The GLMSELECT Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsModel-Selection MethodsModel Selection IssuesCriteria Used in Model Selection MethodsCLASS Variable Parameterization and the SPLIT OptionMacro Variables Containing Selected ModelsUsing the STORE StatementBuilding the SSCP MatrixModel AveragingUsing Validation and Test DataCross ValidationExternal Cross ValidationScreeningDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
Elastic Net Selection (ELASTICNET)
The elastic net method bridges the LASSO method and ridge regression. It balances having a parsimonious model with borrowing
strength from correlated regressors, by solving the least squares regression problem with constraints on both the sum of the
absolute coefficients and the sum of the squared coefficients. More specifically, the elastic net coefficients 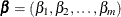 are the solution to the constrained optimization problem
are the solution to the constrained optimization problem
![\[ \min ||\mb{y}-\bX \bbeta ||^2 \qquad \mbox{subject to} \quad \sum _{j=1}^{m} |\beta _ j | \leq t_1, \sum _{j=1}^{m} \beta _ j^2 \leq t_2 \]](images/statug_glmselect0037.png)
The method can be written as the equivalent Lagrangian form
![\[ \min ||\mb{y}-\bX \bbeta ||^2 + \lambda _1 \sum _{j=1}^{m} |\beta _ j | + \lambda _2 \sum _{j=1}^{m} \beta _ j^2 \]](images/statug_glmselect0038.png)
If 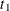 is set to a very large value or, equivalently, if
is set to a very large value or, equivalently, if 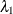 is set to 0, then the elastic net method reduces to ridge regression. If
is set to 0, then the elastic net method reduces to ridge regression. If 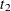 is set to a very large value or, equivalently, if
is set to a very large value or, equivalently, if 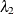 is set to 0, then the elastic net method reduces to LASSO. If and are both large or, equivalently, if and are both set to 0, then the elastic net method reduces to ordinary least squares regression.
is set to 0, then the elastic net method reduces to LASSO. If and are both large or, equivalently, if and are both set to 0, then the elastic net method reduces to ordinary least squares regression.
As stated by Zou and Hastie (2005), the elastic net method can overcome the limitations of LASSO in the following three scenarios:
-
In the case where you have more parameters than observations,
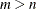 , the LASSO method selects at most n variables before it saturates, because of the nature of the convex optimization problem. This can be a defect for a variable
selection method. By contrast, the elastic net method can select more than n variables in this case because of the ridge regression regularization.
, the LASSO method selects at most n variables before it saturates, because of the nature of the convex optimization problem. This can be a defect for a variable
selection method. By contrast, the elastic net method can select more than n variables in this case because of the ridge regression regularization.
-
If there is a group of variables that have high pairwise correlations, then whereas LASSO tends to select only one variable from that group, the elastic net method can select more than one variable.
-
In the
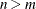 case, if there are high correlations between predictors, it has been empirically observed that the prediction performance
of LASSO is dominated by ridge regression. In this case, the elastic net method can achieve better prediction performance
by using ridge regression regularization.
case, if there are high correlations between predictors, it has been empirically observed that the prediction performance
of LASSO is dominated by ridge regression. In this case, the elastic net method can achieve better prediction performance
by using ridge regression regularization.
An elastic net fit is achieved by building on LASSO estimation, in the following sense. Let 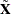 be a matrix obtained by augmenting
be a matrix obtained by augmenting 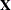 with a scaled identity matrix,
with a scaled identity matrix,
![\[ \tilde{ \bX } =[\bX ; \sqrt {\lambda _2} I] \]](images/statug_glmselect0047.png)
Let 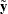 be a vector correspondingly obtained by augmenting the response
be a vector correspondingly obtained by augmenting the response 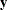 with m 0’s,
with m 0’s,
![\[ \tilde{\mb{y}} =[\mb{y}; \mb{0}] \]](images/statug_glmselect0049.png)
Then the Lagrangian form of the elastic net optimization problem can be reformulated as
![\[ \min ||\tilde{\mb{y}}- \tilde{\bX } \bbeta ||^2 + \lambda _1 \sum _{j=1}^{m} |\beta _ j | \]](images/statug_glmselect0050.png)
In other words, you can solve the elastic net method in the same way as LASSO by using this augmented design matrix 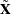 and response
and response 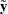 . Therefore, for given , the coefficients of the elastic net fit follow the same piecewise linear path as LASSO. Zou and Hastie (2005) suggest rescaling the coefficients by
. Therefore, for given , the coefficients of the elastic net fit follow the same piecewise linear path as LASSO. Zou and Hastie (2005) suggest rescaling the coefficients by  to deal with the double amount of shrinkage in the elastic net fit, and such rescaling is applied when you specify the ENSCALE
option in the MODEL statement.
to deal with the double amount of shrinkage in the elastic net fit, and such rescaling is applied when you specify the ENSCALE
option in the MODEL statement.
If you have a good estimate of , you can specify the value in the L2= option. If you do not specify a value for , then by default PROC GLMSELECT searches for a value between 0 and 1 that is optimal according to the current CHOOSE=
criterion. Figure 49.12 illustrates the estimation of the ridge regression parameter (L2). Meanwhile, if you do not specify the CHOOSE=
option, then the model at the final step in the selection process is selected for each (L2), and the criterion value shown in Figure 49.12 is the one at the final step that corresponds to the specified STOP=
option (STOP=SBC by default).
Figure 49.12: Estimation of the Ridge Regression Parameter (L2) in the Elastic Net Method
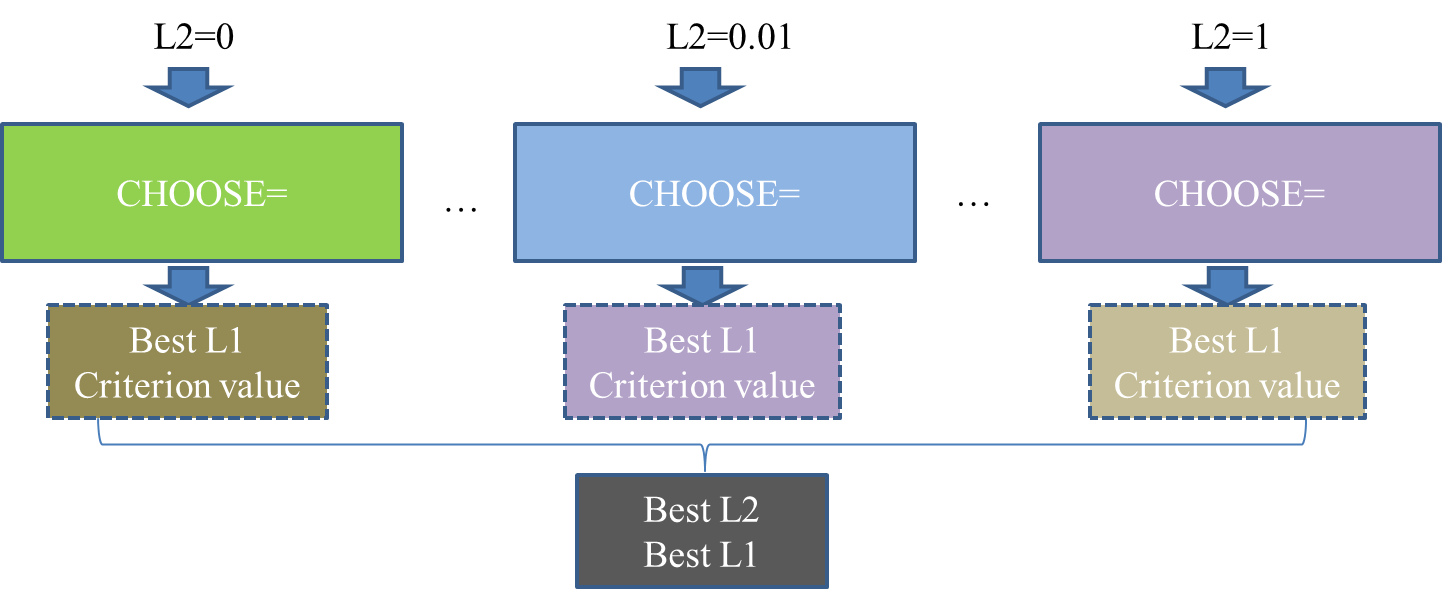
Note that when you specify the L2SEARCH=GOLDEN, it is assumed that the criterion curve that corresponds to the CHOOSE= option
with respect to is a smooth and bowl-shaped curve. However, this assumption is not checked and validated. Hence, the default value for the
L2SEARCH= option is set to GRID.