Introduction to Statistical Modeling with SAS/STAT Software
Estimable Functions
A function 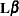 is said to be estimable if there exists a linear combination of the expected value of
is said to be estimable if there exists a linear combination of the expected value of  , such as
, such as ![$\bK \mr{E}[\bY ]$](images/statug_intromod0407.png) , that equals . Since
, that equals . Since ![$\mr{E}[\bY ] = \bX \bbeta $](images/statug_intromod0208.png) , the definition of estimability implies that is estimable if there is a matrix
, the definition of estimability implies that is estimable if there is a matrix  such that
such that 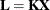 . Another way of looking at this result is that the rows of
. Another way of looking at this result is that the rows of 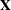 form a generating set from which all estimable functions can be constructed.
form a generating set from which all estimable functions can be constructed.
The concept of estimability of functions is important in the theory and application of linear models because hypotheses of
interest are often expressed as linear combinations of the parameter estimates (for example, hypotheses of equality between
parameters, 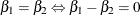 ). Since estimability is not related to the particular value of the parameter estimate, but to the row space of , you can test only hypotheses that consist of estimable functions. Further, because estimability is not related to the value
of
). Since estimability is not related to the particular value of the parameter estimate, but to the row space of , you can test only hypotheses that consist of estimable functions. Further, because estimability is not related to the value
of 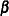 (Searle 1971, p. 181), the choice of the generalized inverse in a situation with
rank-deficient
(Searle 1971, p. 181), the choice of the generalized inverse in a situation with
rank-deficient 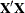 matrix is immaterial, since
matrix is immaterial, since
![\[ \bL \widehat{\bbeta } = \bK \bX \widehat{\bbeta } = \bK \bX \left(\bX ’\bX \right)^{-}\bX ’\bY \]](images/statug_intromod0411.png)
where 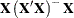 is invariant to the choice of
generalized inverse.
is invariant to the choice of
generalized inverse.
is estimable if and only if 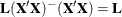 (see, for example, Searle 1971, p. 185). If is of full rank, then the Hermite matrix
(see, for example, Searle 1971, p. 185). If is of full rank, then the Hermite matrix 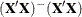 is the identity, which implies that all linear functions are estimable in the full-rank case.
is the identity, which implies that all linear functions are estimable in the full-rank case.
See Chapter 15: The Four Types of Estimable Functions, for many details about the various forms of estimable functions in SAS/STAT.