Updating Rows in a Target Table
Overview
You can create a process job that runs an SQL query and updates specified rows in an output table. Perform the following tasks:
- Insert an Update Rows Node Into a Process Job
- Configure Row Updates
- Run the Job and Review Update Output
Insert an Update Rows Node Into a Process Job
You can insert an Update Rows node into a process job any time that you need an efficient way to update one or more selected rows into an output table. For example, you could create a job like the demonstration job shown in the following display.
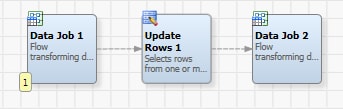
This job inserts the contents of a text file into a target table. Then, it updates a selected row in that target table before it generates the final text output file. To build this job, add the following nodes to the Process Job Editor in a process job:
- Data Job (from the Data Job category in the Nodes tree)
- Update Rows (from the SQL category in the Nodes tree)
- Data Job (from the Data Job category in the Nodes tree)
It is assumed that you are familiar with process jobs and how to create them, as explained in Creating a Process Job.
The Data Job 1 node inserts the contents of the selected text file in the target table. You can see the Text File Input node properties in the following display.
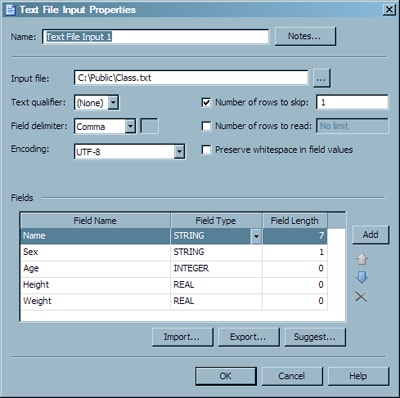
The top section of the Text File Input Properties dialog enables you to set parameters for the text file. The Fields section enables you to select and edit the fields that you want to include. You can use the properties dialog for the Data Target (Insert) node to review the output table and output fields.
Configure Row Updates
The next stage in the demonstration job selects and configures the fields that are updated. This task is performed in the Update Rows tab in the Update Rows node. You can review and edit the configuration for when you update rows, as shown in the following display.

The following tasks are performed:
- The Target Table field is reviewed to ensure that the correct target table is displayed. It should match the target table specified in the Data Job 1 node.
- The fields to update in the Field table are selected in the Set section of the tab. Then, the new values for the updated fields are specified. The sample job updates the "HEIGHT" field with "WEIGHT" and the "SEX" with "M".
- If necessary, a WHERE condition is added. The sample job contains the following condition:
"NAME" = 'Judy'
The SQL code generated by the Updated Rows tab setting is displayed in the SQL Code tab, as follows:
update "DFTEST2"."SQL_Update_Case_Insert_Values"
set
"HEIGHT" = "WEIGHT",
"SEX" = 'M'
where
"NAME" = 'Judy'
Prepare Update Output
The text file output is prepared in the Data Job 2 node. First, the updated target table is bought in as a data source, as shown in the following display.
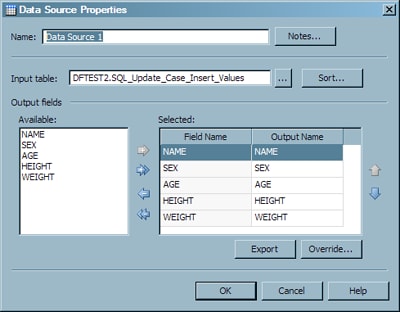
The table in the Input table field must match the target table that you have been using throughout the demonstration process job. You can also make sure that you have selected the proper output fields.
The Text File Output node enables verification that the appropriate output values are displayed. Output is displayed when the job is successfully completed if the Display file after the job runs check box is selected. The Text File Output node is shown in the following display.

The job is run and the Log tab checked to verify that the job completed successfully. The output of the job is shown in the following display.
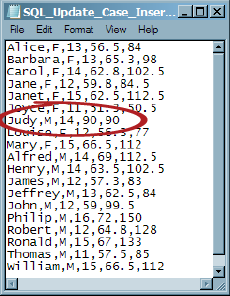
Note that the row for the field Judy is updated to display her sex as M. Also note that the weight is identical to the height. Compare these values to the original data for the field:
Judy,F,14,64.3,90
These unlikely values reflect the WHERE condition added to the Update Rows node and confirm that update was successfully performed.