Scalable Performance Data Server and Scalable Performance Data Engine
Overview of Scalable Performance Data Server and Scalable Performance Data Engine
Both the SAS Scalable
Performance Data Engine (SPD Engine) and the SAS Scalable Performance
Data Server (SPD Server) are designed for high-performance data delivery.
They enable rapid access to SAS data for intensive processing by the
application. The SAS SPD Engine and SAS SPD Server deliver data to
applications rapidly by organizing the data into a streamlined file
format that takes advantage of multiple CPUs and I/O channels to perform
parallel input and output functions.
The SAS SPD Engine is
included with Base SAS software. It is a single-user data storage
solution that shares the high-performance parallel processing and
parallel I/O capabilities of SAS SPD Server, but it lacks the additional
complexity of a full-blown server. It is a multi-user parallel-processing
data server with a comprehensive security infrastructure, backup and
restore utilities, and sophisticated administrative and tuning options.
SAS SPD Server libraries can be defined using SAS Management Console.
SAS SPD Engine and SAS
SPD Server use multiple threads to read blocks of data very rapidly
and in parallel. The software tasks are performed in conjunction with
an operating system that enables threads to execute on any of the
machine's available CPUs.
Although threaded I/O
is an important part of both product offerings' functionality, their
real power comes from how the software structures SAS data.
They can read and write partitioned files and, in addition, use a
specialized file format. This data structure permits threads, running
in parallel, to perform I/O tasks efficiently.
Although not intended
to replace the default Base SAS engine for most tables that do not
span volumes, SAS SPD Engine and SAS SPD Server are high-speed alternatives
for processing very large tables. They read and write tables that
contain billions of observations.
Symmetric Multiprocessing
The SAS SPD Server exploits
a hardware and software architecture known as symmetric multiprocessing
(SMP). An SMP machine has multiple CPUs and an operating system that
supports threads. An SMP machine is usually configured with multiple
disk I/O controllers and multiple disk drives per controller. When
the SAS SPD Server reads a data file, it launches one or more threads
for each CPU; these threads then read data in parallel. By using
these threads, a SAS SPD Server that is running on an SMP machine
provides the quick data access capability that is used by SAS in an
application.
For more information about using the SAS SPD Server,
see SAS Scalable Performance Data Server: Administrator's Guide and
support.sas.com/rnd/scalability/spds.
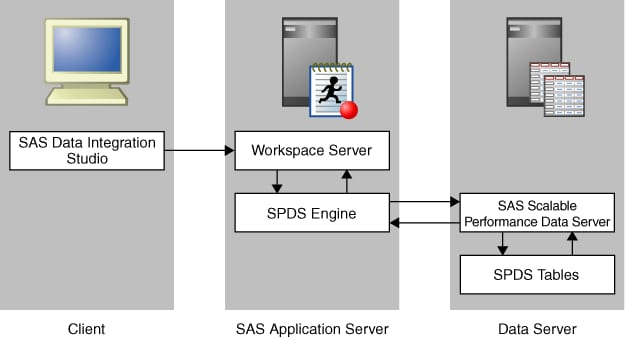
For a detailed example
of a SAS SPD Server connection, see Establishing Connectivity to a Scalable Performance Data Server.
Dynamic Clustering
The SAS SPD Server provides
a virtual table structure called a clustered data table. A cluster
contains a number of slots, each of which contains a SAS SPD Server
table. The clustered data table uses a layer of metadata to manage
the slots.
This virtual table structure
provides the SAS SPD Server with the architecture to offer flexible
storage to allow a user to organize tables based on values contained
in numeric columns, including SAS date, time, or datetime values.
This new type of organization is called a dynamic cluster table. Dynamic
cluster tables enable parallel loading and selective removal of data
from very large tables, making management of large warehouses easier.
These unique capabilities provide organizational features and performance
benefits that traditional SAS SPD Server tables cannot provide.
Dynamic
cluster tables can load and process data in parallel. Dynamic cluster
tables provide the flexibility to add new data or to remove historical
data from the table by accessing only the slots affected by the change,
without having to access the other slots, thus reducing the time needed
for the job to complete. In addition, a complete refresh of a dynamic
cluster table requires a fraction of the disk space that would otherwise
be needed, and can be divided into parallel jobs to complete more
quickly. All of these benefits can be realized using simple SPDO procedure
commands to create and alter a cluster.
The two most basic commands are CLUSTER CREATE and
CLUSTER UNDO. Two additional commands are ADD and LIST. You execute
each of these commands within PROC SPDO.
The following example
shows the syntax for PROC SPDO with a CLUSTER CREATE command:
PROC SPDO LIBRARY=domain-name; SET ACLUSER user-name; CLUSTER CREATE cluster-table-name MEM = SPD-Server-table1 MEM = SPD-Server-table2 MEM = SPD-Server-table3 MEM = SPD-Server-table4 MEM = SPD-Server-table5 MEM = SPD-Server-table6 MEM = SPD-Server-table7 MEM = SPD-Server-table8 MEM = SPD-Server-table9 MEM = SPD-Server-table10 MEM = SPD-Server-table11 MEM = SPD-Server-table12 MAXSLOT=24; QUIT;
Here is
the syntax for the UNDO command:
PROC SPDO LIBRARY=domain-name; SET ACLUSER user-name; CLUSTER UNDO sales_hist; QUIT;
This example shows the syntax
for the ADD command:
PROC SPDO LIBRARY=domain-name; SET ACLUSER user-name; CLUSTER ADD sales_hist MEM = 2005sales_table1 MEM = 2005sales_table2 MEM = 2005sales_table3 MEM = 2005sales_table4 MEM = 2005sales_table5 MEM = 2005sales_table6; QUIT;