| The UNIVARIATE Procedure |
| INSET Statement |
- INSET keywords </ options> ;
An INSET statement places a box or table of summary statistics, called an inset, directly in a graph created with a CDFPLOT, HISTOGRAM, PPPLOT, PROBPLOT, or QQPLOT statement. The INSET statement must follow the plot statement that creates the plot that you want to augment. The inset appears in all the graphs that the preceding plot statement produces.
You can use multiple INSET statements after a plot statement to add more than one inset to a plot. See Example 4.17.
In an INSET statement, you specify one or more keywords that identify the information to display in the inset. The information is displayed in the order that you request the keywords. Keywords can be any of the following:
statistical keywords
primary keywords
secondary keywords
The available statistical keywords are listed in Table 4.25 through Table 4.29.
Keyword |
Description |
|---|---|
CSS |
corrected sum of squares |
CV |
coefficient of variation |
KURTOSIS |
kurtosis |
MAX |
largest value |
MEAN |
sample mean |
MIN |
smallest value |
MODE |
most frequent value |
N |
sample size |
NEXCL |
number of observations excluded by MAXNBIN= or MAXSIGMAS= option |
NMISS |
number of missing values |
NOBS |
number of observations |
RANGE |
range |
SKEWNESS |
skewness |
STD |
standard deviation |
STDMEAN |
standard error of the mean |
SUM |
sum of the observations |
SUMWGT |
sum of the weights |
USS |
uncorrected sum of squares |
VAR |
variance |
Keyword |
Description |
|---|---|
P1 |
1st percentile |
P5 |
5th percentile |
P10 |
10th percentile |
Q1 |
lower quartile (25th percentile) |
MEDIAN |
median (50th percentile) |
Q3 |
upper quartile (75th percentile) |
P90 |
90th percentile |
P95 |
95th percentile |
P99 |
99th percentile |
QRANGE |
interquartile range (Q3 - Q1) |
Keyword |
Description |
|---|---|
GINI |
Gini’s mean difference |
MAD |
median absolute difference about the median |
QN |
|
SN |
|
STD_GINI |
Gini’s standard deviation |
STD_MAD |
MAD standard deviation |
STD_QN |
|
STD_QRANGE |
interquartile range standard deviation |
STD_SN |
|
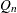 , alternative to MAD
, alternative to MAD 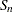 , alternative to MAD
, alternative to MAD Keyword |
Description |
|---|---|
MSIGN |
sign statistic |
NORMALTEST |
test statistic for normality |
PNORMAL |
probability value for the test of normality |
SIGNRANK |
signed rank statistic |
PROBM |
probability of greater absolute value for the sign statistic |
PROBN |
probability value for the test of normality |
PROBS |
probability value for the signed rank test |
PROBT |
probability value for the Student’s |
T |
statistics for Student’s |
 test
test Keyword |
Description |
|---|---|
DATA= |
(label, value) pairs from input data set |
To create a completely customized inset, use a DATA= data set.
- DATA=SAS-data-set
requests that PROC UNIVARIATE display customized statistics from a SAS data set in the inset table. The data set must contain two variables:
- _LABEL_
a character variable whose values provide labels for inset entries
- _VALUE_
a variable that is either character or numeric and whose values provide values for inset entries
The label and value from each observation in the data set occupy one line in the inset. The position of the DATA= keyword in the keyword list determines the position of its lines in the inset.
A primary keyword enables you to specify secondary keywords in parentheses immediately after the primary keyword. Primary keywords are BETA, EXPONENTIAL, GAMMA, KERNEL, KERNEL , LOGNORMAL, NORMAL, SB, SU, WEIBULL, and WEIBULL2. If you specify a primary keyword but omit a secondary keyword, the inset displays a colored line and the distribution name as a key for the density curve.
, LOGNORMAL, NORMAL, SB, SU, WEIBULL, and WEIBULL2. If you specify a primary keyword but omit a secondary keyword, the inset displays a colored line and the distribution name as a key for the density curve.
By default, PROC UNIVARIATE identifies inset statistics with appropriate labels and prints numeric values with appropriate formats. To customize the label, specify the keyword followed by an equal sign (=) and the desired label in quotes. To customize the format, specify a numeric format in parentheses after the keyword. Labels can have up to 24 characters. If you specify both a label and a format for a statistic, the label must appear before the format. For example,
inset n='Sample Size' std='Std Dev' (5.2);
requests customized labels for two statistics and displays the standard deviation with a field width of 5 and two decimal places.
Table 4.30 and Table 4.31 list primary keywords.
Keyword |
Distribution |
Plot Statement Availability |
|---|---|---|
BETA |
beta |
all plot statements |
EXPONENTIAL |
exponential |
all plot statements |
GAMMA |
gamma |
all plot statements |
LOGNORMAL |
lognormal |
all plot statements |
NORMAL |
normal |
all plot statements |
SB |
Johnson |
HISTOGRAM |
SU |
Johnson |
HISTOGRAM |
WEIBULL |
Weibull(3-parameter) |
all plot statements |
WEIBULL2 |
Weibull(2-parameter) |
PROBPLOT and QQPLOT |
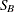
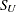
Keyword |
Description |
|---|---|
KERNEL |
displays statistics for all kernel estimates |
KERNEL |
displays statistics for only the |
|
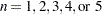
Table 4.32 through Table 4.41 list the secondary keywords available with primary keywords in Table 4.30 and Table 4.31.
Secondary Keyword |
Alias |
Description |
|---|---|---|
ALPHA |
SHAPE1 |
first shape parameter |
BETA |
SHAPE2 |
second shape parameter |
MEAN |
mean of the fitted distribution |
|
SIGMA |
SCALE |
scale parameter |
STD |
standard deviation of the fitted distribution |
|
THETA |
THRESHOLD |
lower threshold parameter |


Secondary Keyword |
Alias |
Description |
|---|---|---|
MEAN |
mean of the fitted distribution |
|
SIGMA |
SCALE |
scale parameter |
STD |
standard deviation of the fitted distribution |
|
THETA |
THRESHOLD |
threshold parameter |
Secondary Keyword |
Alias |
Description |
|---|---|---|
ALPHA |
SHAPE |
shape parameter |
MEAN |
mean of the fitted distribution |
|
SIGMA |
SCALE |
scale parameter |
STD |
standard deviation of the fitted distribution |
|
THETA |
THRESHOLD |
threshold parameter |
Secondary Keyword |
Alias |
Description |
|---|---|---|
MEAN |
mean of the fitted distribution |
|
SIGMA |
SHAPE |
shape parameter |
STD |
standard deviation of the fitted distribution |
|
THETA |
THRESHOLD |
threshold parameter |
ZETA |
SCALE |
scale parameter |
Secondary Keyword |
Alias |
Description |
|---|---|---|
MU |
MEAN |
mean parameter |
SIGMA |
STD |
scale parameter |
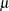
Secondary Keyword |
Alias |
Description |
|---|---|---|
DELTA |
SHAPE1 |
first shape parameter |
GAMMA |
SHAPE2 |
second shape parameter |
MEAN |
mean of the fitted distribution |
|
SIGMA |
SCALE |
scale parameter |
STD |
standard deviation of the fitted distribution |
|
THETA |
THRESHOLD |
lower threshold parameter |
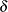
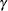
Secondary Keyword |
Alias |
Description |
|---|---|---|
C |
SHAPE |
shape parameter |
MEAN |
mean of the fitted distribution |
|
SIGMA |
SCALE |
scale parameter |
STD |
standard deviation of the fitted distribution |
|
THETA |
THRESHOLD |
threshold parameter |

Secondary Keyword |
Alias |
Description |
|---|---|---|
C |
SHAPE |
shape parameter |
MEAN |
mean of the fitted distribution |
|
SIGMA |
SCALE |
scale parameter |
STD |
standard deviation of the fitted distribution |
|
THETA |
THRESHOLD |
known lower threshold |

Secondary Keyword |
Description |
|---|---|
AMISE |
approximate mean integrated square error (MISE) for the kernel density |
BANDWIDTH |
bandwidth |
BWIDTH |
alias for BANDWIDTH |
C |
standardized bandwidth |
|
|
|
|
TYPE |
kernel type: normal, quadratic, or triangular |
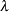 for the density estimate
for the density estimate  where
where  sample size,
sample size, 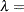 bandwidth, and
bandwidth, and  interquartile range
interquartile range Secondary Keyword |
Description |
|---|---|
AD |
Anderson-Darling EDF test statistic |
ADPVAL |
Anderson-Darling EDF test |
CVM |
Cramér-von Mises EDF test statistic |
CVMPVAL |
Cramér-von Mises EDF test |
KSD |
Kolmogorov-Smirnov EDF test statistic |
KSDPVAL |
Kolmogorov-Smirnov EDF test |
The inset statistics listed in Table 4.30 through Table 4.41 are not available unless you request a plot statement and options that calculate these statistics. For example, consider the following statements:
proc univariate data=score;
histogram final / normal;
inset mean std normal(ad adpval);
run;
The MEAN and STD keywords display the sample mean and standard deviation of final. The NORMAL keyword with the secondary keywords AD and ADPVAL display the Anderson-Darling goodness-of-fit test statistic and 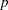 -value. The statistics that are specified with the NORMAL keyword are available only because the NORMAL option is requested in the HISTOGRAM statement.
-value. The statistics that are specified with the NORMAL keyword are available only because the NORMAL option is requested in the HISTOGRAM statement.
The KERNEL or KERNEL keyword is available only if you request a kernel density estimate in a HISTOGRAM statement. The WEIBULL2 keyword is available only if you request a two-parameter Weibull distribution in the PROBPLOT or QQPLOT statement.
If you specify multiple kernel density estimates, you can request inset statistics for all the estimates with the KERNEL keyword. Alternatively, you can display inset statistics for individual curves with the KERNEL keyword, where is the curve number between 1 and 5.
Summary of Options
Table 4.42 lists INSET statement options, which are specified after the slash (/) in the INSET statement. For complete descriptions, see the section Dictionary of Options.
Option |
Description |
|---|---|
specifies color of inset background |
|
specifies color of header background |
|
specifies color of frame |
|
specifies color of header text |
|
specifies color of drop shadow |
|
specifies color of inset text |
|
specifies data units for POSITION= |
|
specifies font of text |
|
specifies format of values in inset |
|
specifies header text |
|
specifies height of inset text |
|
suppresses frame around inset |
|
specifies position of inset |
|
specifies reference point of inset positioned with POSITION= |
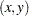 coordinates
coordinates Dictionary of Options
The following entries provide detailed descriptions of options for the INSET statement.
- CFILL=color | BLANK
specifies the color of the background for traditional graphics. If you omit the CFILLH= option the header background is included. By default, the background is empty, which causes items that overlap the inset (such as curves or histogram bars) to show through the inset.
If you specify a value for CFILL= option, then overlapping items no longer show through the inset. Use CFILL=BLANK to leave the background uncolored and to prevent items from showing through the inset.
- CFILLH=color
specifies the color of the header background for traditional graphics. The default value is the CFILL= color.
- CFRAME=color
specifies the color of the frame for traditional graphics. The default value is the same color as the axis of the plot.
- CHEADER=color
specifies the color of the header text for traditional graphics. The default value is the CTEXT= color.
- CSHADOW=color
specifies the color of the drop shadow for traditional graphics. By default, if a CSHADOW= option is not specified, a drop shadow is not displayed.
- CTEXT=color
specifies the color of the text for traditional graphics. The default value is the same color as the other text on the plot.
- DATA
specifies that data coordinates are to be used in positioning the inset with the POSITION= option. The DATA option is available only when you specify POSITION=(x,y). You must place DATA immediately after the coordinates (x,y). Note:Positioning insets with coordinates is not supported for ODS Graphics output.
- FONT=font
specifies the font of the text for traditional graphics. By default, if you locate the inset in the interior of the plot, then the font is SIMPLEX. If you locate the inset in the exterior of the plot, then the font is the same as the other text on the plot.
- FORMAT=format
specifies a format for all the values in the inset. If you specify a format for a particular statistic, then this format overrides FORMAT= format. For more information about SAS formats, see SAS Language Reference: Dictionary
- HEADER=string
specifies the header text. The string cannot exceed 40 characters. By default, no header line appears in the inset. If all the keywords that you list in the INSET statement are secondary keywords that correspond to a fitted curve on a histogram, PROC UNIVARIATE displays a default header that indicates the distribution and identifies the curve.
- HEIGHT=value
specifies the height of the text for traditional graphics.
- NOFRAME
suppresses the frame drawn around the text.
- POSITION=position
- POS=position
determines the position of the inset. The position is a compass point keyword, a margin keyword, or a pair of coordinates (x,y). You can specify coordinates in axis percent units or axis data units. The default value is NW, which positions the inset in the upper left (northwest) corner of the display. See the section Positioning Insets.
Note:Positioning insets with coordinates is not supported for ODS Graphics output.
- REFPOINT=BR | BL | TR | TL
specifies the reference point for an inset that PROC UNIVARIATE positions by a pair of coordinates with the POSITION= option. The REFPOINT= option specifies which corner of the inset frame that you want to position at coordinates (x,y). The keywords are BL, BR, TL, and TR, which correspond to bottom left, bottom right, top left, and top right. The default value is BL. You must use REFPOINT= with POSITION=(x,y) coordinates. The option does not apply to ODS Graphics output.
Copyright © SAS Institute, Inc. All Rights Reserved.