The GENMOD Procedure
-
Overview

-
Getting Started
-
SyntaxPROC GENMOD StatementASSESS StatementBAYES StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementDEVIANCE StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementFWDLINK StatementINVLINK StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementProgramming StatementsREPEATED StatementSLICE StatementSTORE StatementSTRATA StatementVARIANCE StatementWEIGHT StatementZEROMODEL Statement
-
DetailsGeneralized Linear Models TheorySpecification of EffectsParameterization Used in PROC GENMODType 1 AnalysisType 3 AnalysisConfidence Intervals for ParametersF StatisticsLagrange Multiplier StatisticsPredicted Values of the MeanResidualsMultinomial ModelsZero-Inflated ModelsGeneralized Estimating EquationsAssessment of Models Based on Aggregates of ResidualsCase Deletion Diagnostic StatisticsBayesian AnalysisExact Logistic and Exact Poisson RegressionMissing ValuesDisplayed Output for Classical AnalysisDisplayed Output for Bayesian AnalysisDisplayed Output for Exact AnalysisODS Table NamesODS Graphics
-
ExamplesLogistic RegressionNormal Regression, Log Link Gamma Distribution Applied to Life DataOrdinal Model for Multinomial DataGEE for Binary Data with Logit Link FunctionLog Odds Ratios and the ALR AlgorithmLog-Linear Model for Count DataModel Assessment of Multiple Regression Using Aggregates of ResidualsAssessment of a Marginal Model for Dependent DataBayesian Analysis of a Poisson Regression ModelExact Poisson Regression
- References
REPEATED SUBJECT=subject-effect </ options> ;
The REPEATED statement specifies the covariance structure of multivariate responses for GEE model fitting in the GENMOD procedure. In addition, the REPEATED statement controls the iterative fitting algorithm used in GEEs and specifies optional output. Other GENMOD procedure statements, such as the MODEL and CLASS statements, are used in the same way as they are for ordinary generalized linear models to specify the regression model for the mean of the responses.
Table 40.8 summarizes the options available in the REPEATED statement.
Table 40.8: REPEATED Statement Options
|
Option |
Description |
|---|---|
|
Specifies initial values for log odds ratio regression parameters |
|
|
Specifies the convergence criterion for GEE parameter estimation |
|
|
Displays the estimated correlation matrix |
|
|
Displays the estimated working correlation matrix |
|
|
Displays the estimated covariance matrix |
|
|
Displays the estimated empirical correlation matrix |
|
|
Displays the estimated empirical covariance matrix |
|
|
Specifies initial values of the regression parameters estimation |
|
|
Specifies either an initial or a fixed value of the intercept |
|
|
Specifies the regression structure of the log odds ratio |
|
|
Specifies the maximum number of iterations |
|
|
Displays the estimated model-based correlation matrix |
|
|
Displays the estimated model-based covariance matrix |
|
|
Displays an analysis of parameter estimates table |
|
|
Displays an analysis of maximum likelihood parameter estimates table |
|
|
Specifies the number of iterations between updates of the working correlation matrix |
|
|
Groups by subject and sorts within subject |
|
|
Specifies a variable defining subclusters |
|
|
Identifies a different subject, or cluster |
|
|
Specifies the working correlation matrix structure |
|
|
Uses the SAS ‘Version 6’ method of computing normalized Pearson chi-square |
|
|
Specifies the order of measurements within subjects |
|
|
Specifies the pairs of responses |
|
|
Specifies the full |
|
|
Specifies the rows of the |
- SUBJECT=subject-effect
-
identifies subjects in the input data set. The subject-effect can be a single variable, an interaction effect, a nested effect, or a combination. Each distinct value, or level, of the effect identifies a different subject, or cluster. Responses from different subjects are assumed to be statistically independent, and responses within subjects are assumed to be correlated. A subject-effect must be specified, and variables used in defining the subject-effect must be listed in the CLASS statement. The input data set does not need to be sorted by subject (see the SORTED option).
The options control how the model is fit and what output is produced. You can specify the following options after a slash (/).
- ALPHAINIT=numbers
-
specifies initial values for log odds ratio regression parameters if the LOGOR= option is specified for binary data. If this option is not specified, an initial value of 0.01 is used for all the parameters.
- CONVERGE=number
-
specifies the convergence criterion for GEE parameter estimation. If the maximum absolute difference between regression parameter estimates is less than the value of number on two successive iterations, convergence is declared. If the absolute value of a regression parameter estimate is greater than 0.08, then the absolute difference normalized by the regression parameter value is used instead of the absolute difference. The default value of number is 0.0001.
- CORRW
-
displays the estimated working correlation matrix. If you specify an exchangeable working correlation structure with the CORR=EXCH option, the CORRW option is not needed to view the estimated correlation, since a table is printed by default that contains the single estimated correlation.
- CORRB
-
displays the estimated regression parameter correlation matrix. Both model-based and empirical correlations are displayed.
- COVB
-
displays the estimated regression parameter covariance matrix. Both model-based and empirical covariances are displayed.
- ECORRB
-
displays the estimated regression parameter empirical correlation matrix.
- ECOVB
-
displays the estimated regression parameter empirical covariance matrix.
- INTERCEPT=number
-
specifies either an initial or a fixed value of the intercept regression parameter in the GEE model. If you specify the NOINT option in the MODEL statement, then the intercept is fixed at the value of number.
- INITIAL=numbers
-
specifies initial values of the regression parameters estimation, other than the intercept parameter, for GEE estimation. If this option is not specified, the estimated regression parameters assuming independence for all responses are used for the initial values.
- LOGOR=log-odds-ratio-structure-keyword
-
specifies the regression structure of the log odds ratio used to model the association of the responses from subjects for binary data. The response syntax must be of the single variable type, the distribution must be binomial, and the data must be binary. Table 40.9 displays the log odds ratio structure keywords and the corresponding log odds ratio regression structures. See the section Alternating Logistic Regressions for definitions of the log odds ratio types and examples of specifying log odds ratio models. You should specify either the LOGOR= or the TYPE= option, but not both.
Table 40.9: Log Odds Ratio Regression Structures
Keyword
Log Odds Ratio Regression Structure
EXCH
Exchangeable
FULLCLUST
Fully parameterized clusters
LOGORVAR(variable)
Indicator variable for specifying block effects
NESTK
k-nested
NEST1
1-nested
ZFULL
Fully specified
 matrix specified in ZDATA= data set
matrix specified in ZDATA= data set
ZREP
Single cluster specification for replicated
matrix specified
in ZDATA= data set
ZREP(matrix)
Single cluster specification for replicated
matrix
-
MAXITER=number
MAXIT=number -
specifies the maximum number of iterations allowed in the iterative GEE estimation process. The default number is 50.
- MCORRB
-
displays the estimated regression parameter model-based correlation matrix.
- MCOVB
-
displays the estimated regression parameter model-based covariance matrix.
- MODELSE
-
displays an analysis of parameter estimates table that uses model-based standard errors for inference. By default, an “Analysis of Parameter Estimates” table based on empirical standard errors is displayed.
- PRINTMLE
-
displays an analysis of maximum likelihood parameter estimates table. The maximum likelihood estimates are not displayed unless this option is specified.
- RUPDATE=number
-
specifies the number of iterations between updates of the working correlation matrix. For example, RUPDATE=5 specifies that the working correlation is updated once for every five regression parameter updates. The default value of number is 1; that is, the working correlation is updated every time the regression parameters are updated.
- SORTED
-
specifies that the input data are grouped by subject and sorted within subject. If this option is not specified, then the procedure internally sorts by subject-effect and within subject-effect, if a within subject-effect is specified.
-
SUBCLUSTER=variable
SUBCLUST=variable -
specifies a variable defining subclusters for the 1-nested or k-nested log odds ratio association modeling structures. This variable must be listed in the CLASS statement.
-
TYPE=correlation-structure keyword
CORR=correlation-structure keyword -
specifies the structure of the working correlation matrix used to model the correlation of the responses from subjects. Table 40.10 displays the correlation structure keywords and the corresponding correlation structures. The default working correlation type is the independent (CORR=IND). See the section Details: GENMOD Procedure for definitions of the correlation matrix types. You should specify LOGOR= or TYPE= but not both.
Table 40.10: Correlation Structure Types
Keyword
Correlation Matrix Type
AR
AR(1)
Autoregressive(1)
EXCH
CS
Exchangeable
IND
Independent
MDEP(number)
m-dependent with m=number
UNSTR
UN
Unstructured
USER
FIXED (matrix)
Fixed, user-specified correlation matrix
For example, you can specify a fixed
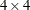 correlation matrix with the following option:
correlation matrix with the following option:
type=user( 1.0 0.9 0.8 0.6 0.9 1.0 0.9 0.8 0.8 0.9 1.0 0.9 0.6 0.8 0.9 1.0 ) - V6CORR
-
specifies that the SAS ‘Version 6’ method of computing the normalized Pearson chi-square be used for working correlation estimation and for model-based covariance matrix scale factor.
- WITHINSUBJECT | WITHIN=within subject-effect
-
defines an effect specifying the order of measurements within subjects. Each distinct level of the within subject-effect defines a different response from the same subject. If the data are in proper order within each subject, you do not need to specify this option.
If some measurements do not appear in the data for some subjects, this option properly orders the existing measurements and treats the omitted measurements as missing values. If the WITHINSUBJECT= option is not used in this situation, measurements might be improperly ordered and missing values assumed for the last measurements in a cluster.
Variables used in defining the within subject-effect must be listed in the CLASS statement.
- YPAIR=variable-list
-
specifies the variables in the ZDATA= data set corresponding to pairs of responses for log odds ratio association modeling.
- ZDATA=SAS-data-set
-
specifies a SAS data set containing either the full
matrix for log odds ratio association modeling or the matrix for a single complete cluster to be replicated for all clusters.
- ZROW=variable-list
-
specifies the variables in the ZDATA= data set corresponding to rows of the
matrix for log odds ratio association modeling.