The VARIOGRAM Procedure

Autocorrelation Statistics Types
One measure of spatial autocorrelation provided by PROC VARIOGRAM is Moran’s I statistic, which was introduced by Moran (1950) and is defined as
![\[ I = \frac{n}{(n-1) S^2 W} \sum _{i}\sum _{j}w_{ij} v_ i v_ j \]](images/statug_variogram0263.png)
where 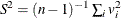 , and
, and 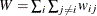 .
.
Another measure of spatial autocorrelation in PROC VARIOGRAM is Geary’s c statistic (Geary 1954), defined as
![\[ c = \frac{1}{2 S^2 W} \sum _{i}\sum _{j}w_{ij} (z_ i - z_ j)^2 \]](images/statug_variogram0266.png)
These expressions indicate that Moran’s I coefficient makes use of the centered variable, whereas the Geary’s c expression uses the noncentered values in the summation.
Inference on these two statistic types comes from approximate tests based on the asymptotic distribution of I and c, which both tend to a normal distribution as n increases. To this end, PROC VARIOGRAM calculates the means and variances of I and c. The outcome depends on the assumption made regarding the distribution 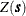 . In particular, you can choose to investigate any of the statistics under the normality (also known as Gaussianity) or the randomization assumption.
Cliff and Ord (1981) provided the equations for the means and variances of the I and c distributions, as described in the following.
. In particular, you can choose to investigate any of the statistics under the normality (also known as Gaussianity) or the randomization assumption.
Cliff and Ord (1981) provided the equations for the means and variances of the I and c distributions, as described in the following.
The normality assumption asserts that the random field follows a normal distribution of constant mean (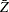 ) and variance, from which the
) and variance, from which the  values are drawn. In this case, the I statistics yield
values are drawn. In this case, the I statistics yield
![\[ \mr{E}_ g[I] = -\frac{1}{n-1} \]](images/statug_variogram0267.png)
and
![\[ \mr{E}_ g[I^2] = \frac{1}{(n+1)(n-1)W^2} (n^2S_1-nS_2+3W^2) \]](images/statug_variogram0268.png)
where 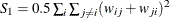 and
and 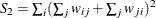 . The corresponding moments for the c statistics are
. The corresponding moments for the c statistics are
![\[ \mr{E}_ g[c] = 1 \]](images/statug_variogram0271.png)
and
![\[ \mr{Var}_{\textit{g}}[c] = \frac{(2S_1+S_2)(n-1)-4W^2}{2(n+1)W^2} \]](images/statug_variogram0272.png)
According to the randomization assumption, the I and c observations are considered in relation to all the different values that I and c could take, respectively, if the n values were repeatedly randomly permuted around the domain D. The moments for the I statistics are now
![\[ \mr{E}_ r[I] = -\frac{1}{n-1} \]](images/statug_variogram0273.png)
and
![\[ \mr{E}_ r[I^2] = \frac{A_1+A_2}{(n-1)(n-2)(n-3)W^2} \]](images/statug_variogram0274.png)
where ![$A_1=n[(n^2-3n+3)S_1-nS_2+3W^2]$](images/statug_variogram0275.png) ,
, ![$A_2=-b_2[n(n-1)S_1-2nS_2+6W^2]$](images/statug_variogram0276.png) . The factor
. The factor 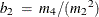 is the coefficient of kurtosis that uses the sample moments
is the coefficient of kurtosis that uses the sample moments 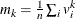 for
for 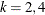 . Finally, the c statistics under the randomization assumption are given by
. Finally, the c statistics under the randomization assumption are given by
![\[ \mr{E}_ r[c] = 1 \]](images/statug_variogram0280.png)
and
![\[ \mr{Var}_{\textit{r}}[c] = \frac{B_1+B_2+B_3}{n(n-2)(n-3)W^2} \]](images/statug_variogram0281.png)
with ![$B_1=(n-1)S_1[n^2-3n+3-(n-1)b_2]$](images/statug_variogram0282.png) ,
, ![$B_2=-\frac{1}{4}(n-1)S_2[n^2+3n-6-(n^2-n+2)b_2]$](images/statug_variogram0283.png) , and
, and ![$B_3=W^2[n^2-3-b_2(n-1)^2]$](images/statug_variogram0284.png) .
.
If you specify LAGDISTANCE=
to be larger than the maximum data distance in your domain, the binary weighting scheme used by the VARIOGRAM procedure leads
to all weights 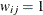 ,
, 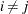 . In this extreme case the preceding definitions can show that the variances of the I and c statistics become zero under either the normality or the randomization assumption.
. In this extreme case the preceding definitions can show that the variances of the I and c statistics become zero under either the normality or the randomization assumption.
A similar effect might occur when you have collocated observations (see the section Pair Formation). The Moran’s I and Geary’s c statistics allow for the inclusion of such pairs in the computations. Hence, contrary to the semivariance analysis, PROC VARIOGRAM does not exclude pairs of collocated data from the autocorrelation statistics.