| The GLIMMIX Procedure |
Example 38.1 Binomial Counts in Randomized Blocks
In the context of spatial prediction in generalized linear models, Gotway and Stroup (1997) analyze data from an agronomic field trial. Researchers studied 16 varieties (entries) of wheat for their resistance to infestation by the Hessian fly. They arranged the varieties in a randomized complete block design on an 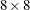 grid. Each
grid. Each 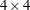 quadrant of that arrangement constitutes a block.
quadrant of that arrangement constitutes a block.
The outcome of interest was the number of damaged plants (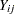 ) out of the total number of plants growing on the unit (
) out of the total number of plants growing on the unit (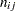 ). The two subscripts identify the block (
). The two subscripts identify the block (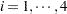 ) and the entry (
) and the entry (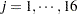 ). The following SAS statements create the data set. The variables lat and lng denote the coordinate of an experimental unit on the grid.
). The following SAS statements create the data set. The variables lat and lng denote the coordinate of an experimental unit on the grid.
data HessianFly;
label Y = 'No. of damaged plants'
n = 'No. of plants';
input block entry lat lng n Y @@;
datalines;
1 14 1 1 8 2 1 16 1 2 9 1
1 7 1 3 13 9 1 6 1 4 9 9
1 13 2 1 9 2 1 15 2 2 14 7
1 8 2 3 8 6 1 5 2 4 11 8
1 11 3 1 12 7 1 12 3 2 11 8
1 2 3 3 10 8 1 3 3 4 12 5
1 10 4 1 9 7 1 9 4 2 15 8
1 4 4 3 19 6 1 1 4 4 8 7
2 15 5 1 15 6 2 3 5 2 11 9
2 10 5 3 12 5 2 2 5 4 9 9
2 11 6 1 20 10 2 7 6 2 10 8
2 14 6 3 12 4 2 6 6 4 10 7
2 5 7 1 8 8 2 13 7 2 6 0
2 12 7 3 9 2 2 16 7 4 9 0
2 9 8 1 14 9 2 1 8 2 13 12
2 8 8 3 12 3 2 4 8 4 14 7
3 7 1 5 7 7 3 13 1 6 7 0
3 8 1 7 13 3 3 14 1 8 9 0
3 4 2 5 15 11 3 10 2 6 9 7
3 3 2 7 15 11 3 9 2 8 13 5
3 6 3 5 16 9 3 1 3 6 8 8
3 15 3 7 7 0 3 12 3 8 12 8
3 11 4 5 8 1 3 16 4 6 15 1
3 5 4 7 12 7 3 2 4 8 16 12
4 9 5 5 15 8 4 4 5 6 10 6
4 12 5 7 13 5 4 1 5 8 15 9
4 15 6 5 17 6 4 6 6 6 8 2
4 14 6 7 12 5 4 7 6 8 15 8
4 13 7 5 13 2 4 8 7 6 13 9
4 3 7 7 9 9 4 10 7 8 6 6
4 2 8 5 12 8 4 11 8 6 9 7
4 5 8 7 11 10 4 16 8 8 15 7
;
Analysis as a GLM
If infestations are independent among experimental units, and all plants within a unit have the same propensity for infestation, then the are binomial random variables. The first model considered is a standard generalized linear model for independent binomial counts:
proc glimmix data=HessianFly; class block entry; model y/n = block entry / solution; run;
The PROC GLIMMIX statement invokes the procedure. The CLASS statement instructs the GLIMMIX procedure to treat both block and entry as classification variables. The MODEL statement specifies the response variable and the fixed effects in the model. PROC GLIMMIX constructs the 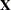 matrix of the model from the terms on the right side of the MODEL statement. The GLIMMIX procedure supports two kinds of syntax for the response variable. This example uses the events/trials syntax. The variable y represents the number of successes (events) out of n Bernoulli trials. When the events/trials syntax is used, the GLIMMIX procedure automatically selects the binomial distribution as the response distribution. Once the distribution is determined, the procedure selects the link function for the model. The default link for binomial data is the logit link. The preceding statements are thus equivalent to the following statements:
matrix of the model from the terms on the right side of the MODEL statement. The GLIMMIX procedure supports two kinds of syntax for the response variable. This example uses the events/trials syntax. The variable y represents the number of successes (events) out of n Bernoulli trials. When the events/trials syntax is used, the GLIMMIX procedure automatically selects the binomial distribution as the response distribution. Once the distribution is determined, the procedure selects the link function for the model. The default link for binomial data is the logit link. The preceding statements are thus equivalent to the following statements:
proc glimmix data=HessianFly; class block entry; model y/n = block entry / dist=binomial link=logit solution; run;
The SOLUTION option in the MODEL statement requests that solutions for the fixed effects (parameter estimates) be displayed.
The "Model Information" table describes the model and methods used in fitting the statistical model (Output 38.1.1).
The GLIMMIX procedure recognizes that this is a model for uncorrelated data (variance matrix is diagonal) and that parameters can be estimated by maximum likelihood. The default degrees-of-freedom method to denominator degrees of freedom for F tests and t tests is the RESIDUAL method. This corresponds to choosing 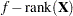 as the degrees of freedom, where
as the degrees of freedom, where 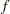 is the sum of the frequencies used in the analysis. You can change the degrees of freedom method with the DDFM= option in the MODEL statement.
is the sum of the frequencies used in the analysis. You can change the degrees of freedom method with the DDFM= option in the MODEL statement.
The "Class Level Information" table lists the levels of the variables specified in the CLASS statement and the ordering of the levels (Output 38.1.2). The "Number of Observations" table displays the number of observations read and used in the analysis.
The "Dimensions" table lists the size of relevant matrices (Output 38.1.3).
Because of the absence of G-side random effects in this model, there are no columns in the 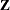 matrix. The 21 columns in the matrix comprise the intercept, 4 columns for the block effect and 16 columns for the entry effect. Because no RANDOM statement with a SUBJECT= option was specified, the GLIMMIX procedure does not process the data by subjects (see the section Processing by Subjects for details about subject processing).
matrix. The 21 columns in the matrix comprise the intercept, 4 columns for the block effect and 16 columns for the entry effect. Because no RANDOM statement with a SUBJECT= option was specified, the GLIMMIX procedure does not process the data by subjects (see the section Processing by Subjects for details about subject processing).
The "Optimization Information" table provides information about the methods and size of the optimization problem (Output 38.1.4).
With few exceptions, models fit with the GLIMMIX procedure require numerical methods for parameter estimation. The default optimization method for (overdispersed) GLM models is the Newton-Raphson algorithm. In this example, the optimization involves 19 parameters, corresponding to the number of linearly independent columns of the 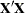 matrix.
matrix.
The "Iteration History" table shows that the procedure converged after 3 iterations and 13 function evaluations (Output 38.1.5). The Change column measures the change in the objective function between iterations; however, this is not the monitored convergence criterion. The GLIMMIX procedure monitors several features simultaneously to determine whether to stop an optimization.
The "Fit Statistics" table lists information about the fitted model (Output 38.1.6). The  2 Log Likelihood values are useful for comparing nested models, and the information criteria AIC, AICC, BIC, CAIC, and HQIC are useful for comparing nonnested models. On average, the ratio between the Pearson statistic and its degrees of freedom should equal one in GLMs. Values larger than one indicate overdispersion. With a ratio of 2.37, these data appear to exhibit more dispersion than expected under a binomial model with block and varietal effects.
2 Log Likelihood values are useful for comparing nested models, and the information criteria AIC, AICC, BIC, CAIC, and HQIC are useful for comparing nonnested models. On average, the ratio between the Pearson statistic and its degrees of freedom should equal one in GLMs. Values larger than one indicate overdispersion. With a ratio of 2.37, these data appear to exhibit more dispersion than expected under a binomial model with block and varietal effects.
The "Parameter Estimates" table displays the maximum likelihood estimates (Estimate), standard errors, and t tests for the hypothesis that the estimate is zero (Output 38.1.7).
| Parameter Estimates | |||||||
|---|---|---|---|---|---|---|---|
| Effect | block | entry | Estimate | Standard Error | DF | t Value | Pr > |t| |
| Intercept | -1.2936 | 0.3908 | 45 | -3.31 | 0.0018 | ||
| block | 1 | -0.05776 | 0.2332 | 45 | -0.25 | 0.8055 | |
| block | 2 | -0.1838 | 0.2303 | 45 | -0.80 | 0.4289 | |
| block | 3 | -0.4420 | 0.2328 | 45 | -1.90 | 0.0640 | |
| block | 4 | 0 | . | . | . | . | |
| entry | 1 | 2.9509 | 0.5397 | 45 | 5.47 | <.0001 | |
| entry | 2 | 2.8098 | 0.5158 | 45 | 5.45 | <.0001 | |
| entry | 3 | 2.4608 | 0.4956 | 45 | 4.97 | <.0001 | |
| entry | 4 | 1.5404 | 0.4564 | 45 | 3.38 | 0.0015 | |
| entry | 5 | 2.7784 | 0.5293 | 45 | 5.25 | <.0001 | |
| entry | 6 | 2.0403 | 0.4889 | 45 | 4.17 | 0.0001 | |
| entry | 7 | 2.3253 | 0.4966 | 45 | 4.68 | <.0001 | |
| entry | 8 | 1.3006 | 0.4754 | 45 | 2.74 | 0.0089 | |
| entry | 9 | 1.5605 | 0.4569 | 45 | 3.42 | 0.0014 | |
| entry | 10 | 2.3058 | 0.5203 | 45 | 4.43 | <.0001 | |
| entry | 11 | 1.4957 | 0.4710 | 45 | 3.18 | 0.0027 | |
| entry | 12 | 1.5068 | 0.4767 | 45 | 3.16 | 0.0028 | |
| entry | 13 | -0.6296 | 0.6488 | 45 | -0.97 | 0.3370 | |
| entry | 14 | 0.4460 | 0.5126 | 45 | 0.87 | 0.3889 | |
| entry | 15 | 0.8342 | 0.4698 | 45 | 1.78 | 0.0826 | |
| entry | 16 | 0 | . | . | . | . | |
The "Type III Tests of Fixed Effect" table displays significance tests for the two fixed effects in the model (Output 38.1.8).
These tests are Wald-type tests, not likelihood ratio tests. The entry effect is clearly significant in this model with a 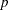 -value of <0.0001, indicating that the 16 wheat varieties are not equally susceptible to infestation by the Hessian fly.
-value of <0.0001, indicating that the 16 wheat varieties are not equally susceptible to infestation by the Hessian fly.
Analysis with Random Block Effects
There are several possible reasons for the overdispersion noted in Output 38.1.6 (Pearson ratio = 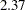 ). The data might not follow a binomial distribution, one or more important effects might not have been accounted for in the model, or the data might be positively correlated. If important fixed effects have been omitted, then you might need to consider adding them to the model. Because this is a designed experiment, it is reasonable not to expect further effects apart from the block and entry effects that represent the treatment and error control design structure. The reasons for the overdispersion must lie elsewhere.
). The data might not follow a binomial distribution, one or more important effects might not have been accounted for in the model, or the data might be positively correlated. If important fixed effects have been omitted, then you might need to consider adding them to the model. Because this is a designed experiment, it is reasonable not to expect further effects apart from the block and entry effects that represent the treatment and error control design structure. The reasons for the overdispersion must lie elsewhere.
If overdispersion stems from correlations among the observations, then the model should be appropriately adjusted. The correlation can have multiple sources. First, it might not be the case that the plants within an experimental unit responded independently. If the probability of infestation of a particular plant is altered by the infestation of a neighboring plant within the same unit, the infestation counts are not binomial and a different probability model should be used. A second possible source of correlations is the lack of independence of experimental units. Even if treatments were assigned to units at random, they might not respond independently. Shared spatial soil effects, for example, can be the underlying factor. The following analyses take these spatial effects into account.
First, assume that the environmental effects operate at the scale of the blocks. By making the block effects random, the marginal responses will be correlated due to the fact that observations within a block share the same random effects. Observations from different blocks will remain uncorrelated, in the spirit of separate randomizations among the blocks. The next set of statements fits a generalized linear mixed model (GLMM) with random block effects:
proc glimmix data=HessianFly; class block entry; model y/n = entry / solution; random block; run;
Because the conditional distribution—conditional on the block effects—is binomial, the marginal distribution will be overdispersed relative to the binomial distribution. In contrast to adding a multiplicative scale parameter to the variance function, treating the block effects as random changes the estimates compared to a model with fixed block effects.
In the presence of random effects and a conditional binomial distribution, PROC GLIMMIX does not use maximum likelihood for estimation. Instead, the GLIMMIX procedure applies a restricted (residual) pseudo-likelihood algorithm (Output 38.1.9). The "restricted" attribute derives from the same rationale by which restricted (residual) maximum likelihood methods for linear mixed models attain their name; the likelihood equations are adjusted for the presence of fixed effects in the model to reduce bias in covariance parameter estimates.
The "Class Level Information" and "Number of Observations" tables are as before (Output 38.1.10).
The "Dimensions" table indicates that there is a single G-side parameter, the variance of the random block effect (Output 38.1.11). The "Dimensions" table has changed from the previous model (compare Output 38.1.11 to Output 38.1.3). Note that although the block effect has four levels, only a single variance component is estimated. The matrix has four columns, however, corresponding to the four levels of the block effect. Because no SUBJECT= option is used in the RANDOM statement, the GLIMMIX procedure treats these data as having arisen from a single subject with 64 observations.
The "Optimization Information" table indicates that a quasi-Newton method is used to solve the optimization problem. This is the default optimization method for GLMM models (Output 38.1.12).
In contrast to the Newton-Raphson method, the quasi-Newton method does not require second derivatives. Because the covariance parameters are not unbounded in this example, the procedure enforces a lower boundary constraint (zero) for the variance of the block effect, and the optimization method is changed to a dual quasi-Newton method. The fixed effects are profiled from the likelihood equations in this model. The resulting optimization problem involves only the covariance parameters.
The "Iteration History" table appears to indicate that the procedure converged after four iterations (Output 38.1.13). Notice, however, that this table has changed slightly from the previous analysis (see Output 38.1.5). The Evaluations column has been replaced by the Subiterations column, because the GLIMMIX procedure applied a doubly iterative fitting algorithm. The entire process consisted of five optimizations, each of which was iterative. The initial optimization required four iterations, the next one required three iterations, and so on.
The "Fit Statistics" table shows information about the fit of the GLMM (Output 38.1.14). The log likelihood reported in the table is not the residual log likelihood of the data. It is the residual log likelihood for an approximated model. The generalized chi-square statistic measures the residual sum of squares in the final model, and the ratio with its degrees of freedom is a measure of variability of the observation about the mean model.
The variance of the random block effects is rather small (Output 38.1.15).
If the environmental effects operate on a spatial scale smaller than the block size, the random block model does not provide a suitable adjustment. From the coarse layout of the experimental area, it is not surprising that random block effects alone do not account for the overdispersion in the data. Adding a random component to a generalized linear model is different from adding a multiplicative overdispersion component, for example, via the PSCALE option in PROC GENMOD or a
random _residual_;
statement in PROC GLIMMIX. Such overdispersion components do not affect the parameter estimates, only their standard errors. A genuine random effect, on the other hand, affects both the parameter estimates and their standard errors (compare Output 38.1.16 to Output 38.1.7).
| Solutions for Fixed Effects | ||||||
|---|---|---|---|---|---|---|
| Effect | entry | Estimate | Standard Error | DF | t Value | Pr > |t| |
| Intercept | -1.4637 | 0.3738 | 3 | -3.92 | 0.0296 | |
| entry | 1 | 2.9609 | 0.5384 | 45 | 5.50 | <.0001 |
| entry | 2 | 2.7807 | 0.5138 | 45 | 5.41 | <.0001 |
| entry | 3 | 2.4339 | 0.4934 | 45 | 4.93 | <.0001 |
| entry | 4 | 1.5347 | 0.4542 | 45 | 3.38 | 0.0015 |
| entry | 5 | 2.7653 | 0.5276 | 45 | 5.24 | <.0001 |
| entry | 6 | 2.0014 | 0.4865 | 45 | 4.11 | 0.0002 |
| entry | 7 | 2.3518 | 0.4952 | 45 | 4.75 | <.0001 |
| entry | 8 | 1.2927 | 0.4739 | 45 | 2.73 | 0.0091 |
| entry | 9 | 1.5663 | 0.4554 | 45 | 3.44 | 0.0013 |
| entry | 10 | 2.2896 | 0.5179 | 45 | 4.42 | <.0001 |
| entry | 11 | 1.5018 | 0.4682 | 45 | 3.21 | 0.0025 |
| entry | 12 | 1.5075 | 0.4752 | 45 | 3.17 | 0.0027 |
| entry | 13 | -0.5955 | 0.6475 | 45 | -0.92 | 0.3626 |
| entry | 14 | 0.4573 | 0.5111 | 45 | 0.89 | 0.3758 |
| entry | 15 | 0.8683 | 0.4682 | 45 | 1.85 | 0.0702 |
| entry | 16 | 0 | . | . | . | . |
Because the block variance component is small, the Type III test for the variety effect in Output 38.1.17 is affected only very little compared to the GLM (Output 38.1.8).
Analysis with Smooth Spatial Trends
You can also consider these data in an observational sense, where the covariation of the observations is subject to modeling. Rather than deriving model components from the experimental design alone, environmental effects can be modeled by adjusting the mean and/or correlation structure. Gotway and Stroup (1997) and Schabenberger and Pierce (2002) supplant the coarse block effects with smooth-scale spatial components.
The model considered by Gotway and Stroup (1997) is a marginal model in that the correlation structure is modeled through residual-side (R-side) random components. This exponential covariance model is fit with the following statements:
proc glimmix data=HessianFly; class entry; model y/n = entry / solution ddfm=contain; random _residual_ / subject=intercept type=sp(exp)(lng lat); run;
Note that the block effects have been removed from the statements. The keyword _RESIDUAL_ in the RANDOM statement instructs the GLIMMIX procedure to model the 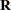 matrix. Here, is to be modeled as an exponential covariance structure matrix. The SUBJECT=INTERCEPT option means that all observations are considered correlated. Because the random effects are residual-type (R-side) effects, there are no columns in the
matrix. Here, is to be modeled as an exponential covariance structure matrix. The SUBJECT=INTERCEPT option means that all observations are considered correlated. Because the random effects are residual-type (R-side) effects, there are no columns in the 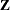 matrix for this model (Output 38.1.18).
matrix for this model (Output 38.1.18).
In addition to the fixed effects, the GLIMMIX procedure now profiles one of the covariance parameters, the variance of the exponential covariance model (Output 38.1.19). This reduces the size of the optimization problem. Only a single parameter is part of the optimization, the "range" (SP(EXP)) of the spatial process.
The practical range of a spatial process is that distance at which the correlation between data points has decreased to at most 0.05. The parameter reported by the GLIMMIX procedure as SP(EXP) in Output 38.1.20 corresponds to one-third of the practical range. The practical range in this process is 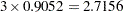 . Correlations extend beyond a single experimental unit, but they do not appear to exist on the scale of the block size.
. Correlations extend beyond a single experimental unit, but they do not appear to exist on the scale of the block size.
The sill of the spatial process, the variance of the underlying residual effect, is estimated as 2.5315.
The F value for the entry effect has been sharply reduced compared to the previous analyses. The smooth spatial variation accounts for some of the variation among the varieties (Output 38.1.21).
In this example three models were considered for the analysis of a randomized block design with binomial outcomes. If data are correlated, a standard generalized linear model often will indicate overdispersion relative to the binomial distribution. Two courses of action are considered in this example to address this overdispersion. First, the inclusion of G-side random effects models the correlation indirectly; it is induced through the sharing of random effects among responses from the same block. Second, the R-side spatial covariance structure models covariation directly. In generalized linear (mixed) models these two modeling approaches can lead to different inferences, because the models have different interpretation. The random block effects are modeled on the linked (logit) scale, and the spatial effects were modeled on the mean scale. Only in a linear mixed model are the two scales identical.
Copyright © SAS Institute, Inc. All Rights Reserved.