The MIANALYZE Procedure
- Overview
- Getting Started
-
Syntax

-
Details
-
ExamplesReading Means and Standard Errors from Variables in a DATA= Data SetReading Means and Covariance Matrices from a DATA= COV Data SetReading Regression Results from a DATA= EST Data SetReading Mixed Model Results from PARMS= and COVB= Data SetsReading Generalized Linear Model ResultsReading GLM Results from PARMS= and XPXI= Data SetsReading Logistic Model Results from PARMS= and COVB= Data SetsReading Mixed Model Results with Classification VariablesUsing a TEST statementCombining Correlation Coefficients
- References
You specify input data sets based on the type of inference you requested. For univariate inference, you can use one of the following options:
-
a DATA= data set, which provides both parameter estimates and the associated standard errors
-
a DATA=EST, COV, or CORR data set, which provides both parameter estimates and the associated standard errors either explicitly (type CORR) or through the covariance matrix (type EST, COV)
-
PARMS= data set, which provides both parameter estimates and the associated standard errors
For multivariate inference, which includes the testing of linear hypotheses about parameters, you can use one of the following option combinations:
-
a DATA=EST, COV, or CORR data set, which provides parameter estimates and the associated covariance matrix either explicitly (type EST, COV) or through the correlation matrix and standard errors (type CORR) in a single data set
-
PARMS= and COVB= data sets, which provide parameter estimates in a PARMS= data set and the associated covariance matrix in a COVB= data set
-
PARMS=, COVB=, and PARMINFO= data sets, which provide parameter estimates in a PARMS= data set, the associated covariance matrix in a COVB= data set with variables named
PRM1,PRM2, …, and the effects associated with these variables in a PARMINFO= data set -
PARMS= and XPXI= data sets, which provide parameter estimates and the associated standard errors in a PARMS= data set and the associated
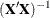 matrix in an XPXI= data set
matrix in an XPXI= data set
The appropriate combination depends on the type of inference and the SAS procedure you used to create the data sets. For instance, if you used PROC REG to create an OUTEST= data set that contains the parameter estimates and covariance matrix, you would use the DATA= option to read the OUTEST= data set.
When the input DATA= data set is a specially structured SAS data set, the data set must contain the variable _Imputation_ to identify the imputation by number. Otherwise, each observation corresponds to an imputation and contains both parameter
estimates and associated standard errors.
If you do not specify an input data set with the DATA= or PARMS= option, then the most recently created SAS data set is used as an input DATA= data set. Note that with a DATA= data set, each effect represents a continuous variable; only regressor effects (continuous variables by themselves) are allowed in the MODELEFFECTS statement.
The DATA= data set provides both parameter estimates and the associated standard errors computed from imputed data sets. Such data sets are typically created with an OUTPUT statement in procedures such as PROC MEANS and PROC UNIVARIATE.
The MIANALYZE procedure reads parameter estimates from observations with variables in the MODELEFFECTS statement, and standard errors for parameter estimates from observations with variables in the STDERR statement. The order of the variables for standard errors must match the order of the variables for parameter estimates.
The specially structured DATA= data set provides both parameter estimates and the associated covariance matrix computed from imputed data sets. Such data sets are created by procedures such as PROC CORR (type COV, CORR) and PROC REG (type EST).
With TYPE=EST, the MIANALYZE procedure reads parameter estimates from observations with _TYPE_=‘PARM’, _TYPE_=‘PARMS’, _TYPE_=‘OLS’, or _TYPE_=‘FINAL’, and covariance matrices for parameter estimates from observations with _TYPE_=‘COV’ or _TYPE_=‘COVB’.
With TYPE=COV, the procedure reads sample means from observations with _TYPE_=‘MEAN’, sample size n from observations with _TYPE_=‘N’, and covariance matrices for variables from observations with _TYPE_=‘COV’.
With TYPE=CORR, the procedure reads sample means from observations with _TYPE_=‘MEAN’, sample size n from observations with _TYPE_=‘N’, correlation matrices for variables from observations with _TYPE_=‘CORR’, and standard errors for variables from observations with _TYPE_=‘STD’. The standard errors and correlation matrix are used to generate a covariance matrix for the variables.
Note that with TYPE=COV or CORR, each covariance matrix for the variables is divided by n to create the covariance matrix for the sample means.
The PARMS= data set contains both parameter estimates and the associated standard errors computed from imputed data sets. Such data sets are typically created with an ODS OUTPUT statement in procedures such as PROC GENMOD, PROC GLM, PROC LOGISTIC, and PROC MIXED.
The MIANALYZE procedure reads effect names from observations with the variable Parameter, Effect, Variable, or Parm. It then reads parameter estimates from observations with the variable Estimate and standard errors for parameter estimates from observations with the variable StdErr.
When the effects contain classification variables, the option CLASSVAR= ctype can be used to identify associated classification variables when reading the classification levels from observations. The available types are FULL, LEVEL, and CLASSVAL. The default is CLASSVAR= FULL.
With CLASSVAR=FULL, the data set contains the classification variables explicitly. PROC MIANALYZE reads the classification levels from observations with their corresponding classification variables. PROC MIXED generates this type of table.
With CLASSVAR=LEVEL, PROC MIANALYZE reads the classification levels for the effect from observations with variables Level1, Level2, and so on, where the variable Level1 contains the classification level for the first classification variable in the effect, and the variable Level2 contains the classification level for the second classification variable in the effect. For each effect, the variables in
the crossed list are displayed before the variables in the nested list. The variable order in the CLASS statement is used
for variables inside each list. PROC GENMOD generates this type of table.
For example, with the following statements, the variable Level1 has the classification level of the variable c2 for the effect c2:
proc mianalyze parms(classvar=Level)= dataparm; class c1 c2 c3; modeleffects c2 c3(c2 c1); run;
For the effect c3(c2 c1), the variable Level1 has the classification level of the variable c3, Level2 has the level of c1, and Level3 has the level of c2.
Similarly, with CLASSVAR=CLASSVAL, PROC MIANALYZE reads the classification levels for the effect from observations with variables
ClassVal0, ClassVal1, and so on, where the variable ClassVal0 contains the classification level for the first classification variable in the effect, and the variable ClassVal1 contains the classification level for the second classification variable in the effect. For each effect, the variables in
the crossed list are displayed before the variables in the nested list. The variable order in the CLASS statement is used
for variables inside each list. PROC LOGISTIC generates this type of tables.
The PARMS= data set contains parameter estimates, and the COVB= data set contains associated covariance matrices computed from imputed data sets. Such data sets are typically created with an ODS OUTPUT statement in procedures such as PROC LOGISTIC, PROC MIXED, and PROC REG.
With a PARMS= data set, the MIANALYZE procedure reads effect names from observations with the variable Parameter, Effect, Variable, or Parm. It then reads parameter estimates from observations with the variable Estimate.
When the effects contain classification variables, the option CLASSVAR= ctype can be used to identify the associated classification variables when reading the classification levels from observations. The available types are FULL, LEVEL, and CLASSVAL, and they are described in the section PARMS <(CLASSVAR= ctype)> = Data Set. The default is CLASSVAR= FULL.
The option EFFECTVAR=etype identifies the variables for parameters displayed in the covariance matrix. The available types are STACKING and ROWCOL. The default is EFFECTVAR=STACKING.
With EFFECTVAR=STACKING, each parameter is displayed by stacking variables in the effect. Begin with the variables in the crossed list, followed by the continuous list, then followed by the nested list. Each classification variable is displayed with its classification level attached. PROC LOGISTIC generates this type of table.
When each effect is a continuous variable by itself, each stacked parameter name reduces to the effect name. PROC REG generates this type of table.
With EFFECTVAR=STACKING, the MIANALYZE procedure reads parameter names from observations with the variable Parameter, Effect, Variable, Parm, or RowName. It then reads covariance matrices from observations with the stacked variables in a COVB= data set.
With EFFECTVAR=ROWCOL, parameters are displayed by the variables Col1, Col2, ... The parameter associated with the variable Col1 is identified by the observation with value 1 for the variable Row. The parameter associated with the variable Col2 is identified by the observation with value 2 for the variable Row. PROC MIXED generates this type of table.
With EFFECTVAR=ROWCOL, the MIANALYZE procedure reads the parameter indices from observations with the variable Row and the effect names from observations with the variable Parameter, Effect, Variable, Parm, or RowName. It then reads covariance matrices from observations with the variables Col1, Col2, and so on in a COVB= data set.
When the effects contain classification variables, the data set contains the classification variables explicitly and the MIANALYZE procedure also reads the classification levels from their corresponding classification variables.
The input PARMS= data set contains parameter estimates and the input COVB= data set contains associated covariance matrices computed from imputed data sets. Such data sets are typically created with an ODS OUTPUT statement using procedure such as PROC GENMOD.
With a PARMS= data set, the MIANALYZE procedure reads effect names from observations with the variable Parameter, Effect, Variable, or Parm. It then reads parameter estimates from observations with the variable Estimate.
When the effects contain classification variables, the option CLASSVAR= ctype can be used to identify the associated classification variables when reading the classification levels from observations. The available types are FULL, LEVEL, and CLASSVAL, and they are described in the section PARMS <(CLASSVAR= ctype)> = Data Set. The default is CLASSVAR= FULL.
With a COVB= data set, the MIANALYZE procedure reads parameter names from observations with the variable Parameter, Effect, Variable, Parm, or RowName. It then reads covariance matrices from observations with the variables Prm1, Prm2, and so on.
The parameters associated with the variables Prm1, Prm2, and so on are identified in the PARMINFO= data set. PROC MIANALYZE reads the parameter names from observations with the
variable Parameter and the corresponding effect from observations with the variable Effect. When the effects contain classification variables, the data set contains the classification variables explicitly and the
MIANALYZE procedure also reads the classification levels from observations with their corresponding classification variables.
The input PARMS= data set contains parameter estimates, and the input XPXI= data set contains associated ![]() matrices computed from imputed data sets. Such data sets are typically created with an ODS OUTPUT statement in a procedure
such as PROC GLM.
matrices computed from imputed data sets. Such data sets are typically created with an ODS OUTPUT statement in a procedure
such as PROC GLM.
With a PARMS= data set, the MIANALYZE procedure reads parameter names from observations with the variable Parameter, Effect, Variable, or Parm. It then reads parameter estimates from observations with the variable Estimate and standard errors for parameter estimates from observations with the variable StdErr.
With a XPXI= data set, the MIANALYZE procedure reads parameter names from observations with the variable Parameter and ![]() matrices from observations with the parameter variables in the data set.
matrices from observations with the parameter variables in the data set.
Note that this combination can be used only when each effect is a continuous variable by itself.