| The GLIMMIX Procedure |
Example 38.3 Smoothing Disease Rates; Standardized Mortality Ratios
Clayton and Kaldor (1987, Table 1) present data on observed and expected cases of lip cancer in the 56 counties of Scotland between 1975 and 1980. The expected number of cases was determined by a separate multiplicative model that accounted for the age distribution in the counties. The goal of the analysis is to estimate the county-specific log-relative risks, also known as standardized mortality ratios (SMR).
If 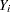 is the number of incident cases in county
is the number of incident cases in county 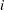 and
and 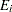 is the expected number of incident cases, then the ratio of observed to expected counts,
is the expected number of incident cases, then the ratio of observed to expected counts, 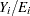 , is the standardized mortality ratio. Clayton and Kaldor (1987) assume there exists a relative risk
, is the standardized mortality ratio. Clayton and Kaldor (1987) assume there exists a relative risk 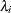 that is specific to each county and is a random variable. Conditional on , the observed counts are independent Poisson variables with mean
that is specific to each county and is a random variable. Conditional on , the observed counts are independent Poisson variables with mean  .
.
An elementary mixed model for specifies only a random intercept for each county, in addition to a fixed intercept. Breslow and Clayton (1993), in their analysis of these data, also provide a covariate that measures the percentage of employees in agriculture, fishing, and forestry. The expanded model for the region-specific relative risk in Breslow and Clayton (1993) is
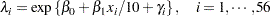 |
where 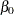 and
and 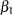 are fixed effects, and the
are fixed effects, and the 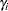 are county random effects.
are county random effects.
The following DATA step creates the data set lipcancer. The expected number of cases is based on the observed standardized mortality ratio for counties with lip cancer cases, and based on the expected counts reported by Clayton and Kaldor (1987, Table 1) for the counties without cases. The sum of the expected counts then equals the sum of the observed counts.
data lipcancer; input county observed expected employment SMR; if (observed > 0) then expCount = 100*observed/SMR; else expCount = expected; datalines; 1 9 1.4 16 652.2 2 39 8.7 16 450.3 3 11 3.0 10 361.8 4 9 2.5 24 355.7 5 15 4.3 10 352.1 6 8 2.4 24 333.3 7 26 8.1 10 320.6 8 7 2.3 7 304.3 9 6 2.0 7 303.0 10 20 6.6 16 301.7 11 13 4.4 7 295.5 12 5 1.8 16 279.3 13 3 1.1 10 277.8 14 8 3.3 24 241.7 15 17 7.8 7 216.8 16 9 4.6 16 197.8 17 2 1.1 10 186.9 18 7 4.2 7 167.5 19 9 5.5 7 162.7 20 7 4.4 10 157.7 21 16 10.5 7 153.0 22 31 22.7 16 136.7 23 11 8.8 10 125.4 24 7 5.6 7 124.6 25 19 15.5 1 122.8 26 15 12.5 1 120.1 27 7 6.0 7 115.9 28 10 9.0 7 111.6 29 16 14.4 10 111.3 30 11 10.2 10 107.8 31 5 4.8 7 105.3 32 3 2.9 24 104.2 33 7 7.0 10 99.6 34 8 8.5 7 93.8 35 11 12.3 7 89.3 36 9 10.1 0 89.1 37 11 12.7 10 86.8 38 8 9.4 1 85.6 39 6 7.2 16 83.3 40 4 5.3 0 75.9 41 10 18.8 1 53.3 42 8 15.8 16 50.7 43 2 4.3 16 46.3 44 6 14.6 0 41.0 45 19 50.7 1 37.5 46 3 8.2 7 36.6 47 2 5.6 1 35.8 48 3 9.3 1 32.1 49 28 88.7 0 31.6 50 6 19.6 1 30.6 51 1 3.4 1 29.1 52 1 3.6 0 27.6 53 1 5.7 1 17.4 54 1 7.0 1 14.2 55 0 4.2 16 0.0 56 0 1.8 10 0.0 ;
Because the mean of the Poisson variates, conditional on the random effects, is 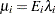 , applying a log link yields
, applying a log link yields
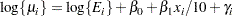 |
The term 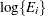 is an offset, a regressor variable whose coefficient is known to be one. Note that it is assumed that the are known; they are not treated as random variables.
is an offset, a regressor variable whose coefficient is known to be one. Note that it is assumed that the are known; they are not treated as random variables.
The following statements fit this model by residual pseudo-likelihood:
proc glimmix data=lipcancer;
class county;
x = employment / 10;
logn = log(expCount);
model observed = x / dist=poisson offset=logn
solution ddfm=none;
random county;
SMR_pred = 100*exp(_zgamma_ + _xbeta_);
id employment SMR SMR_pred;
output out=glimmixout;
run;
The offset is created with the assignment statement
logn = log(expCount);
and is associated with the linear predictor through the OFFSET= option in the MODEL statement. The statement
x = employment / 10;
transforms the covariate measuring percentage of employment in agriculture, fisheries, and forestry to agree with the analysis of Breslow and Clayton (1993). The DDFM=NONE option in the MODEL statement requests chi-square tests and  tests instead of the default
tests instead of the default 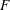 tests and
tests and  tests by setting the denominator degrees of freedom in tests of fixed effects to
tests by setting the denominator degrees of freedom in tests of fixed effects to  .
.
The statement
SMR_pred = 100*exp(_zgamma_ + _xbeta_);
calculates the fitted standardized mortality rate. Note that the offset variable does not contribute to the exponentiated term.
The OUTPUT statement saves results of the calculations to the output data set glimmixout. The ID statement specifies that only the listed variables are written to the output data set.
| Model Information | |
|---|---|
| Data Set | WORK.LIPCANCER |
| Response Variable | observed |
| Response Distribution | Poisson |
| Link Function | Log |
| Variance Function | Default |
| Offset Variable | logn = log(expCount); |
| Variance Matrix | Not blocked |
| Estimation Technique | Residual PL |
| Degrees of Freedom Method | None |
The GLIMMIX procedure displays in the "Model Information" table that the offset variable was computed with programming statements and the final assignment statement from your GLIMMIX statements (Output 38.3.1). There are two columns in the 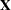 matrix, corresponding to the intercept and the regressor
matrix, corresponding to the intercept and the regressor  . There are 56 columns in the
. There are 56 columns in the 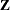 matrix, however, one for each observation in the data set (Output 38.3.1).
matrix, however, one for each observation in the data set (Output 38.3.1).
The optimization involves only a single covariance parameter, the variance of the county effect (Output 38.3.2). Because this parameter is a variance, the GLIMMIX procedure imposes a lower boundary constraint; the solution for the variance is bounded by zero from below.
Following the initial creation of pseudo-data and the fit of a linear mixed model, the procedure goes through five more updates of the pseudo-data, each associated with a separate optimization (Output 38.3.3). Although the objective function in each optimization is the negative of twice the restricted maximum likelihood for that pseudo-data, there is no guarantee that across the outer iterations the objective function decreases in subsequent optimizations. In this example, minus twice the residual maximum likelihood at convergence takes on its smallest value at the initial optimization and increases in subsequent optimizations.
| Iteration History | |||||
|---|---|---|---|---|---|
| Iteration | Restarts | Subiterations | Objective Function |
Change | Max Gradient |
| 0 | 0 | 4 | 123.64113992 | 0.20997891 | 3.848E-8 |
| 1 | 0 | 3 | 127.05866018 | 0.03393332 | 0.000048 |
| 2 | 0 | 2 | 127.48839749 | 0.00223427 | 5.753E-6 |
| 3 | 0 | 1 | 127.50502469 | 0.00006946 | 1.938E-7 |
| 4 | 0 | 1 | 127.50528068 | 0.00000118 | 1.09E-7 |
| 5 | 0 | 0 | 127.50528481 | 0.00000000 | 1.299E-6 |
The "Covariance Parameter Estimates" table in Output 38.3.4 shows the estimate of the variance of the region-specific log-relative risks. There is significant county-to-county heterogeneity in risks. If the covariate were removed from the analysis, as in Clayton and Kaldor (1987), the heterogeneity in county-specific risks would increase. (The fitted SMRs in Table 6 of Breslow and Clayton (1993) were obtained without the covariate  in the model.)
in the model.)
The "Solutions for Fixed Effects" table displays the estimates of and along with their standard errors and test statistics (Output 38.3.5). Because of the DDFM=NONE option in the MODEL statement, PROC GLIMMIX assumes that the degrees of freedom for the tests of 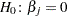 are infinite. The
are infinite. The  -values correspond to probabilities under a standard normal distribution. The covariate measuring employment percentages in agriculture, fisheries, and forestry is significant. This covariate might be a surrogate for the exposure to sunlight, an important risk factor for lip cancer.
-values correspond to probabilities under a standard normal distribution. The covariate measuring employment percentages in agriculture, fisheries, and forestry is significant. This covariate might be a surrogate for the exposure to sunlight, an important risk factor for lip cancer.
You can examine the quality of the fit of this model with various residual plots. A panel of studentized residuals is requested with the following statements:
ods graphics on; ods select StudentPanel; proc glimmix data=lipcancer plots=studentpanel; class county; x = employment / 10; logn = log(expCount); model observed = x / dist=poisson offset=logn s ddfm=none; random county; run; ods graphics off;
The graph in the upper-left corner of the panel displays studentized residuals plotted against the linear predictor (Output 38.3.6). The default of the GLIMMIX procedure is to use the estimated BLUPs in the construction of the residuals and to present them on the linear scale, which in this case is the logarithmic scale. You can change the type of the computed residual with the TYPE= suboptions of each paneled display. For example, the option PLOTS=STUDENTPANEL(TYPE=NOBLUP) would request a paneled display of the marginal residuals on the linear scale.
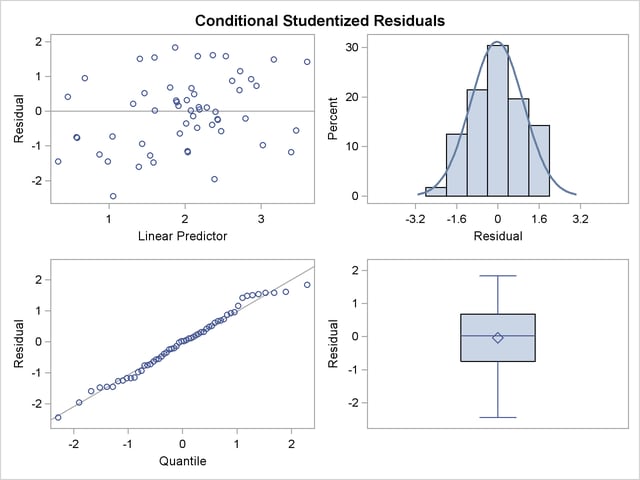
The graph in the upper-right corner of the panel shows a histogram with overlaid normal density. A Q-Q plot and a box plot are shown in the lower cells of the panel.
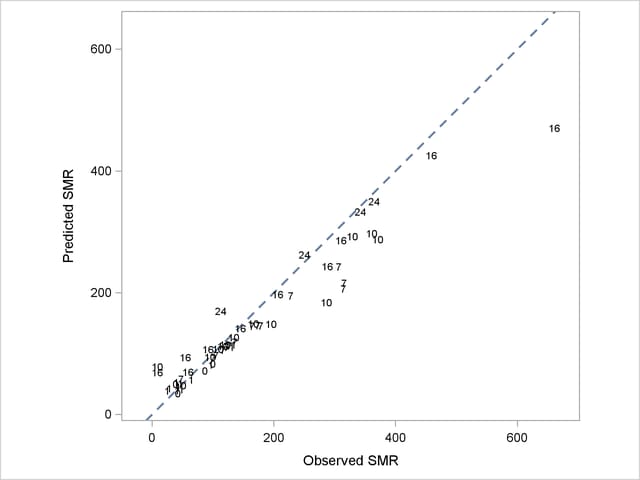
The following statements produce a graph of the observed and predicted standardized mortality ratios (Output 38.3.7):
proc template;
define statgraph scatter;
BeginGraph;
layout overlayequated / yaxisopts=(label='Predicted SMR')
xaxisopts=(label='Observed SMR')
equatetype=square;
lineparm y=0 slope=1 x=0 /
lineattrs = GraphFit(pattern=dash)
extend = true;
scatterplot y=SMR_pred x=SMR /
markercharacter = employment;
endlayout;
EndGraph;
end;
run;
proc sgrender data=glimmixout template=scatter;
run;
In Output 38.3.7, fitted SMRs tend to be larger than the observed SMRs for counties with small observed SMR and smaller than the observed SMRs for counties with high observed SMR.
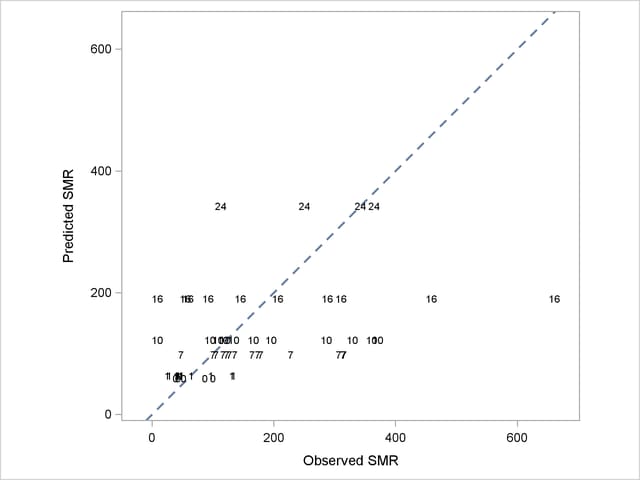
To demonstrate the impact of the random effects adjustment to the log-relative risks, the following statements fit a Poisson regression model (a GLM) by maximum likelihood:
proc glimmix data=lipcancer;
x = employment / 10;
logn = log(expCount);
model observed = x / dist=poisson offset=logn
solution ddfm=none;
SMR_pred = 100*exp(_zgamma_ + _xbeta_);
id employment SMR SMR_pred;
output out=glimmixout;
run;
The GLIMMIX procedure defaults to maximum likelihood estimation because these statements fit a generalized linear model with nonnormal distribution. As a consequence, the SMRs are county specific only to the extent that the risks vary with the value of the covariate. But risks are no longer adjusted based on county-to-county heterogeneity in the observed incidence count.
Because of the absence of random effects, the GLIMMIX procedure recognizes the model as a generalized linear model and fits it by maximum likelihood (Output 38.3.8). The variance matrix is diagonal because the observations are uncorrelated.
The "Dimensions" table shows that there are no G-side random effects in this model and no R-side scale parameter either (Output 38.3.9).
Because this is a GLM, the GLIMMIX procedure defaults to the Newton-Raphson algorithm, and the fixed effects (intercept and slope) comprise the parameters in the optimization (Output 38.3.10). (The default optimization technique for a GLM is the Newton-Raphson method.)
The estimates of and have changed from the previous analysis. In the GLMM, the estimates were  and
and  (Output 38.3.11).
(Output 38.3.11).
More importantly, without the county-specific adjustments through the best linear unbiased predictors of the random effects, the predicted SMRs are the same for all counties with the same percentage of employees in agriculture, fisheries, and forestry (Output 38.3.12).
Copyright © SAS Institute, Inc. All Rights Reserved.