The SURVEYLOGISTIC Procedure
- Overview
- Getting Started
-
Syntax
 PROC SURVEYLOGISTIC Statement BY Statement CLASS Statement CLUSTER Statement CONTRAST Statement DOMAIN Statement EFFECT Statement ESTIMATE Statement FREQ Statement LSMEANS Statement LSMESTIMATE Statement MODEL Statement OUTPUT Statement REPWEIGHTS Statement SLICE Statement STORE Statement STRATA Statement TEST Statement UNITS Statement WEIGHT Statement
PROC SURVEYLOGISTIC Statement BY Statement CLASS Statement CLUSTER Statement CONTRAST Statement DOMAIN Statement EFFECT Statement ESTIMATE Statement FREQ Statement LSMEANS Statement LSMESTIMATE Statement MODEL Statement OUTPUT Statement REPWEIGHTS Statement SLICE Statement STORE Statement STRATA Statement TEST Statement UNITS Statement WEIGHT Statement -
Details
Missing Values Model Specification Model Fitting Survey Design Information Logistic Regression Models and Parameters Variance Estimation Domain Analysis Hypothesis Testing and Estimation Linear Predictor, Predicted Probability, and Confidence Limits Output Data Sets Displayed Output ODS Table Names ODS Graphics
-
Examples
- References
Example 87.1 Stratified Cluster Sampling
A market research firm conducts a survey among undergraduate students at a certain university to evaluate three new Web designs for a commercial Web site targeting undergraduate students at the university.
The sample design is a stratified sample where the strata are students’ classes. Within each class, 300 students are randomly selected by using simple random sampling without replacement. The total number of students in each class in the fall semester of 2001 is shown in the following table:
Class |
Enrollment |
|---|---|
1 - Freshman |
3,734 |
2 - Sophomore |
3,565 |
3 - Junior |
3,903 |
4 - Senior |
4,196 |
This total enrollment information is saved in the SAS data set Enrollment by using the following SAS statements:
proc format ;
value Class
1='Freshman' 2='Sophomore'
3='Junior' 4='Senior';
run;
data Enrollment;
format Class Class.;
input Class _TOTAL_;
datalines;
1 3734
2 3565
3 3903
4 4196
;
In the data set Enrollment, the variable _TOTAL_ contains the enrollment figures for all classes. They are also the population size for each stratum in this example.
Each student selected in the sample evaluates one randomly selected Web design by using the following scale:
|
Dislike very much |
|
Dislike |
|
Neutral |
|
Like |
|
Like very much |

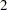
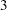
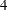
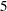
The survey results are collected and shown in the following table, with the three different Web designs coded as A, B, and C.
Evaluation of New Web Designs |
||||||
|---|---|---|---|---|---|---|
Rating Counts |
||||||
Strata |
Design |
1 |
2 |
3 |
4 |
5 |
Freshman |
A |
10 |
34 |
35 |
16 |
15 |
B |
5 |
6 |
24 |
30 |
25 |
|
C |
11 |
14 |
20 |
34 |
21 |
|
Sophomore |
A |
19 |
12 |
26 |
18 |
25 |
B |
10 |
18 |
32 |
23 |
26 |
|
C |
15 |
22 |
34 |
9 |
20 |
|
Junior |
A |
8 |
21 |
23 |
26 |
22 |
B |
1 |
4 |
15 |
33 |
47 |
|
C |
16 |
19 |
30 |
23 |
12 |
|
Senior |
A |
11 |
14 |
24 |
33 |
18 |
B |
8 |
15 |
25 |
30 |
22 |
|
C |
2 |
34 |
30 |
18 |
16 |
|
The survey results are stored in a SAS data set WebSurvey by using the following SAS statements:
proc format ;
value Design 1='A' 2='B' 3='C';
value Rating
1='dislike very much'
2='dislike'
3='neutral'
4='like'
5='like very much';
run;
data WebSurvey;
format Class Class. Design Design. Rating Rating. ;
do Class=1 to 4;
do Design=1 to 3;
do Rating=1 to 5;
input Count @@;
output;
end;
end;
end;
datalines;
10 34 35 16 15 8 21 23 26 22 5 10 24 30 21
1 14 25 23 37 11 14 20 34 21 16 19 30 23 12
19 12 26 18 25 11 14 24 33 18 10 18 32 23 17
8 15 35 30 12 15 22 34 9 20 2 34 30 18 16
;
data WebSurvey; set WebSurvey;
if Class=1 then Weight=3734/300;
if Class=2 then Weight=3565/300;
if Class=3 then Weight=3903/300;
if Class=4 then Weight=4196/300;
run;
The data set WebSurvey contains the variables Class, Design, Rating, Count, and Weight. The variable class is the stratum variable, with four strata: freshman, sophomore, junior, and senior. The variable Design specifies the three new Web designs: A, B, and C. The variable Rating contains students’ evaluations of the new Web designs. The variable counts gives the frequency with which each Web design received each rating within each stratum. The variable weight contains the sampling weights, which are the reciprocals of selection probabilities in this example.
Output 87.1.1 shows the first 20 observations of the data set.
| Obs | Class | Design | Rating | Count | Weight |
|---|---|---|---|---|---|
| 1 | Freshman | A | dislike very much | 10 | 12.4467 |
| 2 | Freshman | A | dislike | 34 | 12.4467 |
| 3 | Freshman | A | neutral | 35 | 12.4467 |
| 4 | Freshman | A | like | 16 | 12.4467 |
| 5 | Freshman | A | like very much | 15 | 12.4467 |
| 6 | Freshman | B | dislike very much | 8 | 12.4467 |
| 7 | Freshman | B | dislike | 21 | 12.4467 |
| 8 | Freshman | B | neutral | 23 | 12.4467 |
| 9 | Freshman | B | like | 26 | 12.4467 |
| 10 | Freshman | B | like very much | 22 | 12.4467 |
| 11 | Freshman | C | dislike very much | 5 | 12.4467 |
| 12 | Freshman | C | dislike | 10 | 12.4467 |
| 13 | Freshman | C | neutral | 24 | 12.4467 |
| 14 | Freshman | C | like | 30 | 12.4467 |
| 15 | Freshman | C | like very much | 21 | 12.4467 |
| 16 | Sophomore | A | dislike very much | 1 | 11.8833 |
| 17 | Sophomore | A | dislike | 14 | 11.8833 |
| 18 | Sophomore | A | neutral | 25 | 11.8833 |
| 19 | Sophomore | A | like | 23 | 11.8833 |
| 20 | Sophomore | A | like very much | 37 | 11.8833 |
The following SAS statements perform the logistic regression:
proc surveylogistic data=WebSurvey total=Enrollment; stratum Class; freq Count; class Design; model Rating (order=internal) = design ; weight Weight; run;
The PROC SURVEYLOGISTIC statement invokes the procedure. The TOTAL= option specifies the data set Enrollment, which contains the population totals in the strata. The population totals are used to calculate the finite population correction factor in the variance estimates. The response variable Rating is in the ordinal scale. A cumulative logit model is used to investigate the responses to the Web designs. In the MODEL statement, rating is the response variable, and Design is the effect in the regression model. The ORDER=INTERNAL option is used for the response variable Rating to sort the ordinal response levels of Rating by its internal (numerical) values rather than by the formatted values (for example, 'like very much'). Because the sample design involves stratified simple random sampling, the STRATA statement is used to specify the stratification variable Class. The WEIGHT statement specifies the variable Weight for sampling weights.
The sample and analysis summary is shown in Output 87.1.2. There are five response levels for the Rating, with 'dislike very much' as the lowest ordered value. The regression model is modeling lower cumulative probabilities by using logit as the link function. Because the TOTAL= option is used, the finite population correction is included in the variance estimation. The sampling weight is also used in the analysis.
| Model Information | |
|---|---|
| Data Set | WORK.WEBSURVEY |
| Response Variable | Rating |
| Number of Response Levels | 5 |
| Frequency Variable | Count |
| Stratum Variable | Class |
| Number of Strata | 4 |
| Weight Variable | Weight |
| Model | Cumulative Logit |
| Optimization Technique | Fisher's Scoring |
| Variance Adjustment | Degrees of Freedom (DF) |
| Finite Population Correction | Used |
| Response Profile | |||
|---|---|---|---|
| Ordered Value |
Rating | Total Frequency |
Total Weight |
| 1 | dislike very much | 116 | 1489.0733 |
| 2 | dislike | 227 | 2933.0433 |
| 3 | neutral | 338 | 4363.3767 |
| 4 | like | 283 | 3606.8067 |
| 5 | like very much | 236 | 3005.7000 |
In Output 87.1.3, the score chi-square for testing the proportional odds assumption is 98.1957, which is highly significant. This indicates that the cumulative logit model might not adequately fit the data.
| Score Test for the Proportional Odds Assumption |
||
|---|---|---|
| Chi-Square | DF | Pr > ChiSq |
| 98.1957 | 6 | <.0001 |
An alternative model is to use the generalized logit model with the LINK=GLOGIT option, as shown in the following SAS statements:
proc surveylogistic data=WebSurvey total=Enrollment; stratum Class; freq Count; class Design; model Rating (ref='neutral') = Design /link=glogit; weight Weight; run;
The REF='neutral' option is used for the response variable Rating to indicate that all other response levels are referenced to the level 'neutral.' The option LINK=GLOGIT option requests that the procedure fit a generalized logit model.
The summary of the analysis is shown in Output 87.1.4, which indicates that the generalized logit model is used in the analysis.
| Model Information | |
|---|---|
| Data Set | WORK.WEBSURVEY |
| Response Variable | Rating |
| Number of Response Levels | 5 |
| Frequency Variable | Count |
| Stratum Variable | Class |
| Number of Strata | 4 |
| Weight Variable | Weight |
| Model | Generalized Logit |
| Optimization Technique | Newton-Raphson |
| Variance Adjustment | Degrees of Freedom (DF) |
| Finite Population Correction | Used |
| Response Profile | |||
|---|---|---|---|
| Ordered Value |
Rating | Total Frequency |
Total Weight |
| 1 | dislike | 227 | 2933.0433 |
| 2 | dislike very much | 116 | 1489.0733 |
| 3 | like | 283 | 3606.8067 |
| 4 | like very much | 236 | 3005.7000 |
| 5 | neutral | 338 | 4363.3767 |
Output 87.1.5 shows the parameterization for the main effect Design.
| Class Level Information | |||
|---|---|---|---|
| Class | Value | Design Variables | |
| Design | A | 1 | 0 |
| B | 0 | 1 | |
| C | -1 | -1 | |
The parameter and odds ratio estimates are shown in Output 87.1.6. For each odds ratio estimate, the 95% confidence limits shown in the table contain the value 1.0. Therefore, no conclusion about which Web design is preferred can be made based on this survey.
| Analysis of Maximum Likelihood Estimates | |||||||
|---|---|---|---|---|---|---|---|
| Parameter | Rating | DF | Estimate | Standard Error |
Wald Chi-Square |
Pr > ChiSq | |
| Intercept | dislike | 1 | -0.3964 | 0.0832 | 22.7100 | <.0001 | |
| Intercept | dislike very much | 1 | -1.0826 | 0.1045 | 107.3889 | <.0001 | |
| Intercept | like | 1 | -0.1892 | 0.0780 | 5.8888 | 0.0152 | |
| Intercept | like very much | 1 | -0.3767 | 0.0824 | 20.9223 | <.0001 | |
| Design | A | dislike | 1 | -0.0942 | 0.1166 | 0.6518 | 0.4195 |
| Design | A | dislike very much | 1 | -0.0647 | 0.1469 | 0.1940 | 0.6596 |
| Design | A | like | 1 | -0.1370 | 0.1104 | 1.5400 | 0.2146 |
| Design | A | like very much | 1 | 0.0446 | 0.1130 | 0.1555 | 0.6933 |
| Design | B | dislike | 1 | 0.0391 | 0.1201 | 0.1057 | 0.7451 |
| Design | B | dislike very much | 1 | 0.2721 | 0.1448 | 3.5294 | 0.0603 |
| Design | B | like | 1 | 0.1669 | 0.1102 | 2.2954 | 0.1298 |
| Design | B | like very much | 1 | 0.1420 | 0.1174 | 1.4641 | 0.2263 |
| Odds Ratio Estimates | ||||
|---|---|---|---|---|
| Effect | Rating | Point Estimate | 95% Wald Confidence Limits |
|
| Design A vs C | dislike | 0.861 | 0.583 | 1.272 |
| Design A vs C | dislike very much | 1.153 | 0.692 | 1.923 |
| Design A vs C | like | 0.899 | 0.618 | 1.306 |
| Design A vs C | like very much | 1.260 | 0.851 | 1.865 |
| Design B vs C | dislike | 0.984 | 0.659 | 1.471 |
| Design B vs C | dislike very much | 1.615 | 0.975 | 2.675 |
| Design B vs C | like | 1.218 | 0.838 | 1.768 |
| Design B vs C | like very much | 1.389 | 0.925 | 2.086 |