BOXCHART Statement: ANOM Procedure

Creating ANOM Boxcharts from Response Values
Note: See Creating ANOM BOXCHARTS from Response Values in the SAS/QC Sample Library.
A manufacturing engineer carries out a study to determine the source of excessive variation in the positioning of labels on shampoo bottles.[2] A labeling machine removes bottles from the line, attaches the labels, and returns the bottles to the line. There are six positions on the machine, and the engineer suspects that one or more of the position heads might be faulty.
A sample of 60 bottles, 10 per position, is run through the machine. For each bottle, the deviation of each label is measured
in millimeters, and the machine position is recorded. The following statements create a SAS data set named LabelDeviations, which contains the deviation measurements for the 60 bottles:
data LabelDeviations;
input Position @;
do i = 1 to 5;
input Deviation @;
output;
end;
drop i;
datalines;
1 -0.02386 -0.02853 -0.03001 -0.00428 -0.03623
1 -0.04222 -0.00144 -0.06466 0.00944 -0.00163
2 -0.02014 -0.02725 0.02268 -0.03323 0.03661
2 0.04378 0.05562 0.00977 0.05641 0.01816
3 -0.00728 0.02849 -0.04404 -0.02214 -0.01394
3 0.04855 0.03566 0.02345 0.01339 -0.00203
4 0.06694 0.10729 0.05974 0.06089 0.07551
4 0.03620 0.05614 0.08985 0.04175 0.05298
5 0.03677 0.00361 0.03736 0.01164 -0.00741
5 0.02495 -0.00803 0.03021 -0.00149 -0.04640
6 0.00493 -0.03839 -0.02037 -0.00487 -0.01202
6 0.00710 -0.03075 0.00167 -0.02845 -0.00697
;
A partial listing of LabelDeviations is shown in Figure 4.2.
Figure 4.2: Listing of the Data Set LabelDeviations
The data set LabelDeviations is said to be in "strung-out" form, because each observation contains the position and the deviation measurement for a single
bottle. The first 10 observations contain the measurements for the first position, the second 10 observations contain the
measurements for the second position, and so on. Because the variable Position classifies the observations into groups (treatment levels), it is referred to as the group-variable. The variable Deviation contains the deviation measurements and is referred to as the response variable (or response for short).
The following statements create the ANOM boxchart shown in Figure 4.3:
ods graphics on;
title 'Analysis of Label Deviations';
proc anom data=LabelDeviations;
boxchart Deviation*Position / alpha = 0.05
odstitle = title;
label Deviation = 'Mean Deviation from Center (mm)';
label Position = 'Labeler Position';
run;
The ODS GRAPHICS ON statement specified before the PROC ANOM statement enables ODS Graphics, so the boxchart is created by
using ODS Graphics instead of traditional graphics. This example illustrates the basic form of the BOXCHART statement. After
the keyword BOXCHART, you specify the response to analyze (in this case, Deviation) followed by an asterisk and the group-variable (Position). Options are specified after the slash (/) in the BOXCHART statement. A complete list of options is presented in the section
Syntax: BOXCHART Statement.
The input data set is specified with the DATA= option in the PROC ANOM statement when it contains raw measurements for the response.
Each point on the ANOM chart represents the average (mean) of the response measurements for a particular sample.
Figure 4.3: ANOM Chart for Means of Labeler Position Data
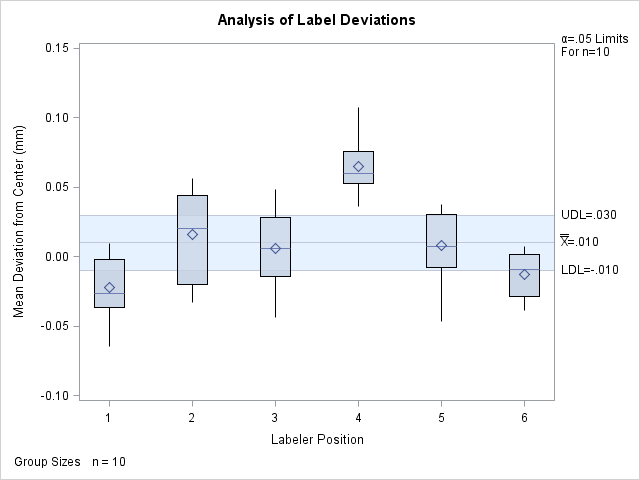
The average for Position 1 is below the lower decision limit (LDL), and the average for Position 6 is slightly below the lower decision limit. The average for Position 4 exceeds the upper decision limit (UDL). The conclusion is that Positions 1, 4, and 6 are operating differently.
By default, the decision limits shown correspond to a significance level of 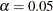 ; the formulas for the limits are given in the section Decision Limits. You can also read decision limits from an input data set.
; the formulas for the limits are given in the section Decision Limits. You can also read decision limits from an input data set.
For computational details, see Constructing ANOM Boxcharts. For details on reading raw measurements, see DATA= Data Set.