| Introduction to Bayesian Analysis Procedures |
| Assessing Markov Chain Convergence |
Simulation-based Bayesian inference requires using simulated draws to summarize the posterior distribution or calculate any relevant quantities of interest. You need to treat the simulation draws with care. There are usually two issues. First, you have to decide whether the Markov chain has reached its stationary, or the desired posterior, distribution. Second, you have to determine the number of iterations to keep after the Markov chain has reached stationarity. Convergence diagnostics help to resolve these issues. Note that many diagnostic tools are designed to verify a necessary but not sufficient condition for convergence. There are no conclusive tests that can tell you when the Markov chain has converged to its stationary distribution. You should proceed with caution. Also, note that you should check the convergence of all parameters, and not just those of interest, before proceeding to make any inference. With some models, certain parameters can appear to have very good convergence behavior, but that could be misleading due to the slow convergence of other parameters. If some of the parameters have bad mixing, you cannot get accurate posterior inference for parameters that appear to have good mixing. See Cowles and Carlin (1996) and Brooks and Roberts (1998) for discussions about convergence diagnostics.
Visual Analysis via Trace Plots
Trace plots of samples versus the simulation index can be very useful in assessing convergence. The trace tells you if the chain has not yet converged to its stationary distribution—that is, if it needs a longer burn-in period. A trace can also tell you whether the chain is mixing well. A chain might have reached stationarity if the distribution of points is not changing as the chain progresses. The aspects of stationarity that are most recognizable from a trace plot are a relatively constant mean and variance. A chain that mixes well traverses its posterior space rapidly, and it can jump from one remote region of the posterior to another in relatively few steps. Figure 7.1 through Figure 7.4 display some typical features that you might see in trace plots. The traces are for a parameter called 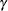 .
.
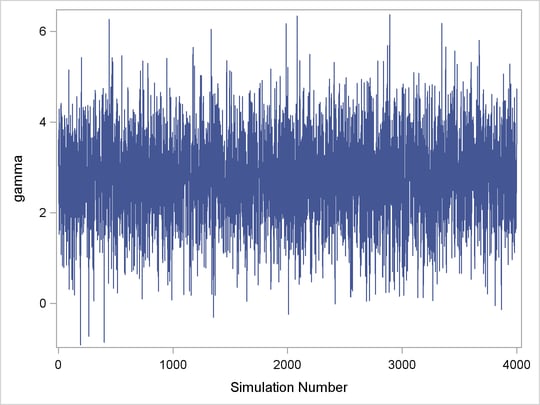
Figure 7.1 displays a "perfect" trace plot. Note that the center of the chain appears to be around the value 3, with very small fluctuations. This indicates that the chain could have reached the right distribution. The chain is mixing well; it is exploring the distribution by traversing to areas where its density is very low. You can conclude that the mixing is quite good here.
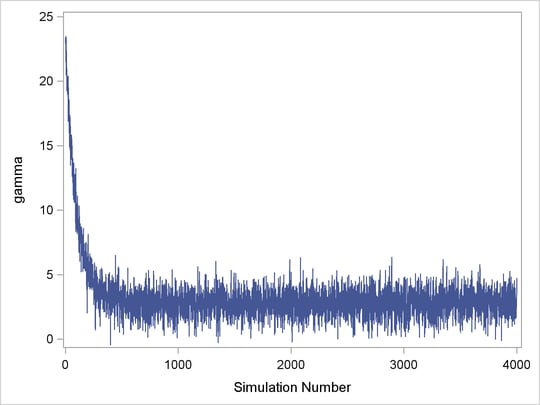
Figure 7.2 displays a trace plot for a chain that starts at a very remote initial value and makes its way to the targeting distribution. The first few hundred observations should be discarded. This chain appears to be mixing very well locally. It travels relatively quickly to the target distribution, reaching it in a few hundred iterations. If you have a chain that looks like this, you would want to increase the burn-in sample size. If you need to use this sample to make inferences, you would want to use only the samples toward the end of the chain.
Figure 7.3 demonstrates marginal mixing. The chain is taking only small steps and does not traverse its distribution quickly. This type of trace plot is typically associated with high autocorrelation among the samples. To obtain a few thousand independent samples, you need to run the chain for much longer.
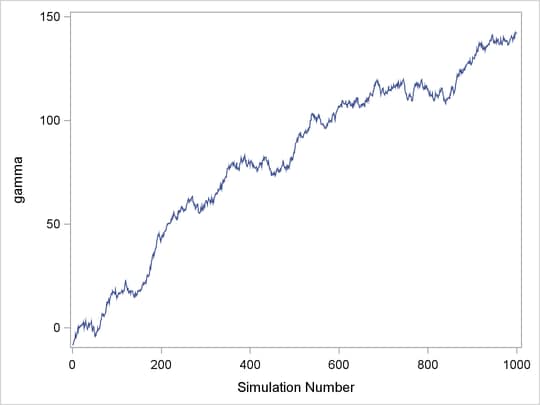
The trace plot shown in Figure 7.4 depicts a chain with serious problems. It is mixing very slowly, and it offers no evidence of convergence. You would want to try to improve the mixing of this chain. For example, you might consider reparameterizing your model on the log scale. Run the Markov chain for a long time to see where it goes. This type of chain is entirely unsuitable for making parameter inferences.
Statistical Diagnostic Tests
The Bayesian procedures include several statistical diagnostic tests that can help you assess Markov chain convergence. For a detailed description of each of the diagnostic tests, see the following subsections. Table 7.1 provides a summary of the diagnostic tests and their interpretations.
Name |
Description |
Interpretation of the Test |
|---|---|---|
Gelman-Rubin |
Uses parallel chains with dispersed initial values to test whether they all converge to the same target distribution. Failure could indicate the presence of a multi-mode posterior distribution (different chains converge to different local modes) or the need to run a longer chain (burn-in is yet to be completed). |
One-sided test based on a variance ratio test statistic. Large |
Geweke |
Tests whether the mean estimates have converged by comparing means from the early and latter part of the Markov chain. |
Two-sided test based on a |
Heidelberger-Welch (stationarity test) |
Tests whether the Markov chain is a covariance (or weakly) stationary process. Failure could indicate that a longer Markov chain is needed. |
One-sided test based on a Cramer–von Mises statistic. Small |
Heidelberger-Welch (half-width test) |
Reports whether the sample size is adequate to meet the required accuracy for the mean estimate. Failure could indicate that a longer Markov chain is needed. |
If a relative half-width statistic is greater than a predetermined accuracy measure, this indicates rejection. |
Raftery-Lewis |
Evaluates the accuracy of the estimated (desired) percentiles by reporting the number of samples needed to reach the desired accuracy of the percentiles. Failure could indicate that a longer Markov chain is needed. |
If the total samples needed are fewer than the Markov chain sample, this indicates rejection. |
autocorrelation |
Measures dependency among Markov chain samples. |
High correlations between long lags indicate poor mixing. |
effective sample size |
Relates to autocorrelation; measures mixing of the Markov chain. |
Large discrepancy between the effective sample size and the simulation sample size indicates poor mixing. |
Gelman and Rubin Diagnostics
Gelman and Rubin diagnostics (Gelman and Rubin; 1992; Brooks and Gelman; 1997) are based on analyzing multiple simulated MCMC chains by comparing the variances within each chain and the variance between chains. Large deviation between these two variances indicates nonconvergence.
Define 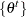 , where
, where 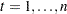 , to be the collection of a single Markov chain output. The parameter
, to be the collection of a single Markov chain output. The parameter 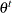 is the
is the  th sample of the Markov chain. For notational simplicity,
th sample of the Markov chain. For notational simplicity, 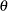 is assumed to be single dimensional in this section.
is assumed to be single dimensional in this section.
Suppose you have 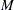 parallel MCMC chains that were initialized from various parts of the target distribution. Each chain is of length
parallel MCMC chains that were initialized from various parts of the target distribution. Each chain is of length  (after discarding the burn-in). For each , the simulations are labeled as
(after discarding the burn-in). For each , the simulations are labeled as  and
and 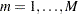 . The between-chain variance
. The between-chain variance 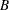 and the within-chain variance
and the within-chain variance 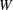 are calculated as
are calculated as
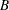 |
 |
 |
|||
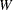 |
|
 |
The posterior marginal variance, 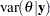 , is a weighted average of and . The estimate of the variance is
, is a weighted average of and . The estimate of the variance is
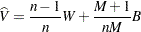 |
If all chains have reached the target distribution, this posterior variance estimate should be very close to the within-chain variance . Therefore, you would expect to see the ratio  be close to
be close to  . The square root of this ratio is referred to as the potential scale reduction factor (PSRF). A large PSRF indicates that the between-chain variance is substantially greater than the within-chain variance, so that longer simulation is needed. If the PSRF is close to 1, you can conclude that each of the chains has stabilized, and they are likely to have reached the target distribution.
. The square root of this ratio is referred to as the potential scale reduction factor (PSRF). A large PSRF indicates that the between-chain variance is substantially greater than the within-chain variance, so that longer simulation is needed. If the PSRF is close to 1, you can conclude that each of the chains has stabilized, and they are likely to have reached the target distribution.
A refined version of PSRF is calculated, as suggested by Brooks and Gelman (1997), as
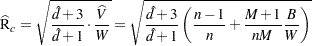 |
where
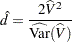 |
and
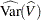 |
|
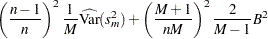 |
|||
 |
|
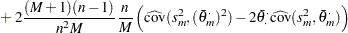 |
All the Bayesian procedures also produce an upper 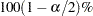 confidence limit of
confidence limit of 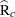 . Gelman and Rubin (1992) showed that the ratio
. Gelman and Rubin (1992) showed that the ratio  in has an F distribution with degrees of freedom
in has an F distribution with degrees of freedom 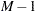 and
and 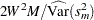 . Because you are concerned only if the scale is large, not small, only the upper confidence limit is reported. This is written as
. Because you are concerned only if the scale is large, not small, only the upper confidence limit is reported. This is written as
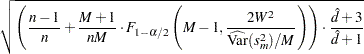 |
In the Bayesian procedures, you can specify the number of chains that you want to run. Typically three chains are sufficient. The first chain is used for posterior inference, such as mean and standard deviation; the other chains are used for computing the diagnostics and are discarded afterward. This test can be computationally costly, because it prolongs the simulation -fold.
It is best to choose different initial values for all chains. The initial values should be as dispersed from each other as possible so that the Markov chains can fully explore different parts of the distribution before they converge to the target. Similar initial values can be risky because all of the chains can get stuck in a local maximum; that is something this convergence test cannot detect. If you do not supply initial values for all the different chains, the procedures generate them for you.
Geweke Diagnostics
The Geweke test (Geweke; 1992) compares values in the early part of the Markov chain to those in the latter part of the chain in order to detect failure of convergence. The statistic is constructed as follows. Two subsequences of the Markov chain are taken out, with 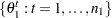 and
and 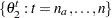 , where
, where 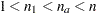 . Let
. Let 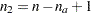 , and define
, and define
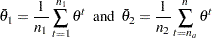 |
Let 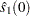 and
and 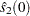 denote consistent spectral density estimates at zero frequency (see the subsection Spectral Density Estimate at Zero Frequency for estimation details) for the two MCMC chains, respectively. If the ratios
denote consistent spectral density estimates at zero frequency (see the subsection Spectral Density Estimate at Zero Frequency for estimation details) for the two MCMC chains, respectively. If the ratios 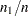 and
and 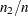 are fixed,
are fixed, 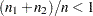 , and the chain is stationary, then the following statistic converges to a standard normal distribution as
, and the chain is stationary, then the following statistic converges to a standard normal distribution as  :
:
 |
This is a two-sided test, and large absolute  -scores indicate rejection.
-scores indicate rejection.
Spectral Density Estimate at Zero Frequency
For one sequence of the Markov chain  , the relationship between the
, the relationship between the  -lag covariance sequence of a time series and the spectral density,
-lag covariance sequence of a time series and the spectral density, 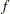 , is
, is
 |
where i indicates that 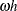 is the complex argument. Inverting this Fourier integral,
is the complex argument. Inverting this Fourier integral,
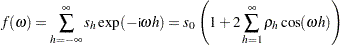 |
It follows that
 |
which gives an autocorrelation adjusted estimate of the variance. In this equation, 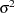 is the naive variance estimate of the sequence
is the naive variance estimate of the sequence 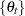 and
and 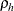 is the lag autocorrelation. Due to obvious computational difficulties, such as calculation of autocorrelation at infinity, you cannot effectively estimate
is the lag autocorrelation. Due to obvious computational difficulties, such as calculation of autocorrelation at infinity, you cannot effectively estimate 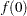 by using the preceding formula. The usual route is to first obtain the periodogram
by using the preceding formula. The usual route is to first obtain the periodogram 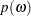 of the sequence, and then estimate by smoothing the estimated periodogram. The periodogram is defined to be
of the sequence, and then estimate by smoothing the estimated periodogram. The periodogram is defined to be
 |
The procedures use the following way to estimate 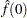 from
from 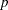 (Heidelberger and Welch; 1981). In , let
(Heidelberger and Welch; 1981). In , let  and
and 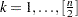 .1 A smooth spectral density in the domain of
.1 A smooth spectral density in the domain of 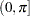 is obtained by fitting a gamma model with the log link function, using
is obtained by fitting a gamma model with the log link function, using 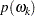 as response and
as response and  as the only regressor. The predicted value is given by
as the only regressor. The predicted value is given by
 |
where 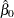 and
and  are the estimates of the intercept and slope parameters, respectively.
are the estimates of the intercept and slope parameters, respectively.
Heidelberger and Welch Diagnostics
The Heidelberger and Welch test (Heidelberger and Welch; 1981, 1983) consists of two parts: a stationary portion test and a half-width test. The stationarity test assesses the stationarity of a Markov chain by testing the hypothesis that the chain comes from a covariance stationary process. The half-width test checks whether the Markov chain sample size is adequate to estimate the mean values accurately.
Given 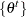 , set
, set  ,
, 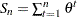 , and
, and 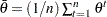 . You can construct the following sequence with
. You can construct the following sequence with  coordinates on values from
coordinates on values from 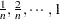 :
:
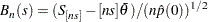 |
where  is the rounding operator, and
is the rounding operator, and 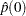 is an estimate of the spectral density at zero frequency that uses the second half of the sequence (see the section Spectral Density Estimate at Zero Frequency for estimation details). For large ,
is an estimate of the spectral density at zero frequency that uses the second half of the sequence (see the section Spectral Density Estimate at Zero Frequency for estimation details). For large , 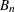 converges in distribution to a Brownian bridge (Billingsley; 1986). So you can construct a test statistic by using . The statistic used in these procedures is the Cramer–von Mises statistic2; that is
converges in distribution to a Brownian bridge (Billingsley; 1986). So you can construct a test statistic by using . The statistic used in these procedures is the Cramer–von Mises statistic2; that is  . As , the statistic converges in distribution to a standard Cramer–von Mises distribution. The integral
. As , the statistic converges in distribution to a standard Cramer–von Mises distribution. The integral 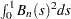 is numerically approximated using Simpson’s rule.
is numerically approximated using Simpson’s rule.
Let 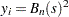 , where
, where 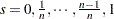 , and
, and 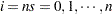 . If is even, let
. If is even, let 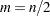 ; otherwise, let
; otherwise, let 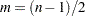 . The Simpson’s approximation to the integral is
. The Simpson’s approximation to the integral is
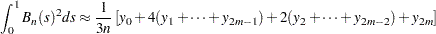 |
Note that Simpson’s rule requires an even number of intervals. When is odd, 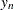 is set to be 0 and the value does not contribute to the approximation.
is set to be 0 and the value does not contribute to the approximation.
This test can be performed repeatedly on the same chain, and it helps you identify a time when the chain has reached stationarity. The whole chain, , is first used to construct the Cramer–von Mises statistic. If it passes the test, you can conclude that the entire chain is stationary. If it fails the test, you drop the initial 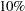 of the chain and redo the test by using the remaining
of the chain and redo the test by using the remaining 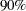 . This process is repeated until either a time is selected or it reaches a point where there are not enough data remaining to construct a confidence interval (the cutoff proportion is set to be
. This process is repeated until either a time is selected or it reaches a point where there are not enough data remaining to construct a confidence interval (the cutoff proportion is set to be  ).
).
The part of the chain that is deemed stationary is put through a half-width test, which reports whether the sample size is adequate to meet certain accuracy requirements for the mean estimates. Running the simulation less than this length of time would not meet the requirement, while running it longer would not provide any additional information that is needed. The statistic calculated here is the relative half-width (RHW) of the confidence interval. The RHW for a confidence interval of level  is
is
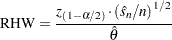 |
where 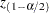 is the -score of the
is the -score of the 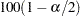 th percentile (for example,
th percentile (for example, 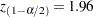 if
if 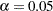 ),
), 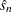 is the variance of the chain estimated using the spectral density method (see explanation in the section Spectral Density Estimate at Zero Frequency), is the length, and
is the variance of the chain estimated using the spectral density method (see explanation in the section Spectral Density Estimate at Zero Frequency), is the length, and 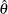 is the estimated mean. The RHW quantifies accuracy of the level confidence interval of the mean estimate by measuring the ratio between the sample standard error of the mean and the mean itself. In other words, you can stop the Markov chain if the variability of the mean stabilizes with respect to the mean. An implicit assumption is that large means are often accompanied by large variances. If this assumption is not met, then this test can produce false rejections (such as a small mean around 0 and large standard deviation) or false acceptance (such as a very large mean with relative small variance). As with any other convergence diagnostics, you might want to exercise caution in interpreting the results.
is the estimated mean. The RHW quantifies accuracy of the level confidence interval of the mean estimate by measuring the ratio between the sample standard error of the mean and the mean itself. In other words, you can stop the Markov chain if the variability of the mean stabilizes with respect to the mean. An implicit assumption is that large means are often accompanied by large variances. If this assumption is not met, then this test can produce false rejections (such as a small mean around 0 and large standard deviation) or false acceptance (such as a very large mean with relative small variance). As with any other convergence diagnostics, you might want to exercise caution in interpreting the results.
The stationarity test is one-sided; rejection occurs when the -value is greater than . To perform the half-width test, you need to select an  level (the default of which is
level (the default of which is  ) and a predetermined tolerance value
) and a predetermined tolerance value  (the default of which is
(the default of which is 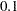 ). If the calculated RHW is greater than , you conclude that there are not enough data to accurately estimate the mean with confidence under tolerance of .
). If the calculated RHW is greater than , you conclude that there are not enough data to accurately estimate the mean with confidence under tolerance of .
Raftery and Lewis Diagnostics
If your interest lies in posterior percentiles, you want a diagnostic test that evaluates the accuracy of the estimated percentiles. The Raftery-Lewis test (Raftery and Lewis; 1992, 1996) is designed for this purpose. Notation and deductions here closely resemble those in Raftery and Lewis (1996).
Suppose you are interested in a quantity 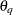 such that
such that 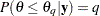 , where
, where 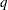 can be an arbitrary cumulative probability, such as
can be an arbitrary cumulative probability, such as 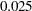 . This can be empirically estimated by finding the
. This can be empirically estimated by finding the 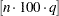 th number of the sorted
th number of the sorted 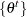 . Let
. Let  denote the estimand, which corresponds to an estimated probability
denote the estimand, which corresponds to an estimated probability 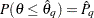 . Because the simulated posterior distribution converges to the true distribution as the simulation sample size grows, can achieve any degree of accuracy if the simulator is run for a very long time. However, running too long a simulation can be wasteful. Alternatively, you can use coverage probability to measure accuracy and stop the chain when a certain accuracy is reached.
. Because the simulated posterior distribution converges to the true distribution as the simulation sample size grows, can achieve any degree of accuracy if the simulator is run for a very long time. However, running too long a simulation can be wasteful. Alternatively, you can use coverage probability to measure accuracy and stop the chain when a certain accuracy is reached.
A stopping criterion is reached when the estimated probability is within 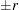 of the true cumulative probability , with probability , such as
of the true cumulative probability , with probability , such as  . For example, suppose you want the coverage probability to be
. For example, suppose you want the coverage probability to be 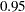 and the amount of tolerance
and the amount of tolerance  to be
to be 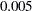 . This corresponds to requiring that the estimate of the cumulative distribution function of the
. This corresponds to requiring that the estimate of the cumulative distribution function of the 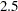 th percentile be estimated to within
th percentile be estimated to within 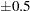 percentage points with probability .
percentage points with probability .
The Raftery-Lewis diagnostics test finds the number of iterations, , that need to be discarded (burn-ins) and the number of iterations needed, 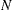 , to achieve a desired precision. Given a predefined cumulative probability , these procedures first find , and then they construct a binary
, to achieve a desired precision. Given a predefined cumulative probability , these procedures first find , and then they construct a binary  process
process 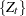 by setting
by setting  if
if 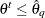 and
and 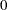 otherwise for all . The sequence is itself not a Markov chain, but you can construct a subsequence of that is approximately Markovian if it is sufficiently
otherwise for all . The sequence is itself not a Markov chain, but you can construct a subsequence of that is approximately Markovian if it is sufficiently 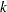 -thinned. When becomes reasonably large,
-thinned. When becomes reasonably large, 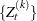 starts to behave like a Markov chain.
starts to behave like a Markov chain.
Next, the procedures find this thinning parameter . The number is estimated by comparing the Bayesian information criterion (BIC) between two Markov models: a first-order and a second-order Markov model. A 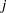 th-order Markov model is one in which the current value of depends on the previous values. For example, in a second-order Markov model,
th-order Markov model is one in which the current value of depends on the previous values. For example, in a second-order Markov model,
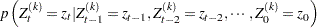 |
|||||
|
|
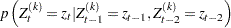 |
|||
where 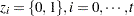 . Given
. Given 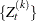 , you can construct two transition count matrices for a second-order Markov model:
, you can construct two transition count matrices for a second-order Markov model:
|
|
|||||
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
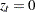
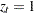

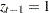
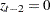
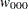
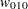
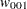
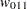
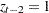
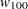
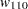
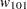
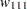
For each , the procedures calculate the BIC that compares the two Markov models. The BIC is based on a likelihood ratio test statistic that is defined as
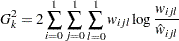 |
where 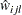 is the expected cell count of
is the expected cell count of 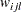 under the null model, the first-order Markov model, where the assumption
under the null model, the first-order Markov model, where the assumption  holds. The formula for the expected cell count is
holds. The formula for the expected cell count is
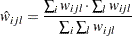 |
The BIC is 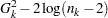 , where
, where 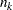 is the -thinned sample size (every th sample starting with the first), with the last two data points discarded due to the construction of the second-order Markov model. The thinning parameter is the smallest for which the BIC is negative. When is found, you can estimate a transition probability matrix between state 0 and state 1 for :
is the -thinned sample size (every th sample starting with the first), with the last two data points discarded due to the construction of the second-order Markov model. The thinning parameter is the smallest for which the BIC is negative. When is found, you can estimate a transition probability matrix between state 0 and state 1 for :
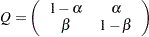 |
Because is a Markov chain, its equilibrium distribution exists and is estimated by
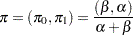 |
where 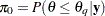 and
and  . The goal is to find an iteration number
. The goal is to find an iteration number  such that after steps, the estimated transition probability
such that after steps, the estimated transition probability 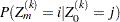 is within of equilibrium
is within of equilibrium 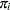 for
for  . Let
. Let 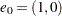 and
and 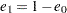 . The estimated transition probability after step is
. The estimated transition probability after step is
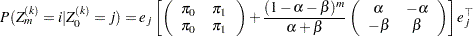 |
which holds when
 |
assuming  .
.
Therefore, by time , 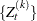 is sufficiently close to its equilibrium distribution, and you know that a total size of
is sufficiently close to its equilibrium distribution, and you know that a total size of 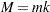 should be discarded as the burn-in.
should be discarded as the burn-in.
Next, the procedures estimate , the number of simulations needed to achieve desired accuracy on percentile estimation. The estimate of 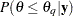 is
is 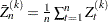 . For large ,
. For large , 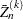 is normally distributed with mean , the true cumulative probability, and variance
is normally distributed with mean , the true cumulative probability, and variance
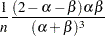 |
 is satisfied if
is satisfied if
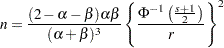 |
Therefore, 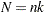 .
.
By using similar reasoning, the procedures first calculate the minimal number of iterations needed to achieve the desired accuracy, assuming the samples are independent:
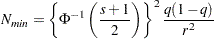 |
If does not have that required sample size, the Raftery-Lewis test is not carried out. If you still want to carry out the test, increase the number of Markov chain iterations.
The ratio 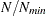 is sometimes referred to as the dependence factor. It measures deviation from posterior sample independence: the closer it is to 1, the less correlated are the samples. There are a few things to keep in mind when you use this test. This diagnostic tool is specifically designed for the percentile of interest and does not provide information about convergence of the chain as a whole (Brooks and Roberts; 1999). In addition, the test can be very sensitive to small changes. Both and
is sometimes referred to as the dependence factor. It measures deviation from posterior sample independence: the closer it is to 1, the less correlated are the samples. There are a few things to keep in mind when you use this test. This diagnostic tool is specifically designed for the percentile of interest and does not provide information about convergence of the chain as a whole (Brooks and Roberts; 1999). In addition, the test can be very sensitive to small changes. Both and 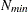 are inversely proportional to
are inversely proportional to  , so you can expect to see large variations in these numbers with small changes to input variables, such as the desired coverage probability or the cumulative probability of interest. Last, the time until convergence for a parameter can differ substantially for different cumulative probabilities.
, so you can expect to see large variations in these numbers with small changes to input variables, such as the desired coverage probability or the cumulative probability of interest. Last, the time until convergence for a parameter can differ substantially for different cumulative probabilities.
Autocorrelations
The sample autocorrelation of lag is defined in terms of the sample autocovariance function:
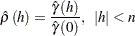 |
The sample autocovariance function of lag (of 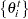 ) is defined by
) is defined by
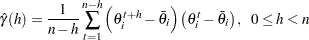 |
Effective Sample Size
You can use autocorrelation and trace plots to examine the mixing of a Markov chain. A closely related measure of mixing is the effective sample size (ESS) (Kass et al.; 1998).
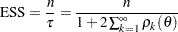 |
where is the total sample size and 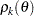 is the autocorrelation of lag for . The quantity
is the autocorrelation of lag for . The quantity  is referred to as the autocorrelation time. To estimate , the Bayesian procedures first find a cutoff point after which the autocorrelations are very close to zero, and then sum all the
is referred to as the autocorrelation time. To estimate , the Bayesian procedures first find a cutoff point after which the autocorrelations are very close to zero, and then sum all the 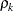 up to that point. The cutoff point is such that
up to that point. The cutoff point is such that 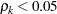 or
or 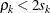 , where
, where 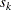 is the estimated standard deviation:
is the estimated standard deviation:
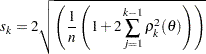 |
ESS and are inversely proportional to each other, and low ESS or high indicates bad mixing of the Markov chain.
Footnotes
-
This is equivalent to the fast Fourier transformation of the original time series
 .
.
-
The von Mises distribution was first introduced by von Mises (1918). The density function is
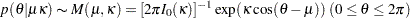 , where the function
, where the function 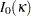 is the modified Bessel function of the first kind and order zero, defined by
is the modified Bessel function of the first kind and order zero, defined by  .
.
Copyright © SAS Institute, Inc. All Rights Reserved.