의사결정트리 생성
도구 모음에서  아이콘을 클릭하여 의사결정트리를 생성합니다. 데이터 영역에서 Age at Death 변수를 오른쪽 영역의 반응 필드에 끌어 놓습니다. 데이터 영역에서 Diastolic, Weight, Height, Cholesterol, Age CHD Diagnosed, Sex 및 Cause of Death을 선택합니다. 이러한 항목을 모델 영역에 끌어 놓습니다. 그러면 의사결정트리가 자동으로 업데이트됩니다.
아이콘을 클릭하여 의사결정트리를 생성합니다. 데이터 영역에서 Age at Death 변수를 오른쪽 영역의 반응 필드에 끌어 놓습니다. 데이터 영역에서 Diastolic, Weight, Height, Cholesterol, Age CHD Diagnosed, Sex 및 Cause of Death을 선택합니다. 이러한 항목을 모델 영역에 끌어 놓습니다. 그러면 의사결정트리가 자동으로 업데이트됩니다.
아이콘을 클릭하여 의사결정트리를 생성합니다. 데이터 영역에서 Age at Death 변수를 오른쪽 영역의 반응 필드에 끌어 놓습니다. 데이터 영역에서 Diastolic, Weight, Height, Cholesterol, Age CHD Diagnosed, Sex 및 Cause of Death을 선택합니다. 이러한 항목을 모델 영역에 끌어 놓습니다. 그러면 의사결정트리가 자동으로 업데이트됩니다.
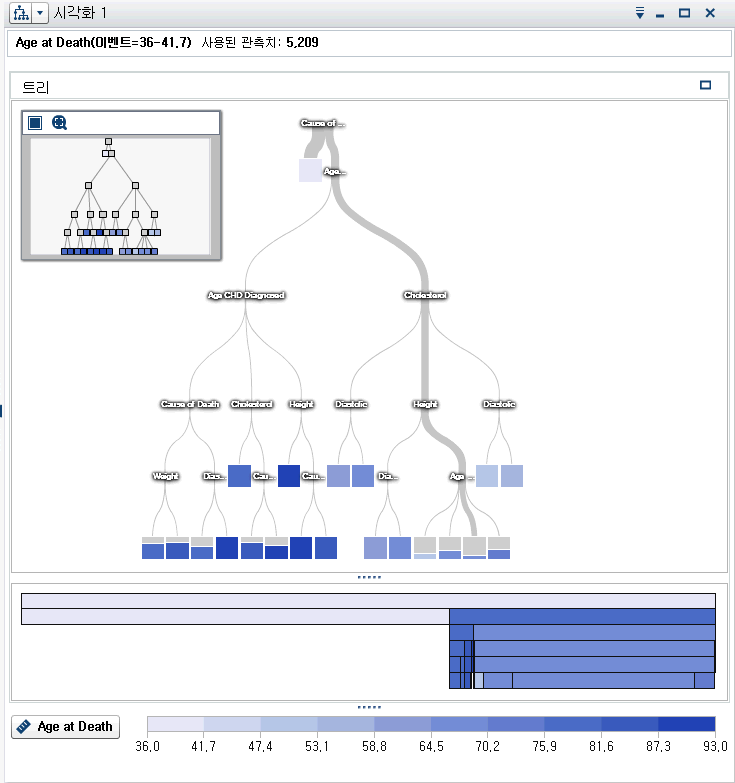
모델 영역의 오른쪽 위에 있는  아이콘을 클릭합니다. 상세 정보 테이블에서 노드 규칙 탭을 선택합니다. 여기서 Age CHD Diagnosed 및 Cause of Death만 예측변수로 사용되었다는 점에 주의해야 합니다. 의사결정트리 속성을 조정하여 모델에 더 많은 예측변수를 포함할 수 있습니다.
아이콘을 클릭합니다. 상세 정보 테이블에서 노드 규칙 탭을 선택합니다. 여기서 Age CHD Diagnosed 및 Cause of Death만 예측변수로 사용되었다는 점에 주의해야 합니다. 의사결정트리 속성을 조정하여 모델에 더 많은 예측변수를 포함할 수 있습니다.
아이콘을 클릭합니다. 상세 정보 테이블에서 노드 규칙 탭을 선택합니다. 여기서 Age CHD Diagnosed 및 Cause of Death만 예측변수로 사용되었다는 점에 주의해야 합니다. 의사결정트리 속성을 조정하여 모델에 더 많은 예측변수를 포함할 수 있습니다.
오른쪽 영역에서 속성 탭을 클릭합니다. 가장 확실하게 변경할 속성은 예측변수 재사용입니다. 이 속성을 선택 취소하면 각 예측변수가 하나의 분할에만 사용됩니다. 하지만 이 예에서는 예측변수를 재사용해야 각 노드에 최적의 분할을 생성할
수 있다고 가정해 보겠습니다. 모든 데이터에 이러한 가정이 적용되지 않을 수 있습니다.
대신 최대 레벨 값을
10으로 설정합니다. 그러면 이제 의사결정트리의 최대 깊이가 기본값인 레벨 6개가 아니라 레벨 10개가 됩니다. 상세 정보 테이블의 노드 규칙 탭에서 모든 예측변수가 적어도 한번 사용됩니다.
최대 가지 값을
4로 설정합니다. 이렇게 하면 리프 노드가 아닌 각 노드가 최대 4개의 새로운 노드로 분할됩니다.
트리 개요 창을 보려면 탐색 작업 공간의 오른쪽 위에 있는  아이콘을 클릭합니다. 트리 개요 창에서
아이콘을 클릭합니다. 트리 개요 창에서  아이콘을 클릭하면 트리 개요 창에 맞게 전체 의사결정트리가 표시됩니다.
아이콘을 클릭하면 트리 개요 창에 맞게 전체 의사결정트리가 표시됩니다.
아이콘을 클릭합니다. 트리 개요 창에서 아이콘을 클릭하면 트리 개요 창에 맞게 전체 의사결정트리가 표시됩니다.
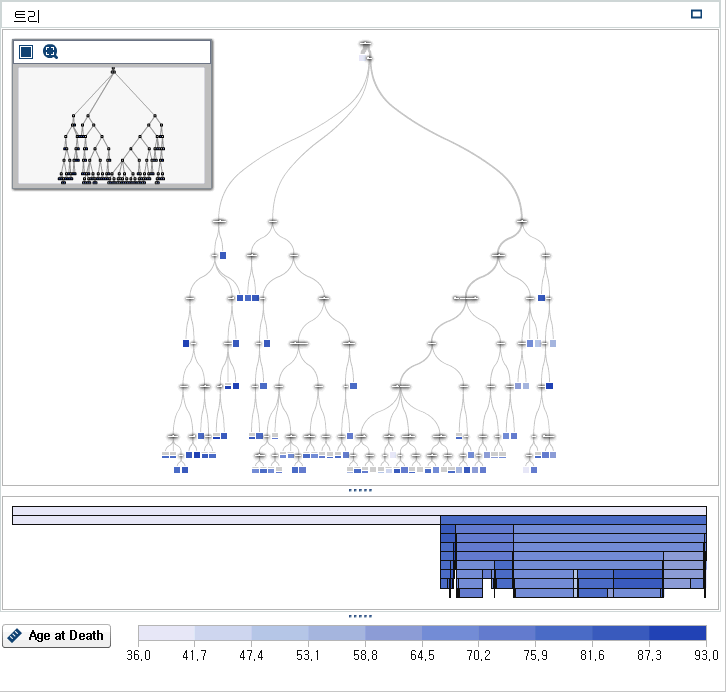
트리 개요 창에서 마우스 오른쪽 버튼을 클릭하고 리프 ID 변수 파생을 선택합니다. 이 변수의 기본 이름은 리프 ID (1)입니다. 새로운 계산 항목 창에서 확인을 클릭합니다. 그러면 리프 ID (1) 변수가 데이터 영역에 표시됩니다.
이제 프로젝트를 저장합니다.