DATASETS Procedure
- Syntax
 Procedure SyntaxPROC DATASETS StatementAGE StatementAPPEND StatementATTRIB StatementAUDIT StatementCHANGE StatementCONTENTS StatementCOPY StatementDELETE StatementEXCHANGE StatementEXCLUDE StatementFORMAT StatementIC CREATE StatementIC DELETE StatementIC REACTIVATE StatementINDEX CENTILES StatementINDEX CREATE StatementINDEX DELETE StatementINFORMAT StatementLABEL StatementMODIFY StatementREBUILD StatementRENAME StatementREPAIR StatementSAVE StatementSELECT Statement
Procedure SyntaxPROC DATASETS StatementAGE StatementAPPEND StatementATTRIB StatementAUDIT StatementCHANGE StatementCONTENTS StatementCOPY StatementDELETE StatementEXCHANGE StatementEXCLUDE StatementFORMAT StatementIC CREATE StatementIC DELETE StatementIC REACTIVATE StatementINDEX CENTILES StatementINDEX CREATE StatementINDEX DELETE StatementINFORMAT StatementLABEL StatementMODIFY StatementREBUILD StatementRENAME StatementREPAIR StatementSAVE StatementSELECT Statement - Overview
- Concepts
- Results
- Examples Removing All Labels and Formats in a Data SetManipulating SAS FilesSaving SAS Files from DeletionModifying SAS Data SetsDescribing a SAS Data SetConcatenating Two SAS Data SetsAging SAS Data SetsODS Output Getting Sort Indicator InformationUsing the ORDER= Option with the CONTENTS StatementInitiating an Audit File
Results: DATASETS Procedure
Directory Listing to the SAS Log
The PROC DATASETS statement
lists the SAS files in the procedure input library unless the NOLIST
option is specified. The NOLIST option prevents the creation of the
procedure results that go to the log. If you specify the MEMTYPE=
option, only specified types are listed. If you specify the DETAILS
option, PROC DATASETS prints these additional columns of information:
Obs,
Entries or Indexes, Vars,
and Label.
Directory Listing as SAS Output
The CONTENTS statement
lists the directory of the procedure input library if you use the
DIRECTORY option or specify DATA=_ALL_.
If you want only a directory,
use the NODS option and the _ALL_ keyword in the DATA= option. The
NODS option suppresses the description of the SAS data sets; only
the directory appears in the output.
Procedure Output
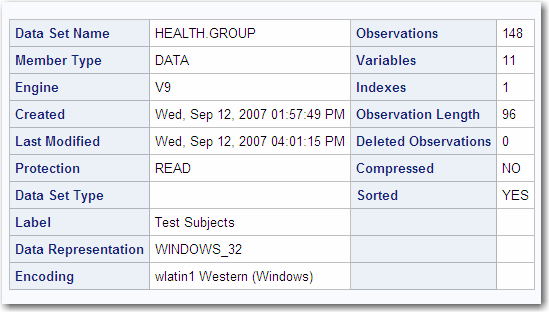
Data Set Attributes
Here are descriptions
of selected fields shown in the following output:
is the total number
of observations currently in the file. Note that for a very large
data set, if the number of observations exceeds the largest integer
value that can be represented in a double precision floating point
number, the count is shown as missing.
is the number of observations
marked for deletion. These observations are not included in the total
number of observations, shown in the
Observations field.
Note that for a very large data set, if the number of deleted observations
exceeds the number that can be stored in a double-precision integer,
the count is shown as missing. Also, the count for Deleted
Observations shows a missing value if you use the
COMPRESS=YES option with one or both of the REUSE=YES and POINTOBS=NO
options.
indicates whether the
data set is compressed. If the data set is compressed, the output
includes an additional item,
Reuse Space (with
a value of YES or NO). This item indicates whether to reuse space
that is made available when observations are deleted.
indicates whether the
data set is sorted. If you sort the data set with PROC SORT, PROC
SQL, or specify sort information with the SORTEDBY= data set option,
a value of YES appears here, and there is an additional section to
the output. See Sort Information for details.
is the format in which
data is represented on a computer architecture or in an operating
environment. For example, on an IBM PC, character data is represented
by its ASCII encoding and byte-swapped integers. Native data representation
refers to an environment for which the data representation compares
with the CPU that is accessing the file. For example, a file that
is in Windows data representation is native to the Windows operating
environment.
is the encoding value.
Encoding is a set of characters (letters, logograms, digits, punctuation,
symbols, control characters, and so on) that have been mapped to numeric
values (called code points) that can be used by computers. The code
points are assigned to the characters in the character set when you
apply an encoding method.
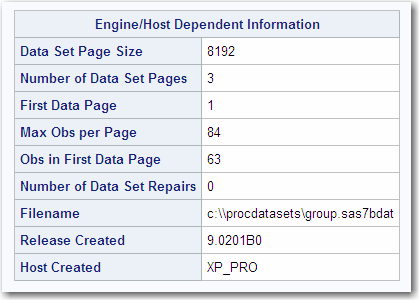
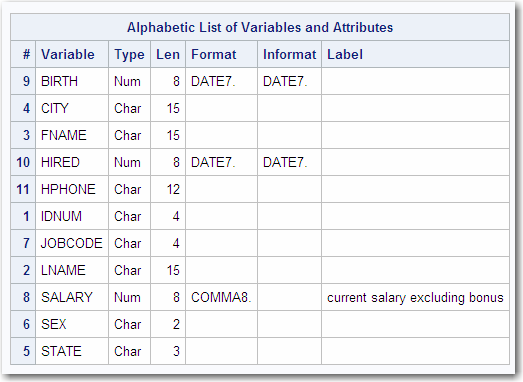
Alphabetic List of Variables and Attributes
Here are descriptions
of selected columns in the following output:
is the logical position
of each variable in the observation. This number is assigned to the
variable when the variable is defined.
specifies the variable's
length, which is the number of bytes used to store each of a variable's
values in a SAS data set.
specifies whether a
character variable is transcoded. If the attribute is NO, then transcoding
is suppressed. By default, character variables are transcoded when
required. For more information about transcoding, see SAS National Language Support (NLS): Reference Guide.
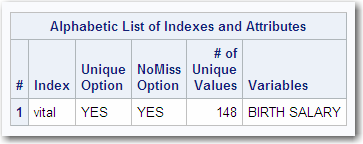
Alphabetic List of Indexes and Attributes
The section shown in
the following output appears only if the data set has indexes associated
with it.
displays the name of
each index. For simple indexes, the name of the index is the same
as a variable in the data set.
indicates whether the
index must have unique values. If the column contains YES, the combination
of values of the index variables is unique for each observation.
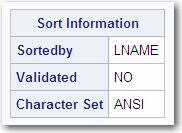
Sort Information
The section shown in
the following output appears only if the
Sorted field
has a value of YES.
indicates how the data
are currently sorted. This field contains either the variables and
options that you use in the BY statement in PROC SORT, the column
name in PROC SQL, or the values that you specify in the SORTEDBY=
option.
indicates whether the
data was sorted using PROC SORT or SORTEDBY. If PROC SORT or PROC
SQL sorted the data set, the value is YES. If you assigned the sort
indicator with the SORTEDBY= data set option, the value is NO.
is the character set
used to sort the data. The value for this field can be ASCII, EBCDIC,
or PASCII.
PROC DATASETS and the Output Delivery System (ODS)
Most SAS procedures
send their messages to the SAS log and their procedure results to
the output. PROC DATASETS is unique because it sends procedure results
to both the SAS log and the procedure output file. When the interface
to ODS was created, it was decided that all procedure results (from
both the log and the procedure output file) should be available to
ODS. In order to implement this feature and maintain compatibility
with earlier releases, the interface to ODS had to be slightly different
from the usual interface.
By default, the PROC
DATASETS statement itself produces two output objects: Members and
Directory. These objects are routed to the SAS log. The CONTENTS statement
produces three output objects by default: Attributes, EngineHost,
and Variables. (The use of various options adds other output objects.)
These objects are routed to the procedure output file. If you open
an ODS destination (such as HTML, RTF, or PRINTER), all of these objects
are, by default, routed to that destination.
You can use ODS SELECT
and ODS EXCLUDE statements to control which objects go to which destination,
just as you can for any other procedure. However, because of the unique
interface between PROC DATASETS and ODS, when you use the keyword
LISTING in an ODS SELECT or ODS EXCLUDE statement, you affect both
the log and the listing.
ODS Table Names
PROC DATASETS and PROC
CONTENTS assign a name to each table that they create. You can use
these names to reference the table when using the Output Delivery
System (ODS) to select tables and create output data sets.
Output Data Sets
The OUT= Data Set
The OUT= option in the
CONTENTS statement creates an output data set. Each variable in each
DATA= data set has one observation in the OUT= data set. Here are
the variables in the output data set:
the character set used
to sort the data set. The value is ASCII, EBCDIC, or PASCII. A blank
appears if the data set does not have a sort indicator stored with
it.
the collating sequence
used to sort the data set. A blank appears if the sort indicator
for the input data set does not include a collating sequence.
number of observations
marked for deletion in the data set. (Observations can be marked for
deletion but not actually deleted when you use the FSEDIT procedure
of SAS/FSP software.)
indicates whether the
variables in an SQL view are protected (
P)
or contribute (C) to a derived variable.
number of decimals
that you specify when you associate the format with the variable.
The value of FORMATD is 0 if you do not specify decimals in the format.
format length. If
you specify a length for the format when you associate the format
with a variable, the length that you specify is the value of FORMATL.
If you do not specify a length for the format when you associate
the format with a variable, the value of FORMATL is the default length
of the format if you use the FMTLEN option and 0 if you do not use
the FMTLEN option.
number of decimals
that you specify when you associate the informat with the variable.
The value is 0 if you do not specify decimals when you associate
the informat with the variable.
informat length. If
you specify a length for the informat when you associate the informat
with a variable, the length that you specify is the value of INFORML.
If you do not specify a length for the informat when you associate
the informat with a variable, the value of INFORML is the default
length of the informat if you use the FMTLEN option and 0 if you do
not use the FMTLEN option.
indicates whether the
space made available when observations are deleted from a compressed
data set should be reused. If the data set is not compressed, the
REUSE variable has a value of NO.
Note: The variable names are sorted
so that the values X1, X2, and X10 are listed in that order, not in
the true collating sequence of X1, X10, X2. Therefore, if you want
to use a BY statement on MEMNAME in subsequent steps, run a PROC SORT
step on the output data set first or use the NOTSORTED option in the
BY statement.
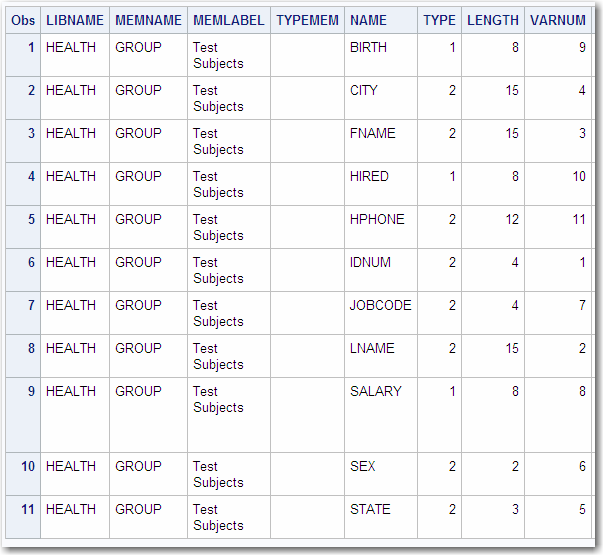
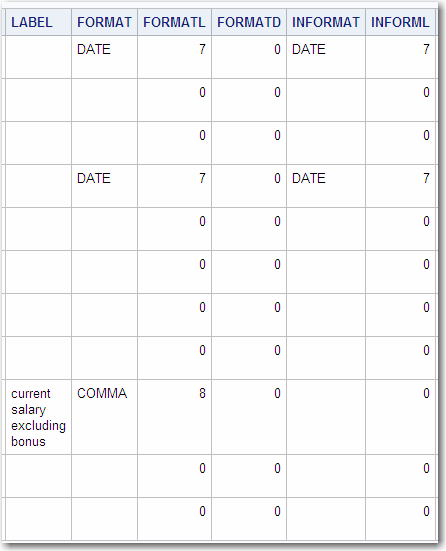
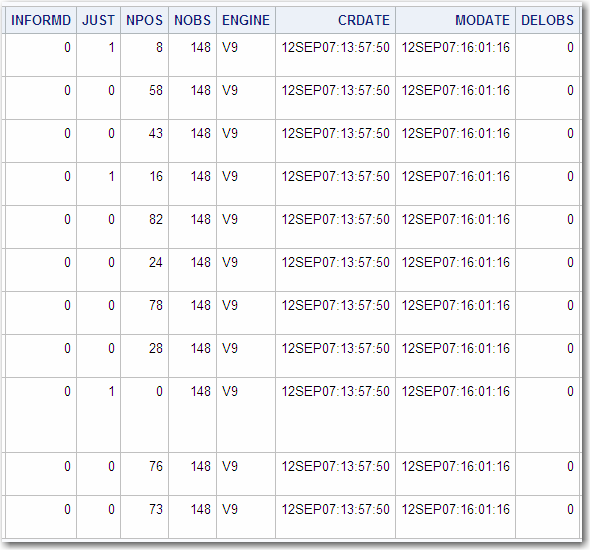
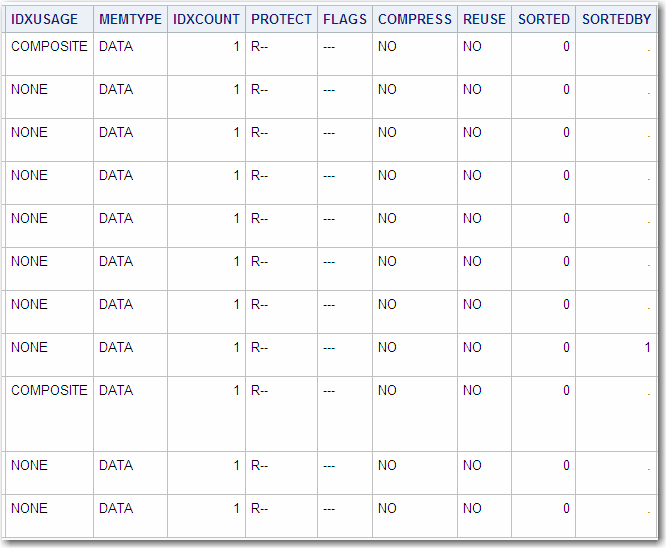
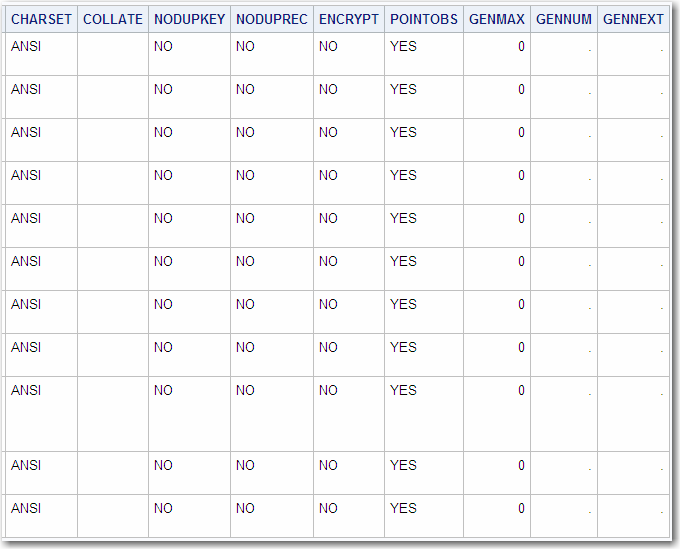
The following is an
example of an output data set created from the GROUP data set, which
is shown in Describing a SAS Data Set and in Procedure Output.
Note: For information about how
to get the CONTENTS output into an ODS data set for processing, see ODS Output .
The OUT2= Data Set
The OUT2= option in
the CONTENTS statement creates an output data set that contains information
about indexes and integrity constraints. Here are the variables in
the output data set:
for a foreign key integrity
constraint, contains RESTRICT or SET NULL if applicable (the ON DELETE
option in the IC CREATE statement).
for a foreign key integrity
constraint, contains RESTRICT or SET NULL if applicable (the ON UPDATE
option in the IC CREATE statement).
the type. For an index,
the value is “Index” while for an integrity constraint,
the value is the type of integrity constraint (Not Null, Check, Primary
Key, and so on).