The SURVEYIMPUTE Procedure

PROC SURVEYIMPUTE Statement
-
PROC SURVEYIMPUTE <options>;
The PROC SURVEYIMPUTE statement invokes the SURVEYIMPUTE procedure. The DATA= option identifies the data set to be analyzed. Table 110.1 summarizes the options available in the PROC SURVEYIMPUTE statement.
Table 110.1: Options Available in the PROC SURVEYIMPUTE Statement
|
Option |
Description |
|---|---|
|
Names the input data set |
|
|
Specifies the imputation method |
|
|
Specifies the number of donors for a recipient |
|
|
Suppresses all displayed output |
|
|
Specifies the sort order of CLASS variables |
|
|
Specifies the random number seed |
|
|
Specifies the variance estimation method |
You can specify the following options.
- DATA=SAS-data-set
-
names the SAS data set that contains the data to be analyzed. If you omit the DATA= option, PROC SURVEYIMPUTE uses the most recently created SAS data set.
- METHOD=FEFI | HOTDECK | HD <(method-option)>
-
specifies the imputation method to impute missing values for all variables in the VAR statement. By default, METHOD=FEFI.
Table 110.2 summarizes the available method-options.
Table 110.2: Imputation Methods
METHOD=
Imputation Method
Method-Options
FEFI
Fully efficient fractional imputation method
HOTDECK | HD
Approximate Bayesian bootstrap
Simple random sampling without replacement
Simple random sampling with replacement
Weighted selection
By default, if all variables that you specify in the VAR statement are also specified in the CLASS statement, then METHOD=FEFI. Otherwise, the default imputation method is METHOD=HOTDECK. You can specify the following values:
- NDONORS=r
-
specifies the number of donor units to impute for a recipient unit when METHOD=HOTDECK . If you specify NDONORS=0, then no imputation is performed. When METHOD=FEFI , the SURVEYIMPUTE procedure performs fully efficient fractional imputation, for which the NDONORS= option does not apply. When METHOD=HOTDECK , NDONORS=1 by default.
- NOPRINT
-
suppresses all displayed output. This option temporarily disables the Output Delivery System (ODS); for more information about ODS, see Chapter 20: Using the Output Delivery System.
- ORDER=DATA | FORMATTED | FREQ | INTERNAL
-
specifies the sort order for the levels of the classification variables (which are specified in the CLASS statement).
This option applies to the levels for all classification variables, except when you use the (default) ORDER=FORMATTED option with numeric classification variables that have no explicit format. In that case, the levels of such variables are ordered by their internal value.
The ORDER= option can take the following values:
Value of ORDER=
Levels Sorted By
DATA
Order of appearance in the input data set
FORMATTED
External formatted value, except for numeric variables with no explicit format, which are sorted by their unformatted (internal) value
FREQ
Descending frequency count; levels with the most observations come first in the order
INTERNAL
Unformatted value
By default, ORDER=FORMATTED. For ORDER=FORMATTED and ORDER=INTERNAL, the sort order is machine-dependent.
For more information about sort order, see the chapter on the SORT procedure in the Base SAS Procedures Guide and the discussion of BY-group processing in SAS Language Reference: Concepts.
- SEED=number
-
specifies the initial seed for random number generation that is used to select donor units for METHOD=HOTDECK . The number should be a positive integer. If you do not specify this option or if number is 0, PROC SURVEYIMPUTE uses the time of day from the computer’s clock to obtain the initial seed.
-
VARMETHOD=BRR < (method-options) > | JACKKNIFE | NONE
REPWEIGHTSTYPE=BRR < (method-options) > | JACKKNIFE | NONE -
computes imputation-adjusted replicate weights. You can specify the following values:
- BRR < (method-options) >
-
computes the imputation-adjusted balanced repeated replication (BRR) weights. The BRR method requires a stratified sample design with two primary sampling units (PSUs) in each stratum. If you specify the VARMETHOD=BRR option, you must also use a STRATA statement unless you provide replicate weights by using a REPWEIGHTS statement. For more information, see the section Balanced Repeated Replication (BRR) Method.
You can specify the following method-options in parentheses after the VARMETHOD=BRR option:
- FAY <=value>
-
requests Fay’s method, which is a modification of the BRR method. For more information, see the section Unadjusted Fay’s BRR Replicate Weights.
You can specify the value of the Fay coefficient, which is used in converting the original sampling weights to replicate weights. The Fay coefficient must be a nonnegative number less than 1. By default, the value of the Fay coefficient is 0.5.
-
HADAMARD=SAS-data-set
H=SAS-data-set -
names a SAS data set that contains the Hadamard matrix for BRR replicate construction. If you do not provide a Hadamard matrix by using this method-option, PROC SURVEYIMPUTE generates an appropriate Hadamard matrix for replicate construction. For more information, see the sections Balanced Repeated Replication (BRR) Method and Hadamard Matrix.
If a Hadamard matrix of a particular dimension exists, it is not necessarily unique. Therefore, if you want to use a specific Hadamard matrix, you must provide the matrix as a SAS data set in the HADAMARD= method-option.
In the HADAMARD= input data set, each variable corresponds to a column of the Hadamard matrix, and each observation corresponds to a row of the matrix. You can use any variable names in the HADAMARD= data set. All values in the data set must equal either 1 or –1. You must ensure that the matrix you provide is indeed a Hadamard matrix—that is,
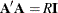 , where
, where 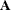 is the Hadamard matrix of dimension R and
is the Hadamard matrix of dimension R and 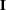 is an identity matrix. PROC SURVEYIMPUTE does not check the validity of the Hadamard matrix that you provide.
is an identity matrix. PROC SURVEYIMPUTE does not check the validity of the Hadamard matrix that you provide.
The HADAMARD= input data set must contain at least H variables, where H denotes the number of first-stage strata in your design. If the data set contains more than H variables, PROC SURVEYIMPUTE uses only the first H variables. Similarly, the HADAMARD= input data set must contain at least H observations.
If you do not specify the REPS= method-option, then the number of replicates is equal to the number of observations in the HADAMARD= input data set. If you specify the number of replicates—for example, REPS =nreps—then the procedure uses the first nreps observations in the HADAMARD= data set to construct the replicates.
You can specify the PRINTH method-option to display the Hadamard matrix that the procedure uses to construct replicates for BRR.
- PRINTH
-
displays the Hadamard matrix that is used to construct replicates for BRR. When you provide the Hadamard matrix in the HADAMARD= method-option, PROC SURVEYIMPUTE displays only the rows and columns that are actually used to construct replicates. For more information, see the sections Balanced Repeated Replication (BRR) Method and Hadamard Matrix.
The PRINTH method-option is not available when you use a REPWEIGHTS statement to provide replicate weights, because the procedure does not use a Hadamard matrix in this case.
- REPS=number
-
specifies the number of replicates for BRR variance estimation. The value of number must be an integer greater than 1.
If you do not provide a Hadamard matrix by using the HADAMARD= method-option, the number of replicates should be greater than the number of strata and should be a multiple of 4. For more information, see the section Balanced Repeated Replication (BRR) Method. If a Hadamard matrix cannot be constructed for the REPS= value that you specify, the value is increased until a Hadamard matrix of that dimension can be constructed. Therefore, it is possible for the actual number of replicates used to be larger than the REPS= value that you specify.
If you provide a Hadamard matrix by using the HADAMARD = method-option, the value of REPS= must not be greater than the number of rows in the Hadamard matrix. If you provide a Hadamard matrix and do not specify the REPS= method-option, the number of replicates equals the number of rows in the Hadamard matrix.
If you do not specify the REPS= or HADAMARD = method-option and do not include a REPWEIGHTS statement, the number of replicates equals the smallest multiple of 4 that is greater than the number of strata.
If you provide replicate weights by using a REPWEIGHTS statement, PROC SURVEYIMPUTE does not use the REPS= method-option. When you use a REPWEIGHTS statement, the number of replicates equals the number of REPWEIGHTS variables.
-
JACKKNIFE
JK -
computes the imputation-adjusted jackknife replicate weights. For more information, see the section Jackknife Method.
- NONE
-
does not compute replicate weights.
By default, VARMETHOD=JACKKNIFE when METHOD=FEFI , and VARMETHOD=NONE when METHOD=HOTDECK .