Overview of Data Jobs
Data jobs are the main way to process data in DataFlux Data Management Studio. Each data job specifies a set of data-processing operations that flow from source to target, as illustrated in the next display.

The data flow in the previous job goes from a source node (Data Source 1), to a processing node (Concatenate 1), to an output node (Data Target (Insert) 1). Some data jobs are stored in the Data Job folder in the Folders tree, as shown in the next display. These jobs can be executed independently or can be called by another job.

Other data jobs are specified as Data Job nodes in a process job, as shown in the next display. Data Job nodes encapsulate a set of data-processing operations in a process job.
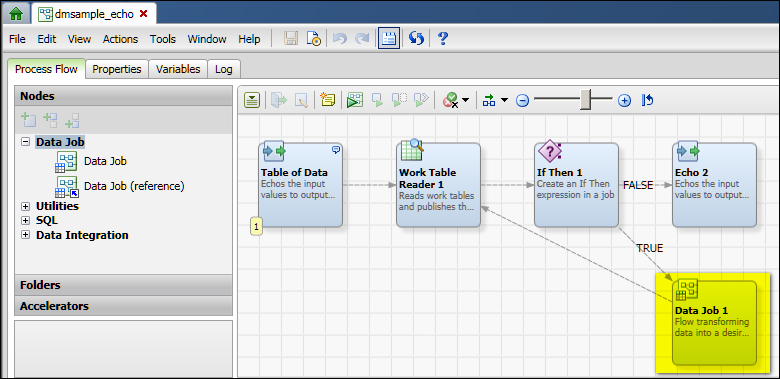
The interfaces for these two kinds of data jobs are somewhat different, but they both specify a set of data-processing operations that flow from source to target. If you want to create a data job that can be executed independently or can be called by another job, create a data job in the Folders tree, as described in Creating a Data Job in the Folders Tree. If you want to add a set of data-processing operations to a process job, add a Data Job node to the job, as summarized in Adding a Data Job Node to a Process Job.
See also the Jobs, Profiles, Data Explorations section of the FAQ.