
DataFlux Data Management Studio 2.6: User Guide
ODBC drivers for Apache Hive and Cloudera Impala are installed with DataFlux Data Management Studio and DataFlux Data Management Server.
Apache Hive ™ is a data warehouse infrastructure built on top of Hadoop. It supports data queries, analysis, and summarization. It provides an SQL-like language called HiveQL. For a list of the supported versions, see the rows for Apache Hive in Supported Databases for Data Storage. See also any relevant Data Connection Usage Notes.
Cloudera Impala is a query engine that runs on Apache Hadoop. Impala is optimized for queries rather than inserts into the Hadoop file system (HDFS). Accordingly, avoid using an Impala table as the output of any job node. For a list of the supported versions, see the rows for Cloudera Impala in Supported Databases for Data Storage. See also any relevant Data Connection Usage Notes.
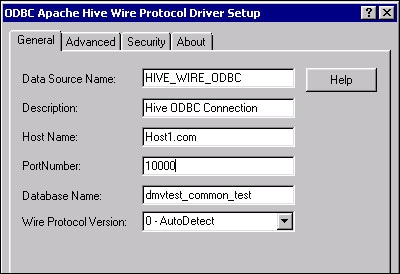
Perform these steps to add an ODBC connection for Hadoop:
See also Data Connection Usage Notes.
|
Documentation Feedback: yourturn@sas.com
|
Doc ID: dfU_T_DataConnHadoop.html |