The FASTCLUS Procedure

| Missing Values |
Observations with all missing values are excluded from the analysis. If you specify the NOMISS option, observations with any missing values are excluded. Observations with missing values cannot be cluster seeds.
The distance between an observation with missing values and a cluster seed is obtained by computing the squared distance based on the nonmissing values, multiplying by the ratio of the number of variables,  , to the number of variables having nonmissing values,
, to the number of variables having nonmissing values,  , and taking the square root:
, and taking the square root:
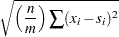 |
where
 |
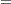 |
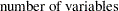 |
|||
 |
|
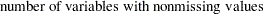 |
|||
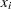 |
|
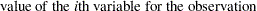 |
|||
 |
|
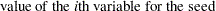 |
If you specify the LEAST=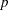 option with a power other than
option with a power other than 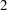 (the default), the distance is computed using
(the default), the distance is computed using
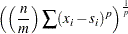 |
The summation is taken over variables with nonmissing values.
The IMPUTE option fills in missing values in the OUT= output data set.