then the target always receives the Text format, regardless of the selections in the Advanced Options and Configuration windows.To browse a non-default Hive storage location, click Specify alternate storage location, and then click
.
Note: If you are using a bulk-copy operation, as described in Step 6, then the target always receives the Text format, regardless of the selections in the Advanced Options and Configuration windows.To browse a non-default Hive storage location, click Specify alternate storage location, and then click . You need appropriate permission to store your imported
table or file to a non-default Hive storage location.
When your target selection is complete, click Next.
. You need appropriate permission to store your imported
table or file to a non-default Hive storage location.
When your target selection is complete, click Next.

Copyright © SAS Institute Inc. All rights reserved.